可解释人工智能(XAI)方法被描绘为一种用于调试和信任统计和深度学习模型以及解释其预测的方法。然而,最近在对抗性机器学习方面的进步凸显出最先进解释的局限性和脆弱性,使其安全性和可信度受到质疑。操纵、愚弄或者"公平洗白"模型推理的证据的可能性在应用于高风险决策和知识发现时会带来严重的后果。这篇对50多篇论文的简明调查总结了关于机器学习模型解释的对抗性攻击以及公平性指标的研究。我们讨论如何防御攻击和设计鲁棒的解释方法。我们贡献了一份XAI中现有安全隐患的列表,并概述了对抗性XAI(AdvXAI)的新兴研究方向。
https://arxiv.org/abs/2306.06123
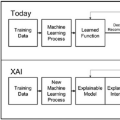
可解释人工智能(XAI)方法(如需简要概述请参见Holzinger et al., 2022,对于全面调查请参考Schwalbe和Finzel,2023),例如后期解释方法如PDP [Friedman, 2001],SG [Simonyan et al., 2014],LIME [Ribeiro et al., 2016],IG [Sundararajan et al., 2017],SHAP [Lundberg and Lee, 2017],TCAV [Kim et al., 2018],Grad-CAM [Selvaraju et al., 2020]等,提供了各种解释机器学习模型预测的机制。对XAI的一种普遍批评,尤其支持本质上可解释的模型,是其无法真实地解释黑箱模型 [Rudin, 2019]。然而,解释方法在自动驾驶 [Gu et al., 2020] 或药物发现 [Jimenez-Luna et al., 2020] 等应用中取得了成功,并可以用来更好地理解像AlphaZero [McGrath et al., 2022] 这样的大型模型的推理过程。
1. 引言
近年来,对抗性机器学习(AdvML,参考Kolter和Madry, 2018; Rosenberg et al., 2021; Machado et al., 2021)在XAI研究中变得更为普遍,然而,解释的脆弱性引发了对其可信度和安全性的担忧 [Papernot et al., 2018]。为了评估这些威胁的范围,我们对当前关于模型解释的对抗性攻击(第二部分)以及防御这些攻击的机制(第三部分)的知识状态进行了系统化的整理。图1展示了这样的攻击之一,通常被称为对抗性样本,即轻微改变的图像会极大地改变模型预测的类别的解释。用不同方法得到的解释的聚合显示出对这种操纵的抵抗力较强。
尽管大多数相关的综述总结了解释的鲁棒性 [Mishra et al., 2021],模型预测的攻击 [Machado et al., 2021],以及XAI在AdvML中的应用 [Liu et al., 2021],但这项调查强调了我们所称之为对抗性可解释人工智能(AdvXAI)的快速崛起的跨领域研究。我们还将其与关于机器学习公平性指标的对抗性攻击的密切相关工作进行了对比(第4节)。通过对50多篇论文的简洁概述,我们可以指出AdvXAI的前沿研究方向(第5节)。我们承认这并不是一项系统性的评审,而更像是一个接近的展望,以便识别可能的缺口并定义未来的方向。我们首先收录了自Ghorbani et al. [2019]以来在主要的机器学习会议(如ICML,ICLR,NeurIPS,AAAI)和期刊(如AIj,NMI)上发表的显著论文。然后,我们广泛地搜索了他们的引文网络,以找出在其他地方发表的与AdvXAI相关的论文。我们故意排除了大量主要关注解释评估而未涉及到对抗性情景的论文 [参见 Nauta et al., 2023]。
2 对模型解释的对抗性攻击
据我们所知,Ghorbani et al. [2019]是首次提及并提出对解释方法,特别是(卷积)神经网络的基于梯度的显著性图 [Simonyan et al., 2014; Sundararajan et al., 2017]进行对抗性攻击的贡献。之前的相关工作讨论了解释鲁棒性的最坏情况(对抗性)概念 [Alvarez Melis和Jaakkola,2018,第7页]以及解释敏感性的概念 [Ancona et al., 2018; Kindermans et al., 2019]。关键的是,Adebayo et al. [2018]引入了随机测试,显示仅通过解释的视觉检查可以偏好对人类有吸引力的方法。这引起了对评估解释质量的关注,特别是对于深度模型,可能在对抗性环境中有可能的影响。
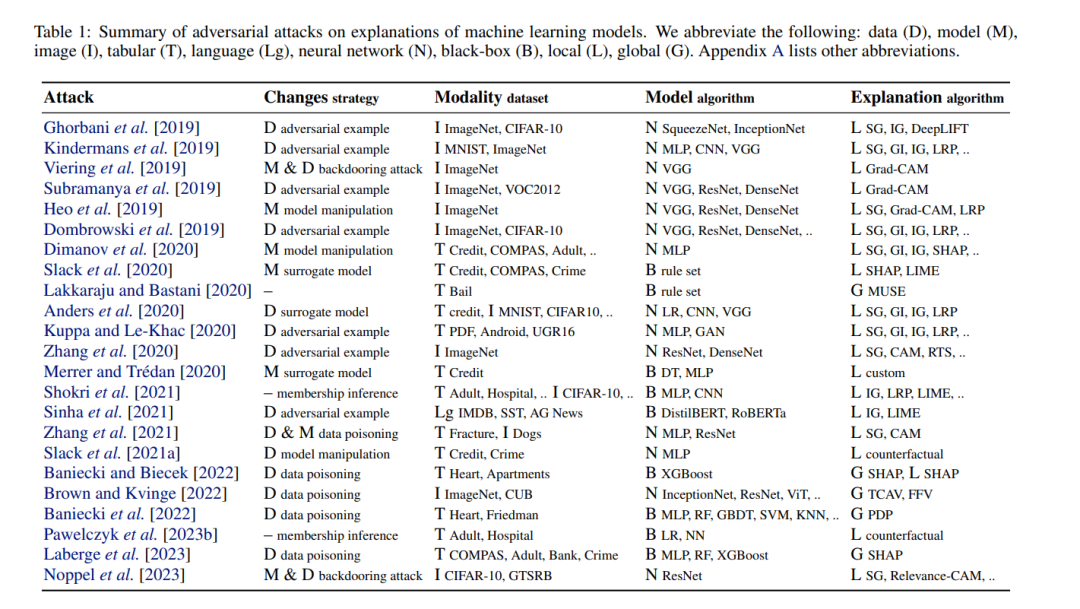
表1列出了对解释方法的攻击,以及相应的改变数据的策略,例如,对抗性示例会操纵解释而不影响预测 [Ghorbani et al., 2019; Dombrowski et al., 2019],改变模型,例如,微调或规范化权重会操纵解释而不影响预测性能 [Heo et al., 2019; Dimanov et al., 2020],或同时改变数据和模型,例如,在攻击者对训练数据集进行投毒的情况下 [Zhang et al., 2021]。Viering et al. [2019]通过改变其权重来操纵卷积神经网络的Grad-CAM解释,但也提出在网络中留下一个后门(由特定输入模式触发),这允许检索原始解释。Noppel et al. [2023]通过微调和后门扩展愚弄解释,以考虑:(i)一种红鲱鱼攻击,该攻击操纵解释以掩盖模型预测的对抗性变化,例如,误分类,和(ii)一种完全伪装的攻击,该攻击旨在为改变的预测展示原始解释。
3 针对解释的攻击的防御
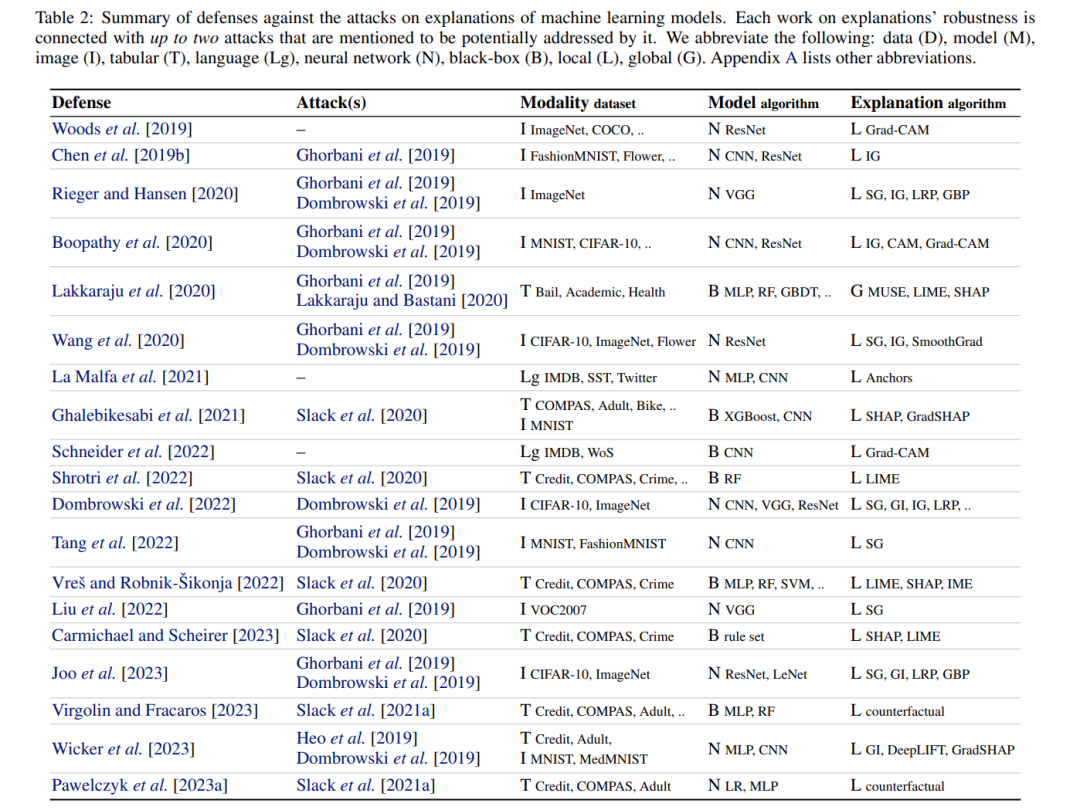
对抗性机器学习是一把双刃剑。每当引入新的攻击算法时,都会提出各种方法来解决解释的局限性并修复其不安全性。Chen et al. [2019b]是通过规范化神经网络防御Ghorbani et al. [2019]引入的对抗性示例的首次尝试之一。提出的鲁棒性归因规则化迫使IG解释在扰动攻击下保持不变。Rieger和Hansen [2020]提出了一种针对这种对抗性示例 [Ghorbani et al., 2019; Dombrowski et al., 2019]的替代防御策略,即聚合用各种算法创建的多个解释。由于攻击仅针对单个解释方法,因此他们的聚合均值接近原始解释(如图1所示)。表2列出了针对解释攻击的防御,其中我们记录了实验中提到的数据集,模型和解释算法。其中排除了改善解释鲁棒性但没有直接关联到潜在对抗性攻击情景的作品 [例如,参见Yeh et al., 2019; Zhou et al., 2021; Zhao et al., 2021; Slack et al., 2021b,并参考其中给出的引用]。我们将每个防御与一个攻击关联,但出于简洁起见,我们省略列出防御可能解决的所有攻击。这里有三个缺失的链接值得澄清。Woods et al. [2019]是早期引入对抗性解释的工作,这些解释对针对模型预测的对抗性示例的鲁棒性得到了改善。类似地,La Malfa et al. [2021]建议改进对抗性扰动下语言模型的解释。与大多数关注算法的贡献不同,Schneider et al. [2022]进行了一项使用人为操纵的解释的用户研究,以评估人们是否可以在实践中发现潜在的攻击 [相关于Lakkaraju和Bastani,2020; Poursabzi-Sangdeh et al., 2021]。Pawelczyk et al. [2023a]和Virgolin和Fracaros [2023]引入了机制,以改善反事实解释对对抗性扰动的鲁棒性。
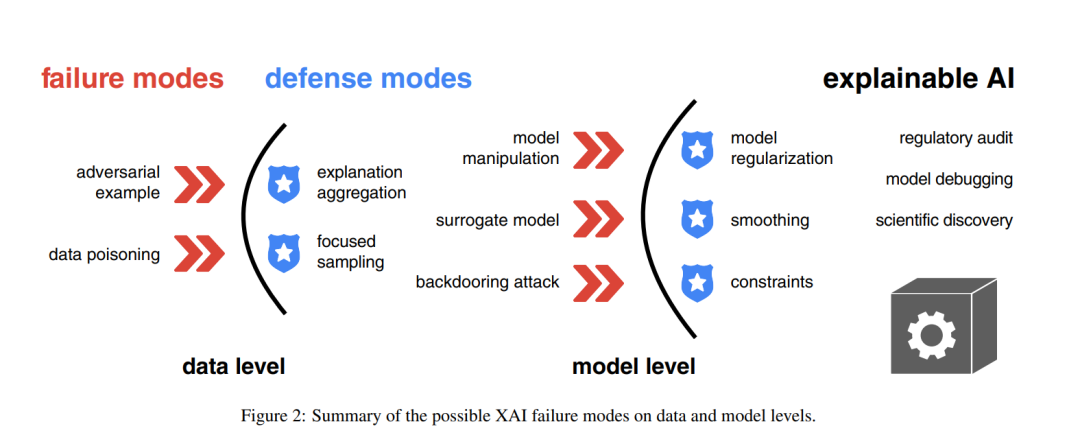
4 AdvXAI中的前沿研究方向
我们在此总结一下AdvXAI中的研究方向。
攻击。目前,最常见的攻击目标是最初引入的和最流行的XAI方法,例如SHAP和Grad-CAM。未来的对抗性攻击工作可能会考虑针对更近期的改进进行攻击,这些改进旨在克服他们的限制,例如SHAPR考虑到了表格数据中的特征依赖性[Aas等人,2021],或者Shap-CAM用于改进卷积神经网络的解释[Zheng等人,2022]。类似于针对神经网络的模型特定解释,值得评估的是针对基于树的模型的特定解释方法的脆弱性,例如TreeSHAP [Lundberg等人,2020],以及假设模型是决策树集成的白盒攻击解释。超越事后可解释性,对抗性攻击可能会针对设计上可解释的深度学习模型的脆弱性,例如ProtoPNet [Chen等人,2019a]及其扩展[例如参见Rymarczyk等人,2022及其相关工作]。最后,有一些对模型预测的对抗性攻击,其主动目标是通过特定的防御机制[例如参见Machado等人,2021,表4],而这种在XAI中规避防御的威胁目前尚未被探索。
防御。本调查的一个目标是重申XAI中明显的安全性问题,即尚未解决的对解释方法的攻击[Viering等人,2019; Zhang等人,2021; Brown和Kvinge,2022; Baniecki等人,2022; Noppel等人,2023; Laberge等人,2023]。我们还强调了操纵公平性度量可能在审计和执法中产生有害后果,因此,开发对攻击具有鲁棒性的度量是可取的。请注意,尽管某个XAI方法受到攻击或防御,实际上,这里讨论的是模型预测的证据。我们未来的目标是以一种方式对调查的攻击和防御机制进行分类,以指导从业者在哪些情况下安全地使用给定的模型和解释,例如,当研究人员使用XGBoost与SHAP代替逻辑回归进行科学发现时。
AdvXAI超越经典模型走向Transformer。如今,Transformer架构是机器学习研究和深度学习实践应用的前沿。因此,对各种模型(如GPT [Bubeck等人,2023],ViT [Dosovitskiy等人,2021]和TabPFN [Hollmann等人,2023])的解释的对抗鲁棒性值得特别关注。例如,Ali等人[2022]将LRP解释扩展到变压器,这可能会扩大解释对对抗攻击的脆弱性,如前述工作[Heo等人,2019; Anders等人,2020]所示。我们承认,最近提出的基于变压器的基础模型,例如SAM [Kirillov等人,2023],越来越频繁地包括特定于评估责任的基准,例如,是否根据人们的性别表现、年龄组或肤色公正地从图像中分割出人物[Schumann等人,2021]。通过有偏样本攻击这样的公平度量的可能性成为了一个信任问题[Fukuchi等人,2020]。
AdvXAI超越图像和表格数据模式。在这里调查的大多数贡献,以及XAI,都涉及到在图像和表格数据集上训练的机器学习预测模型。需要进一步的工作来评估其他数据模式,如语言[La Malfa等人,2021; Schneider等人,2022],图表[Hussain等人,2022],时间序列,多模态系统,以及强化学习代理的解释[Olson等人,2021],的对抗攻击有多严重。
涉及AdvXAI的伦理、社会影响和法律。最后,我们需要考虑对抗性研究对社会的更广泛影响。AdvXAI如何适应像AI法案[Floridi,2021],四分之四的公平规则[Watkins等人,2022],或解释权[克里希纳等人,2023]这样的法规?这些问题尚待回答。对于解释鲁棒性的更深入的哲学考虑,我们建议读者参考Hancox-Li [2020]关于寻求客观解释的知识和伦理原因的论点。