

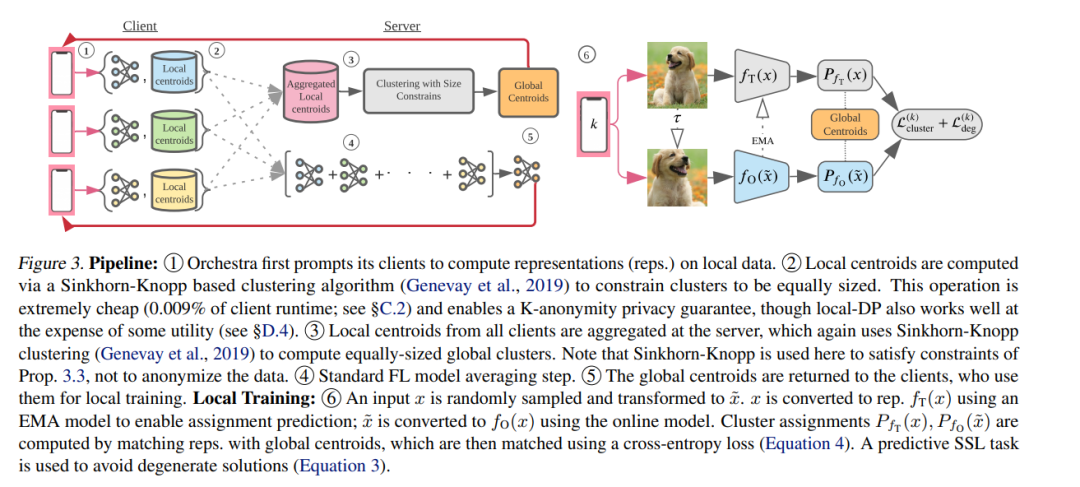
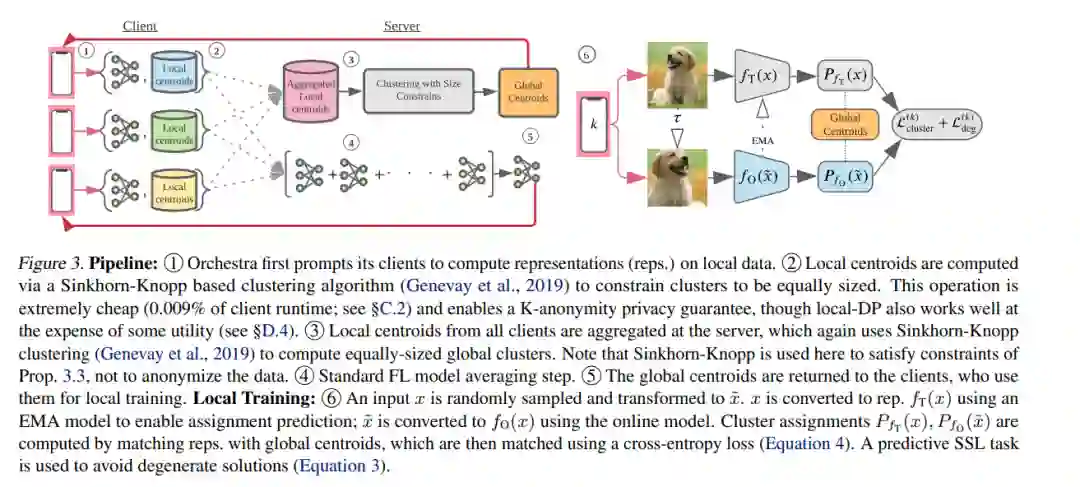
联邦学习通常用于标签随时可用的任务(例如,下一个单词预测)。放松这一约束需要设计无监督学习技术,以支持联邦训练所需的属性: 对统计/系统异构性的鲁棒性、参与者数量的可伸缩性,以及通信效率。之前关于这个主题的工作主要集中在直接扩展集中的自监督学习技术,这些技术并没有设计成具有上面列出的属性。为了解决这种情况,我们提出了一种新的无监督联邦学习技术Orchestra,它利用联邦的层次结构来编排分布式集群任务,并强制将客户的数据全局一致地划分为可识别的集群。我们展示了Orchestra的算法流程在线性探测下保证了良好的泛化性能,允许它在广泛的条件下优于其他技术,包括异质性的变化、客户数量、参与比例和局部次数。
https://www.zhuanzhi.ai/paper/2333eeef5722bb0aa362d044a5db9bf4
成为VIP会员查看完整内容

相关内容

Arxiv
0+阅读 · 2022年7月15日
Arxiv
21+阅读 · 2018年12月25日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年7月15日
Arxiv
21+阅读 · 2018年12月25日