摘要—人工智能(AI)通过计算能力的提升和海量数据集的增长迅速发展。然而,这一进展也加剧了对AI模型“黑箱”性质的解释挑战。为了解决这些问题,可解释人工智能(XAI)应运而生,重点关注透明性和可解释性,以增强人类对AI决策过程的理解和信任。在多模态数据融合和复杂推理场景中,多模态可解释人工智能(MXAI)的提出将多种模态整合用于预测和解释任务。同时,大型语言模型(LLMs)的出现推动了自然语言处理领域的显著突破,但它们的复杂性进一步加剧了MXAI问题。为了深入了解MXAI方法的发展,并为构建更加透明、公平和可信的AI系统提供重要指导,我们从历史的角度回顾了MXAI方法,并将其划分为四个发展阶段:传统机器学习、深度学习、判别式基础模型和生成式大型语言模型。我们还回顾了MXAI研究中使用的评估指标和数据集,最后讨论了未来的挑战和发展方向。与此综述相关的项目已创建在 https://github.com/ShilinSun/mxai_review。
关键词—大型语言模型(LLMs)、多模态可解释人工智能(MXAI)、历史视角、生成式。
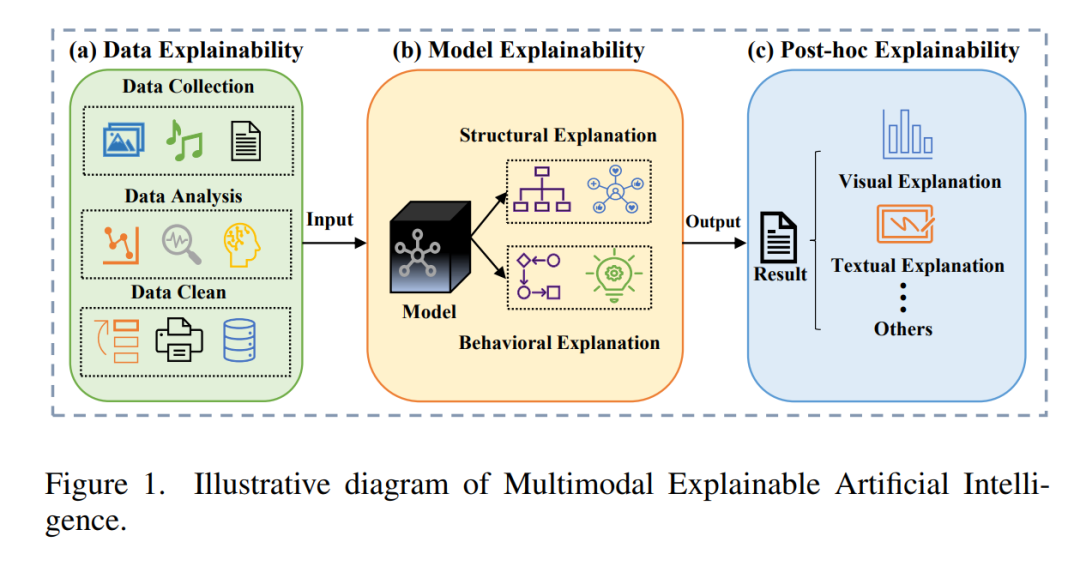
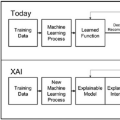
人工智能(AI)的进展对计算机科学产生了重大影响,如Transformer [1]、BLIP-2 [2] 和 ChatGPT [3] 在自然语言处理(NLP)、计算机视觉和多模态任务中表现出色,通过集成多种数据类型。这些相关技术的发展推动了具体应用的进步。例如,在自动驾驶中,系统需要整合来自不同传感器的数据,包括视觉、雷达和激光雷达(LiDAR),以确保在复杂道路环境中的安全运行 [4]。类似地,健康助手需要具备透明性和可信度,以便医生和患者都能轻松理解和验证 [5]。理解这些模型如何结合和解释不同模态对于提升模型可信度和用户信任至关重要。此外,模型规模的不断增大带来了计算成本、可解释性和公平性等挑战,推动了可解释人工智能(XAI)的需求 [6]。随着包括生成式大型语言模型(LLMs)在内的模型变得越来越复杂,数据模态也更加多样化,单一模态的XAI方法已无法满足用户需求。因此,多模态可解释人工智能(MXAI)通过在模型的预测或解释任务中利用多模态数据来解决这些挑战,如图1所示。我们根据数据处理顺序将MXAI分为三种类型:数据可解释性(预模型)、模型可解释性(模型内)和事后可解释性(模型后)。在多模态预测任务中,模型处理多个数据模态,如文本、图像和音频;在多模态解释任务中,利用多种模态来解释结果,从而提供更全面的最终输出解释。
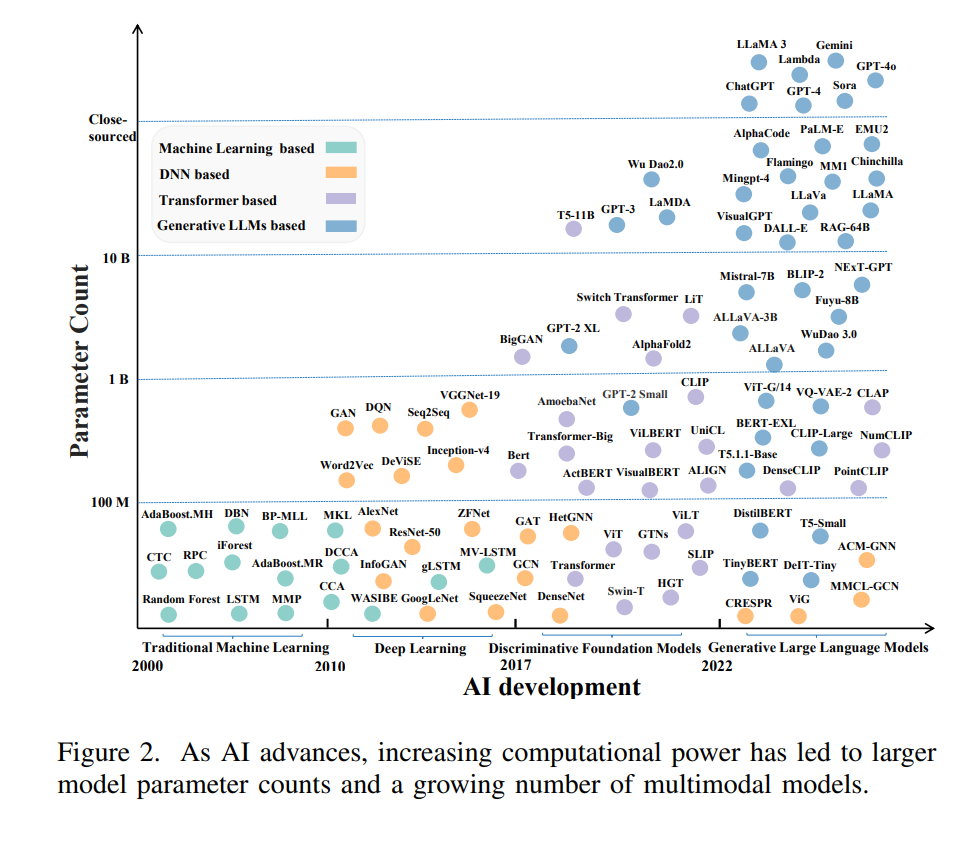
为了回顾MXAI的历史并预测其发展,我们首先将不同阶段进行分类,并从历史角度回顾了各种模型(如图2所示)。在传统机器学习时代(2000-2009年),有限的结构化数据的可用性促进了像决策树这样的可解释模型的出现。在深度学习时代(2010-2016年),随着大型标注数据集(如ImageNet [7])的出现以及计算能力的提升,复杂模型和可解释性研究崭露头角,包括神经网络核的可视化 [8]。在判别式基础模型时代(2017-2021年),Transformer模型的出现,利用大规模文本数据和自监督学习,彻底改变了自然语言处理(NLP)。这一转变引发了对注意力机制的解释研究 [1],[9]–[11]。在生成式大型语言模型时代(2022-2024年),大量多模态数据的集成推动了生成式大型语言模型(LLMs)的发展,如ChatGPT [3],以及多模态融合技术。这些进展提供了全面的解释,增强了模型的透明性和可信度。这一演变导致了对MXAI的关注,它解释了处理多样数据类型的模型 [6]。
然而,最近的XAI综述通常忽视了历史发展,主要集中在单模态方法上。例如,尽管[6]将MXAI方法按模态数、解释阶段和方法类型进行了分类,但忽略了LLMs的可解释性技术。虽然Ali等人 [12] 提出了一个全面的四轴分类法,但缺少关于多模态和LLMs的总结。然而,像[13]、[14]和[15]这样的综述仅关注LLMs的可解释性。我们的研究解决了这些不足,通过提供MXAI的历史视角,分类了MXAI方法的四个时代(传统机器学习、深度学习、判别式基础模型和生成式大型语言模型),并将每个时代分为三个类别(数据、模型和事后可解释性)。本文的主要创新贡献总结如下:
- 我们提供了MXAI方法的历史总结和分析,包括传统机器学习方法和基于LLMs的当前MXAI方法。
- 我们分析了跨时代的方法,涵盖数据、模型和事后可解释性,以及相关的数据集、评估指标、未来挑战和发展方向。
- 我们回顾了现有方法,总结了当前的研究方法,并从历史演变的角度提供了对未来发展的洞见和系统全面的视角。
生成式大型语言模型时代
这一时代的重点是通过判别模型(2017-2021年)奠定的基础来推进生成任务。与前辈不同,这些模型,如GPT-4 [240]、BLIP-2 [2] 及其继任者,通过生成连贯且语境相关的文本来增强可解释性,为输出提供自然语言解释。这一进展弥合了人类理解和机器决策之间的鸿沟,使得与模型的互动更加细致,并为模型行为提供了更多的洞察。我们在表V中总结了相关工作。
**A. 数据可解释性
- 解释数据集:大型语言模型(LLMs)可以通过交互式可视化和数据分析有效地解释数据集。LIDA [241] 通过生成与语法无关的可视化图表和信息图,帮助理解数据的语义,列举相关的可视化目标,并生成可视化规范。其他方法 [242]–[245] 通过分析数据集来增强数据集的可解释性。通过结合多模态信息和强大的自然语言处理能力,LLMs可以提供全面、深入、定制化和高效的数据解释 [13]。Bordt等人 [246] 探讨了LLMs在理解和与“玻璃盒”模型互动中的能力,识别异常行为并提出修复或改进建议。重点在于利用多模态数据的可解释性来增强这些过程。
- 数据选择:数据选择在这一时代至关重要。它提高了模型的性能和准确性,减少了偏差,增强了模型的泛化能力,节省了训练时间和资源,并提升了可解释性,使得决策过程更加透明,有助于模型改进 [302]。多模态C4 [247] 通过整合多个句子-图像对并实施严格的图像过滤,提高了数据集的质量和多样性,排除了小型、不规则比例的图像以及包含人脸的图像。这种方法强调了文本-图像的相关性,增强了多模态模型训练的鲁棒性和可解释性。还提出了一种基于启发式混合数据过滤的生成式AI新范式,旨在增强用户沉浸感并提高视频生成模型与语言工具(例如ChatGPT [3])之间的互动水平 [248]。该方法使得从单个文本或图像提示生成交互式环境成为可能。除了上述内容外,还有一些工作旨在提高模型对分布变化和超出分布数据的鲁棒性 [249],[250]。
- 图形建模:尽管多模态大型语言模型(MLLMs)可以处理和整合来自不同模态的数据,但它们通常是隐式地捕捉关系。相比之下,图形建模通过显式表示数据节点(例如图像中的对象、文本中的概念)及其关系(例如语义关联、空间关系),来更直观地理解复杂数据关系。一些方法 [251]–[253] 将图形结构与LLMs结合,通过多模态整合提升了复杂任务的性能和模型的可解释性。
**B. 模型可解释性
- 过程解释:在这一时代,MXAI的过程解释强调了多模态上下文学习(ICL)和多模态思维链(CoT)。ICL的突出之处在于它能够通过使用人类可理解的自然语言指令来避免对大量模型参数进行广泛更新 [303]。Emu2 [254] 通过扩展多模态模型生成,增强了任务无关的ICL。Link context learning(LCL) [304] 关注因果推理,以提升多模态大型语言模型(MLLMs)的学习能力。[255] 提出了多模态ICL(M-ICL)的综合框架,适用于DEFICS [256] 和OpenFlamingo [257]等模型,涵盖了多种多模态任务。MM-Narrator [258] 利用GPT-4 [240] 和多模态ICL生成音频描述(AD)。进一步的ICL进展和新的多模态ICL变种由 [259] 探讨。MSIER [260] 使用神经网络选择能够提高多模态上下文学习效率的实例。多模态CoT解决了单模态模型在复杂任务中的局限性,在这些任务中,单靠文本或图像无法全面捕获信息。文本缺乏视觉线索,而图像缺少详细描述,这限制了模型的推理能力 [305]。多模态CoT通过整合和推理多种数据类型,如文本和图像 [261]–[264],来解决这一问题。例如,图像识别可以分解为逐步的认知过程,构建生成视觉偏见的网络链,这些偏见在每一步都被加到输入的词嵌入中 [261]。Zhang等人 [262] 首先从视觉和语言输入中生成推理依据,然后将其与原始输入结合进行推理。混合推理依据 [306] 使用文本推理来引导视觉推理,通过融合特征提供连贯且透明的答案解释。
- 内在可解释性:在这一小节中,我们探讨了多模态大型语言模型(MLLMs)的内在可解释性,重点是两类主要任务:多模态理解和多模态生成 [307]。多模态理解任务包括图像-文本、视频-文本、音频-文本和多模态-文本理解。在图像-文本理解中,BLIP-2 [2] 通过两阶段的预训练过程增强了解释性,将视觉数据与文本数据对齐,从而提高了图像描述的连贯性和相关性。LLaVA [308] 通过将图像-文本对转换为与GPT-4 [240] 兼容的格式,并将CLIP的视觉编码器与LLaMA的语言解码器对接进行微调,生成了指令跟随数据。像LLaVA-MoLE [309]、LLaVA-NeXT [271] 和LLaVA-Med [272]等变种在此基础上进行了增强,针对特定领域和任务做出了改进。对于视频-文本理解,与图像不同,视频具有时间维度,需要模型处理静态帧并理解它们之间的动态关系。这增加了多模态模型的复杂性,但也提供了更丰富的语义信息和更广泛的应用场景。VideoChat [273] 构建了一个以视频为中心的指令数据集,强调时空推理和因果关系。该数据集增强了时空推理、事件定位和因果推理,整合了视频和文本,从而提高了模型的准确性和鲁棒性。Dolphins [274] 结合视觉和语言数据来解读驾驶环境,并与驾驶员自然互动。它提供了清晰且具有相关性的指令,为其建议生成解释,并通过不断学习新经验来适应不断变化的驾驶条件。对于音频-文本理解,音频数据由于其时间序列的性质,需要模型能够解析和理解时间动态。这扩展了多模态理解的能力。Salmonn [275] 将预训练的基于文本的LLM与语音和音频编码器整合到一个统一的多模态框架中。这种设置使得LLMs能够直接处理和理解普通音频输入,增强了多模态可解释性,并提供了有关文本和音频数据关系的洞察。尽管如此,Salmonn在实现全面音频理解方面仍面临挑战。相比之下,Qwen-audio [276] 通过开发大规模音频-语言模型来推动该领域的发展。通过利用大量的音频和文本数据集,Qwen-audio提高了模型处理和解释多样听觉输入的能力,从而推动了多模态理解的边界,并在各种音频相关任务中展现了强大的表现。
结论
本文将多模态可解释人工智能(MXAI)方法按历史发展分为四个时代:传统机器学习、深度学习、判别基础模型和生成式大型语言模型。我们从数据、模型和后验可解释性三个方面分析了MXAI的演变,并回顾了相关的评估指标和数据集。展望未来,主要挑战包括可解释性技术的规模化、平衡模型的准确性与可解释性以及解决伦理问题。MXAI的持续进展对于确保AI系统的透明性、公正性和可信性至关重要。