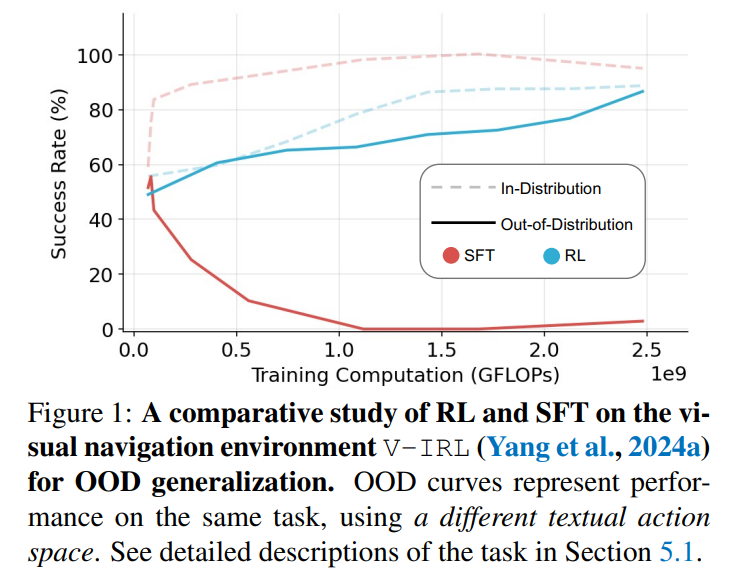
![]() 监督微调(SFT)和强化学习(RL)是基础模型常用的后训练技术。然而,它们在增强模型泛化能力方面的具体作用仍不清楚。本文研究了SFT和RL在泛化和记忆方面的比较效果,重点关注基于文本和视觉的环境。我们引入了GeneralPoints,一款算术推理卡牌游戏,并考虑了V-IRL,一个现实世界的导航环境,以评估通过SFT和RL训练的模型如何在文本和视觉领域中泛化到未见过的变种。我们展示了RL,特别是在使用基于结果的奖励进行训练时,能够在基于规则的文本和视觉环境中实现泛化。相反,SFT倾向于记忆训练数据,并且在任何情况下都难以在分布外泛化。进一步的分析揭示,RL提升了模型的基础视觉识别能力,促进了其在视觉领域的泛化能力。尽管RL在泛化能力上优于SFT,我们仍然表明SFT对于有效的RL训练仍然有帮助:SFT稳定了模型的输出格式,从而使得随后的RL能够实现性能提升。这些发现展示了RL在复杂多模态任务中获取可泛化知识的优势。1 引言虽然监督微调(SFT)和强化学习(RL)都广泛用于基础模型的训练(OpenAI, 2023b;Google, 2023;Jaech et al., 2024;DeepSeekAI et al., 2025),但它们在泛化(Bousquet & Elisseeff, 2000;Zhang et al., 2021)上的不同影响仍不清楚,这使得构建可靠和稳健的AI系统具有挑战性。分析基础模型泛化能力的一个关键挑战(Bommasani et al., 2021;Brown et al., 2020)是区分数据记忆与可转移原则的获取。因此,我们研究了一个关键问题,即SFT和RL是否主要记忆训练数据(AllenZhu & Li, 2023a;Ye et al., 2024;Kang et al., 2024),或是它们学习了可以适应新任务变种的可泛化原则。为了回答这个问题,我们关注泛化的两个方面:基于文本的规则泛化和视觉泛化。对于文本规则,我们研究模型将学习到的规则(给定文本指令)应用到这些规则的变种上的能力(Zhu et al., 2023;Yao et al., 2024;Ye et al., 2024)。对于视觉-语言模型(VLMs),视觉泛化衡量模型对视觉输入变化(如颜色和空间布局)的性能一致性,任务保持不变。为了研究基于文本和视觉的泛化,我们调查了两个不同的任务,分别体现了规则性和视觉变种。我们的第一个任务是GeneralPoints,这是一种原创卡牌游戏任务,类似于RL4VLM中的Points24任务(Zhai et al., 2024a),旨在评估模型的算术推理能力。在GeneralPoints中,模型接收四张卡片(以文本描述或图像呈现),并要求使用每张卡片的数字值精确计算一个目标数字(默认值为24)。第二个任务是采用V-IRL(Yang et al., 2024a),这是一个现实世界的导航任务,专注于模型的空间推理能力。我们采用了类似于Zhai et al.(2024a)的方法,通过在主干模型上运行SFT后,再实施RL的多步强化学习框架(Dubey et al., 2024),并使用序列修正公式(Snell et al., 2024)。在GeneralPoints和V-IRL中,我们观察到RL能够学习到可泛化的规则(以文本形式表达),其中在训练分布内的性能提升也能转移到未见过的规则。相反,SFT似乎会记忆训练规则,无法实现泛化(具体示例见图1)。除了基于文本的规则泛化,我们进一步研究了视觉领域的泛化,观察到RL同样能泛化到视觉的分布外(OOD)任务,而SFT仍然难以应对。作为视觉OOD泛化能力的副产品,我们的多回合RL方法在V-IRL小型基准测试中实现了最新的性能,提升了+33.8%(44.0% → 77.8%)(Yang et al., 2024a),突显了RL的泛化能力。为了理解RL如何影响模型的视觉能力,我们在GeneralPoints上进行了额外分析,揭示了使用基于结果的奖励函数(Cobbe et al., 2021)训练RL能提升视觉识别能力。尽管RL在泛化能力上优于SFT,我们仍然表明,SFT对于稳定模型的输出格式仍然有帮助,这使得RL能够实现性能提升。最后,我们观察到,通过增加最大步骤数来扩大推理时间计算,从而提高了泛化能力。
监督微调(SFT)和强化学习(RL)是基础模型常用的后训练技术。然而,它们在增强模型泛化能力方面的具体作用仍不清楚。本文研究了SFT和RL在泛化和记忆方面的比较效果,重点关注基于文本和视觉的环境。我们引入了GeneralPoints,一款算术推理卡牌游戏,并考虑了V-IRL,一个现实世界的导航环境,以评估通过SFT和RL训练的模型如何在文本和视觉领域中泛化到未见过的变种。我们展示了RL,特别是在使用基于结果的奖励进行训练时,能够在基于规则的文本和视觉环境中实现泛化。相反,SFT倾向于记忆训练数据,并且在任何情况下都难以在分布外泛化。进一步的分析揭示,RL提升了模型的基础视觉识别能力,促进了其在视觉领域的泛化能力。尽管RL在泛化能力上优于SFT,我们仍然表明SFT对于有效的RL训练仍然有帮助:SFT稳定了模型的输出格式,从而使得随后的RL能够实现性能提升。这些发现展示了RL在复杂多模态任务中获取可泛化知识的优势。1 引言虽然监督微调(SFT)和强化学习(RL)都广泛用于基础模型的训练(OpenAI, 2023b;Google, 2023;Jaech et al., 2024;DeepSeekAI et al., 2025),但它们在泛化(Bousquet & Elisseeff, 2000;Zhang et al., 2021)上的不同影响仍不清楚,这使得构建可靠和稳健的AI系统具有挑战性。分析基础模型泛化能力的一个关键挑战(Bommasani et al., 2021;Brown et al., 2020)是区分数据记忆与可转移原则的获取。因此,我们研究了一个关键问题,即SFT和RL是否主要记忆训练数据(AllenZhu & Li, 2023a;Ye et al., 2024;Kang et al., 2024),或是它们学习了可以适应新任务变种的可泛化原则。为了回答这个问题,我们关注泛化的两个方面:基于文本的规则泛化和视觉泛化。对于文本规则,我们研究模型将学习到的规则(给定文本指令)应用到这些规则的变种上的能力(Zhu et al., 2023;Yao et al., 2024;Ye et al., 2024)。对于视觉-语言模型(VLMs),视觉泛化衡量模型对视觉输入变化(如颜色和空间布局)的性能一致性,任务保持不变。为了研究基于文本和视觉的泛化,我们调查了两个不同的任务,分别体现了规则性和视觉变种。我们的第一个任务是GeneralPoints,这是一种原创卡牌游戏任务,类似于RL4VLM中的Points24任务(Zhai et al., 2024a),旨在评估模型的算术推理能力。在GeneralPoints中,模型接收四张卡片(以文本描述或图像呈现),并要求使用每张卡片的数字值精确计算一个目标数字(默认值为24)。第二个任务是采用V-IRL(Yang et al., 2024a),这是一个现实世界的导航任务,专注于模型的空间推理能力。我们采用了类似于Zhai et al.(2024a)的方法,通过在主干模型上运行SFT后,再实施RL的多步强化学习框架(Dubey et al., 2024),并使用序列修正公式(Snell et al., 2024)。在GeneralPoints和V-IRL中,我们观察到RL能够学习到可泛化的规则(以文本形式表达),其中在训练分布内的性能提升也能转移到未见过的规则。相反,SFT似乎会记忆训练规则,无法实现泛化(具体示例见图1)。除了基于文本的规则泛化,我们进一步研究了视觉领域的泛化,观察到RL同样能泛化到视觉的分布外(OOD)任务,而SFT仍然难以应对。作为视觉OOD泛化能力的副产品,我们的多回合RL方法在V-IRL小型基准测试中实现了最新的性能,提升了+33.8%(44.0% → 77.8%)(Yang et al., 2024a),突显了RL的泛化能力。为了理解RL如何影响模型的视觉能力,我们在GeneralPoints上进行了额外分析,揭示了使用基于结果的奖励函数(Cobbe et al., 2021)训练RL能提升视觉识别能力。尽管RL在泛化能力上优于SFT,我们仍然表明,SFT对于稳定模型的输出格式仍然有帮助,这使得RL能够实现性能提升。最后,我们观察到,通过增加最大步骤数来扩大推理时间计算,从而提高了泛化能力。 ![]()