

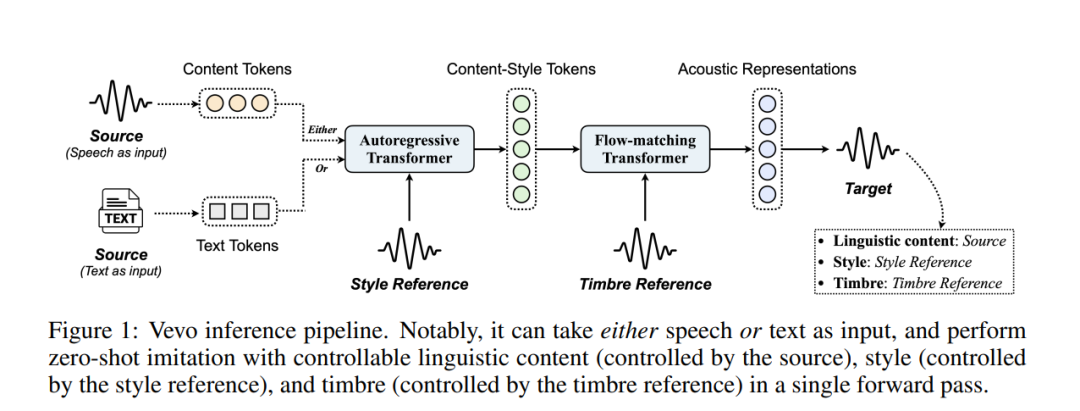
语音模仿,尤其是针对特定的语音属性,如音色和说话风格,对于语音生成至关重要。然而,现有的方法往往过度依赖标注数据,且难以有效地解耦音色与风格,这使得在零-shot场景下实现可控生成面临挑战。为解决这些问题,我们提出了Vevo,一个多功能的零样本语音模仿框架,具备可控的音色与风格。Vevo的工作流程分为两个核心阶段:
-
内容-风格建模:给定文本或语音的内容tokens作为输入,我们使用自回归Transformer生成内容-风格tokens,这一过程受到风格参考的提示;
-
声学建模:给定内容-风格tokens作为输入,我们采用流匹配Transformer生成声学表示,这一过程受到音色参考的提示。
为了获得语音的内容和内容-风格tokens,我们设计了一种完全自监督的方法,逐步解耦语音的音色、风格和语言内容。具体来说,我们采用VQ-VAE [1]作为HuBERT [2]连续隐藏特征的分词器,将VQ-VAE字典的词汇量视为信息瓶颈,并精心调整该瓶颈,以获得解耦后的语音表示。Vevo在没有针对风格特定语料库的微调下,单纯使用60K小时有声书语音数据进行自监督训练,在口音和情感转换任务中,能够与现有方法匹敌或超越。此外,Vevo在零-shot语音转换和文本到语音任务中的有效性,进一步证明了其强大的泛化能力和多功能性。
成为VIP会员查看完整内容
相关内容
Arxiv
36+阅读 · 2023年4月19日
Arxiv
194+阅读 · 2023年4月7日
Arxiv
134+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
194+阅读 · 2023年4月7日
Arxiv
134+阅读 · 2023年3月29日