

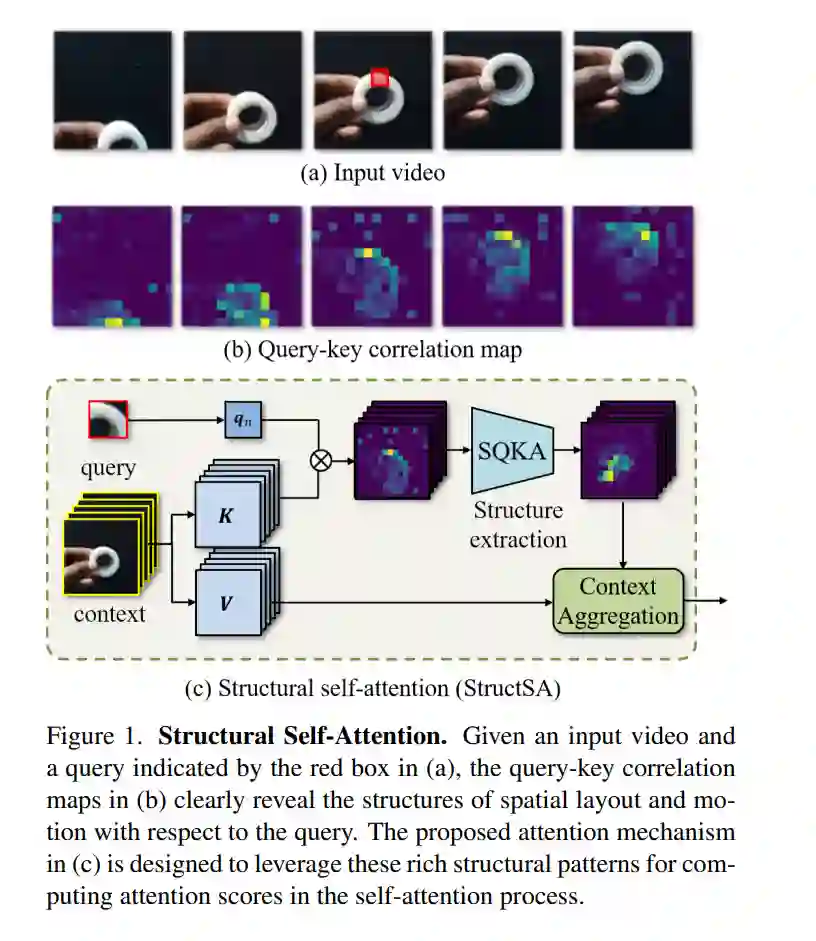
我们引入了一种新的注意力机制,称为结构性自注意力(StructSA),它利用在注意力的关键查询互动中自然出现的丰富相关模式。StructSA通过卷积识别关键查询相关性的时空结构来生成注意力图,并使用它们动态地聚合值特征的局部上下文。这有效地利用了图像和视频中的丰富结构模式,如场景布局、对象运动和对象间关系。使用StructSA作为主要构建块,我们开发了结构视觉变压器(StructViT),并评估其在图像和视频分类任务上的有效性, 在ImageNet-1K、Kinetics-400、Something-Something V1 & V2、Diving-48和FineGym上取得了最先进的结果。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日