摘要—检索增强生成(Retrieval-Augmented Generation, RAG)近年来已成为人工智能(AI)领域中的关键技术,尤其在提升大型语言模型(Large Language Models, LLMs)能力方面表现突出。RAG 通过接入外部、可靠且最新的知识源,极大地增强了模型的输出质量。在 AI 生成内容(AI-Generated Content, AIGC)的背景下,RAG 的价值尤为显著,其通过补充相关信息来优化生成结果。 近期,RAG 的应用前景已扩展至自然语言处理(NLP)以外的领域,相关研究开始将检索增强策略引入计算机视觉(Computer Vision, CV)领域。这些方法旨在突破仅依赖模型内部知识的局限性,通过引入权威的外部知识库,提升视觉模型在理解与生成任务中的表现。
本文对 CV 领域中检索增强技术的现状进行了系统综述,聚焦于两个核心方向:(I)视觉理解 和(II)视觉生成。在视觉理解方面,我们系统性地回顾了从基础图像识别到复杂任务(如医学报告生成与多模态问答)等多个应用场景。在视觉内容生成方面,我们探讨了 RAG 在图像、视频及三维生成等任务中的应用。此外,我们还介绍了 RAG 在具身智能(Embodied AI)领域的最新进展,特别是在规划、任务执行、多模态感知、交互以及专业领域中的应用。
鉴于检索增强技术在 CV 中的融合仍处于初期阶段,本文亦指出了当前方法的主要限制,并提出未来的研究方向,以推动该前沿领域的发展。 本综述的最新信息可参阅:https://github.com/zhengxuJosh/Awesome-RAG-Vision。
A. 背景
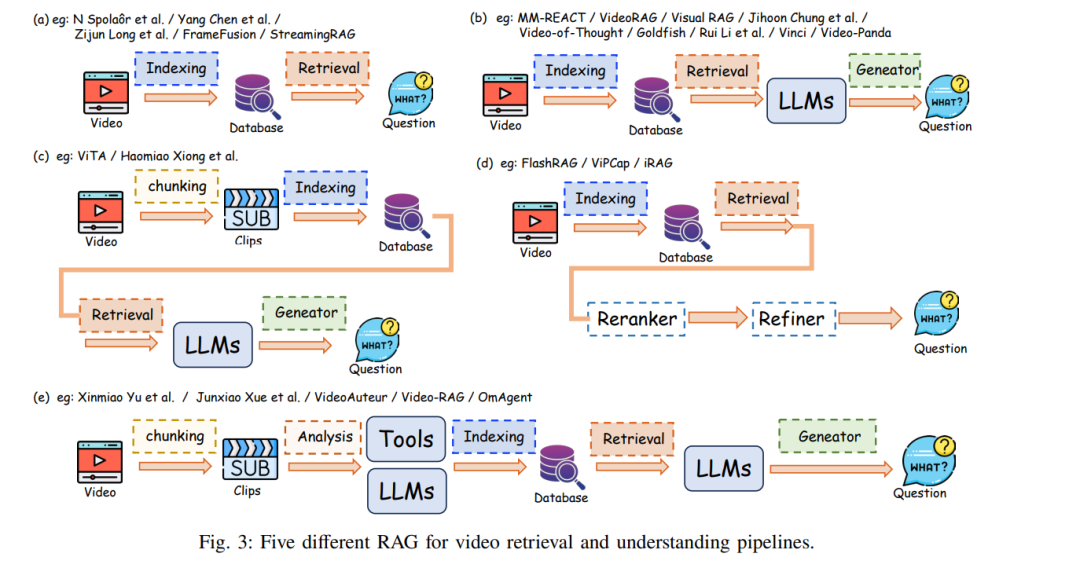
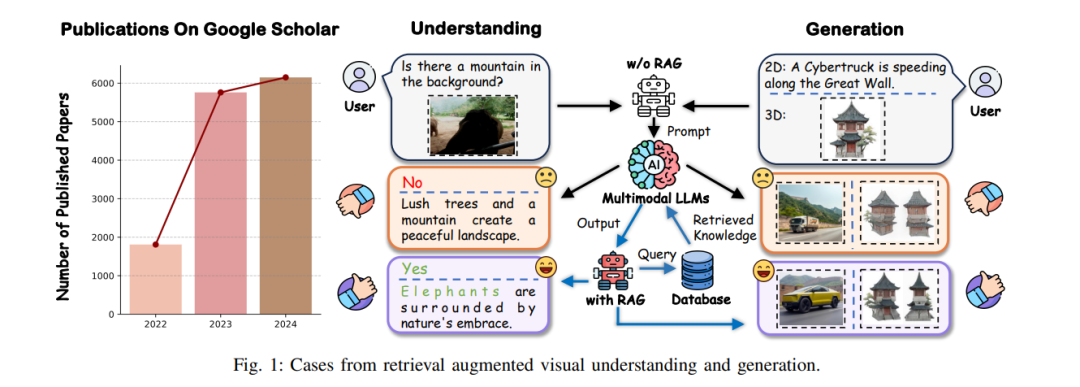
检索增强生成(Retrieval-Augmented Generation, RAG)是生成式人工智能(Generative AI)中的一种变革性技术,尤其在自然语言处理(Natural Language Processing, NLP)和推荐系统中表现突出。它通过集成外部、最新的信息来源来提升内容质量 [1]。尽管大型语言模型(Large Language Models, LLMs)已展现出卓越的性能,但仍面临诸如幻觉(hallucination)、知识陈旧、领域专长缺乏等挑战 [1]。RAG 通过提供相关且可检索的事实性信息来增强 LLM 的输出,从而有效应对上述问题。 RAG 的工作机制是利用检索器从外部数据库中提取相关知识 [12],并将其与模型输入相结合,从而提供更丰富的上下文信息 [13]。这种方法高效,通常只需最少的调整,甚至无需额外训练 [2]。近期研究指出,RAG 不仅在知识密集型任务中表现出潜力,还在广泛的语言任务中提高了输出的准确性和时效性 [2]。 虽然传统的 RAG 流水线以文本为主,但现实世界中的知识往往是多模态的,呈现为图像、视频和三维模型等形式。这为 RAG 在计算机视觉(Computer Vision, CV)中的应用带来了挑战。在 CV 中,诸如目标识别 [14, 15]、异常检测 [16] 和图像分割 [17] 等视觉理解任务,若能整合外部知识,将有助于提升准确性 [13]。同样,诸如将文本描述转化为逼真图像的视觉生成任务,也可从外部知识(如场景布局、对象关系和视频中的时间动态)中受益 [15]。
鉴于视觉数据的复杂性,RAG 有望显著提升模型表现。例如,场景生成模型可借助关于对象交互和空间关系的知识提升生成质量;而图像分类模型则可通过检索最新视觉参考资料来提高准确率。通过整合外部知识,RAG 同时增强了视觉理解与生成能力,有助于克服视觉任务中的固有难题。如图 1 所示,已有研究开始探索 RAG 与 CV 的结合,旨在同时提升理解与生成效果。尽管大规模视觉语言模型(Large Vision-Language Models, LVLMs)已展现出前景,但在图像泛化与理解方面仍存在挑战 [18]。在三维建模领域,Phidias 等工具 [19] 利用检索到的三维模型指导新模型生成,从而提升了生成质量与泛化能力。然而,RAG 在增强模型可信度、鲁棒性以及在动态环境中适应性等方面的潜力尚未被充分挖掘,这也为未来研究提供了宝贵机遇。
B. 主要贡献
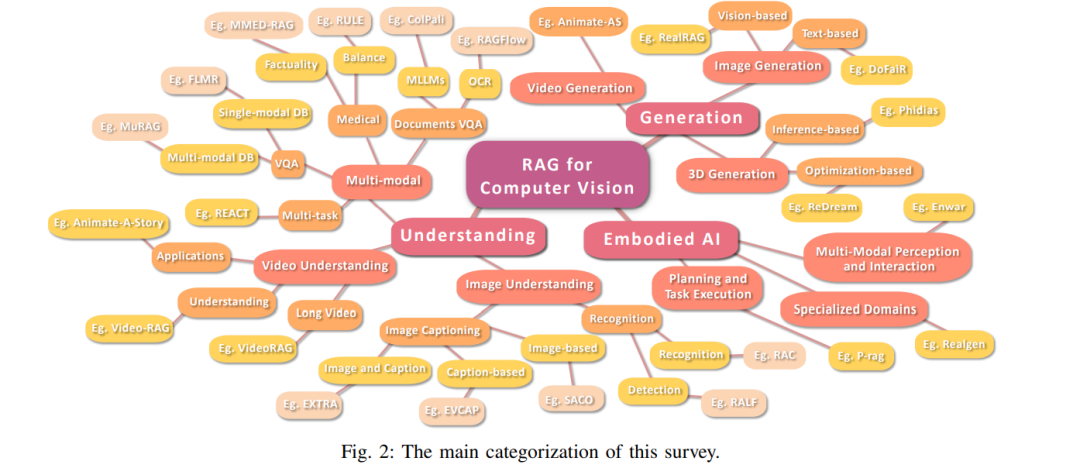
本综述全面系统地回顾了计算机视觉(CV)领域中 RAG 技术的发展,涵盖视觉理解、视觉生成及具身视觉等方面。本文的主要贡献如下: 1. 视觉任务分析:我们系统分析了检索增强方法在视觉理解(第 II 节)、视觉生成(第 III 节)以及具身视觉(第 IV 节)中的作用,聚焦于图像、视频、多模态理解任务以及三维生成,展示了 RAG 在这些任务中的应用效果。 1. 方法分类体系:我们构建了 RAG 技术在各类视觉任务中的方法分类体系,突出其关键贡献与差异,并在模式识别、医学视觉和视频分析等方向对相关方法进行了比较(见第 II 节)。 1. 关键问题识别:我们总结了当前 RAG 应用中的主要局限,如检索效率、多模态对齐、计算成本与领域适应性问题,并深入探讨了这些挑战如何限制其广泛应用(见第 V 节)。 1. 未来研究方向:我们提出了推动 RAG 在 CV 领域发展的未来研究方向,包括实时检索优化、跨模态检索融合、隐私感知检索机制以及基于检索的生成建模,为进一步探索该技术开辟了新思路(见第 V 节)。 1. 多模态拓展与具身 AI 应用:我们将 RAG 应用从基于文本的检索扩展到多模态框架,探讨其在增强视觉模型方面的潜力,并分析其在具身智能、三维内容生成、多模态学习等领域中的应用前景,涵盖机器人技术、自动驾驶及真实世界中的决策任务(见第 V 节)。
本文作为该领域的系统性资源,汇集了现有研究成果,为检索增强技术在计算机视觉中的未来发展提供了理论基础与实践指南。
C. 相关工作
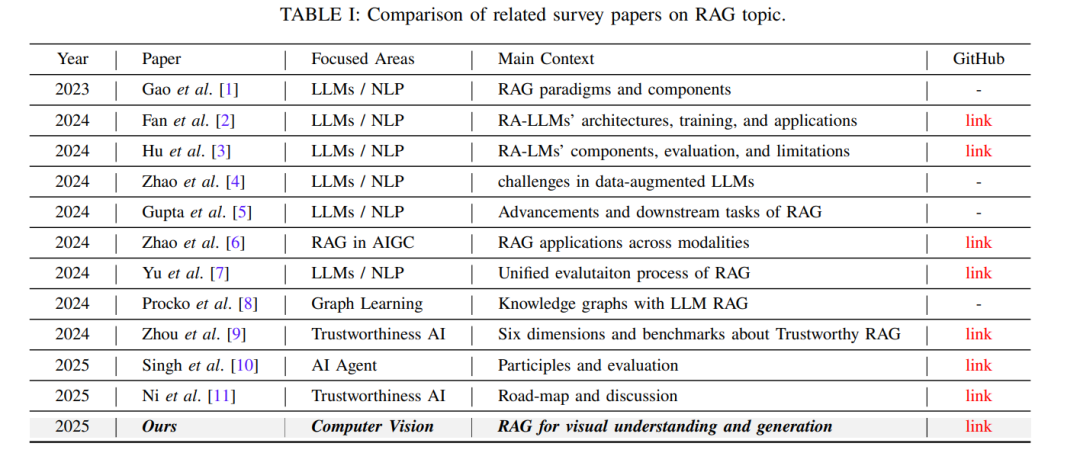
表 I 总结了 RAG 领域的重要研究工作,主要聚焦于语言模型(LLMs)以及跨模态整合外部知识的方法。Gao 等人 [1] 总结了 RAG 各种范式,强调了外部知识在提升 LLM 能力方面的作用。Fan 等人 [2] 进一步讨论了检索增强语言模型(RA-LLMs)在架构、训练策略及应用层面的发展。Hu 等人 [3] 对检索增强语言模型(RALMs)进行了全面评估,探讨了其组成部分、局限性及改进方向。Zhao 等人 [4] 关注数据增强 LLMs 中的挑战,特别是检索质量与数据整合问题。Gupta 等人 [5] 回顾了 RAG 技术的发展,并探讨其在下游任务中的应用,揭示了其在语言处理中的不断演化。 Zhao 等人 [6] 将 RAG 的应用扩展至 AI 生成内容(AIGC),强调其跨模态潜力。Yu 等人 [7] 提出了 RAG 的统一评估框架,旨在标准化各任务的性能指标。Procko 等人 [8] 探讨了知识图谱与基于 LLM 的 RAG 系统的结合。Zhou 等人 [9] 关注 RAG 的可信性问题,并呼吁构建更具鲁棒性的评测基准。Singh 等人 [10] 与 Ni 等人 [11] 分别从“自主型 RAG”与“可信度”角度出发,提出了新的评估框架与未来研究方向。 在这些基础工作之上,本文首次聚焦于 RAG 在计算机视觉中的应用。我们简要回顾了其在视觉理解与生成中的应用现状,强调了其潜力与挑战。我们的研究将 RAG 从语言模型拓展至视觉任务,探讨其对 CV 的影响,并通过结合检索技术与视觉感知的方法,为未来研究铺设了方向。图 2 展示了本文的整体结构框架。