

长尾数据是一种特殊类型的多类别不平衡数据,具有大量少数/尾部类,这些类的组合影响非常显著。长尾学习旨在在具有长尾分布的数据集上构建高性能模型,这些模型可以高精度地识别所有类别,特别是少数/尾部类别。这是一个前沿的研究方向,在过去几年中吸引了大量的研究努力。在本文中,我们对长尾视觉学习的最新进展进行了全面综述。我们首先提出了一种新的长尾学习分类法,包含八个不同的维度,包括数据平衡、神经架构、特征丰富、对数调整、损失函数、附加功能、网络优化和事后处理技术。基于我们提出的分类法,我们对长尾学习方法进行了系统回顾,讨论了它们的共性和可比差异。我们还分析了不平衡学习和长尾学习方法之间的差异。最后,我们讨论了该领域的前景和未来方向。
关键词——长尾学习、长尾数据、不平衡学习、深度学习、深度不平衡学习。
“长尾理论”一词由Chris Anderson的书《长尾:为什么未来的商业是少卖多销》 [1] 普及,该书观察和分析了商业从广告和营销少量畅销产品转向关注大量利基产品的变化,因为它们的综合销售/收入可能与头部(最受欢迎的)产品同样显著。它与“帕累托原理”(又称“80/20法则”)、Zipf定律或“重要少数法则”密切相关。一般来说,它们就像一枚硬币的两面。帕累托原理关注头部/热门产品并切断其余部分,而长尾理论则旨在捕捉尾部并强调尾部类/利基项目的综合重要性。
长尾数据本质上是一种特殊类型的多类别不平衡数据,具有足够大量的尾部(少数)类。此外,尽管每个尾部类本身只有少量样本(销售),但这些尾部类的综合重要性非常显著。长尾分布的数据在现实世界场景中相对常见,通常需要人工智能(AI)系统和应用程序处理,例如高速列车故障诊断 [2],[3],电梯安全监控 [4] 等。事实上,AI不仅应满足头部/热门应用,还应能够覆盖大量尾部案例,以确保技术和系统的鲁棒性和泛化能力。
长尾学习(以下简称LTL)是人工智能/机器学习的一个子领域,旨在为具有长尾分布数据的应用/任务构建有效模型。其主要目标是在保持头部(频繁/多数)类或案例的相同或类似准确率的同时,显著提高对尾部(稀有/少数)类或案例的识别准确率。具体来说,1)在对象识别/分类中,研究人员提出了许多LTL方法 [5],[6],[7],[8],[9],[10],[11],可以显著提高对尾部类/案例的识别/预测准确率,例如稀有物种、缺陷工业产品。研究表明 [5],[10],[11],[12],[13],通过解耦深度特征表示学习和分类器训练,取得了可喜的结果。还有大量损失重加权方法,为头部和尾部类的样本赋予不同的权重,以在长尾设置下调整决策边界 [6],[14],[15],[16],[17],[18]。2)在对象检测中,一些LTL方法 [19],[20],[21] 也被设计用于自动从图像或视频中定位稀有对象或案例,例如定位工业设备中的裂缝或检测自然公园附近的工程车辆;3)在图像分割中,研究人员也开发了能够识别和分割图像中稀有对象/案例的方法,例如异常行为、医学图像中的病理区域等。此外,还设计了特定的LTL数据增强技术,以缓解尾部类中的数据稀缺问题 [25],[26],[27],[28],[29]。
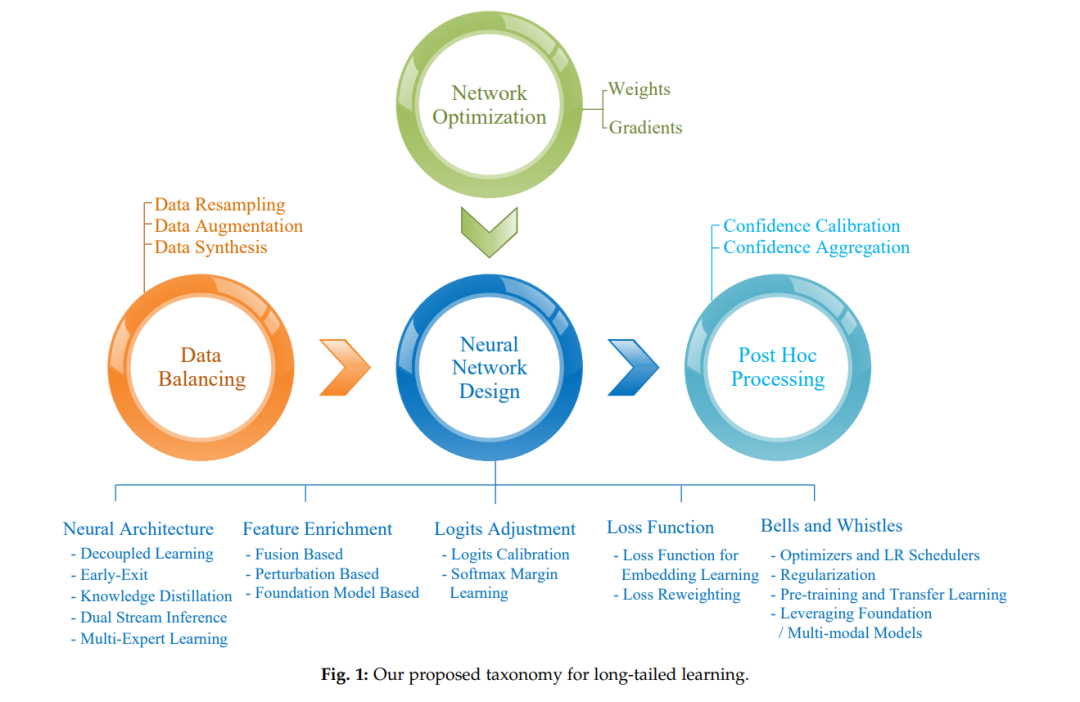
然而,由于该领域的快速发展,跟上LTL的最新进展变得越来越困难。因此,对该领域现有方法进行全面综述对社区来说是紧迫且有益的。这促使我们对长尾视觉学习的最新进展进行深入综述,以系统地了解其原理和技术方面。基于内在学习过程,我们首先提出了一种新的分类法,将现有长尾视觉学习方法分为八类,如图1所示,包括数据平衡、神经架构、特征丰富、对数调整、损失函数、附加功能、网络优化和事后处理方法。基于这一新分类法,我们对现有的LTL方法进行了全面综述,并讨论了它们的理念和特点。此外,我们对比了不平衡学习和长尾学习,阐明了它们的联系和差异。最后,我们讨论了该领域的挑战和未来的研究机会。 尽管最近有一些论文 [30],[31],[32] 也提供了长尾学习的文献综述,但我们通过以下差异区分我们的综述:1)现有的综述通常采用传统的分类法,将现有的LTL方法分为三类,即数据重采样和增强类别、损失重加权类别和迁移学习类别。然而,这种分类法不足以全面理解最新的LTL方法,因为它无法充分涵盖LTL的整个学习过程。在这项工作中,我们提出了一种基于其内在学习过程的分类法,从统一的角度来看待LTL,其中我们识别了四个主要步骤和八个主要类别,如图1所示。使用这一新分类法,我们提供了对现有LTL方法的更为及时和深入的综述,讨论了它们的共性和可比差异。2)我们详细对比了LTL和不平衡学习。3)我们包括了LTL的最新进展并指出了该领域的未来方向。
本文的主要贡献可以总结如下: 1)我们提出了一个具有八个维度的统一分类法,用于表征和组织现有的长尾学习方法。 2)我们提供了一个全面的、基于分类法的最新长尾视觉学习方法综述,重点关注最新的进展和趋势。 3)我们对长尾学习和不平衡学习进行了对比,阐明了它们的联系和差异。 4)我们总结并分析了不同LTL方法在不同下游任务中的结果,使用相应的基准数据集。 5)最后,我们讨论了对该领域研究人员可能感兴趣的未来研究方向和趋势。
本文的其余部分组织如下。在第2节中,我们介绍了长尾视觉学习的背景和相关综述论文。在第3节中,基于我们提出的分类法,我们全面概述了最先进的LTL方法。在第4节中,我们提供了不平衡学习和长尾学习的详细对比,然后在第5节中进行了长尾分布的初步讨论。在第6节中,我们总结并分析了不同LTL方法在不同下游任务中的实验结果。在第7节中,我们讨论了未来的研究方向和趋势,并在第8节中总结了本文。

在图1和图2中,我们展示了长尾学习的新分类法,将现有技术分为八类:1)数据平衡;2)神经架构;3)特征丰富;4)对数调整;5)损失函数;6)附加功能;7)网络优化;8)事后处理。 数据平衡方法利用数据重采样、数据增强或数据合成技术来构建类平衡的训练集,以训练神经网络模型。 神经架构方法设计特定的网络架构以提高长尾学习的性能。 特征丰富方法旨在使用记忆库或扰动策略来增强尾部样本的特征,或利用从预训练/基础模型中提取的额外或多模态特征。 对数调整方法调整对数值或扩大分类边界以提高长尾学习的性能。 损失函数设计的方法要么增加尾部类样本或困难样本的损失值,要么设计综合损失函数作为优化目标,以增强嵌入/表示学习的效果。 “附加功能”包含用于网络训练和性能增强的各种策略和技术细节。 网络优化主要涉及内部网络优化的权重和梯度更新技术。
最后,事后处理方法校准长尾模型的置信度以适应现实世界的场景。 接下来,我们将介绍每个类别中的代表性技术。 在本文中,我们提出了一种新的长尾学习分类法,将现有技术分为八类,包括数据平衡、神经架构、特征丰富、对数调整、损失函数、附加功能、网络优化和事后处理技术。
基于这一分类法,我们系统地回顾了每个类别中的长尾学习方法,包括最新的进展。我们还研究了不平衡学习和长尾学习方法之间的区别。 我们总结了代表性方法的实验结果,显示在这一领域还有很大的改进空间。最后,我们讨论了该领域的未来研究方向。
