
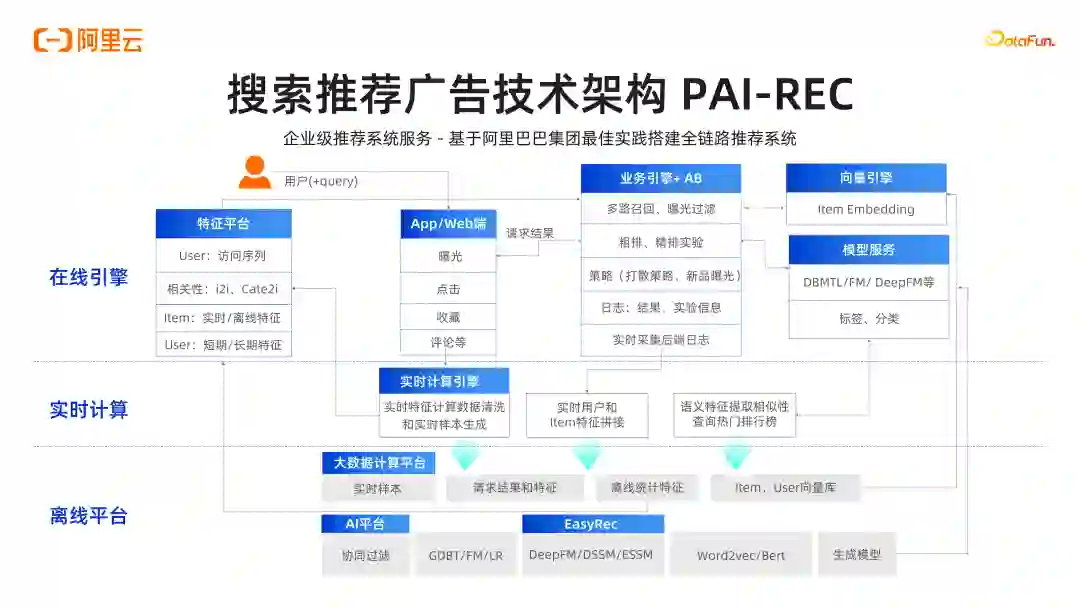
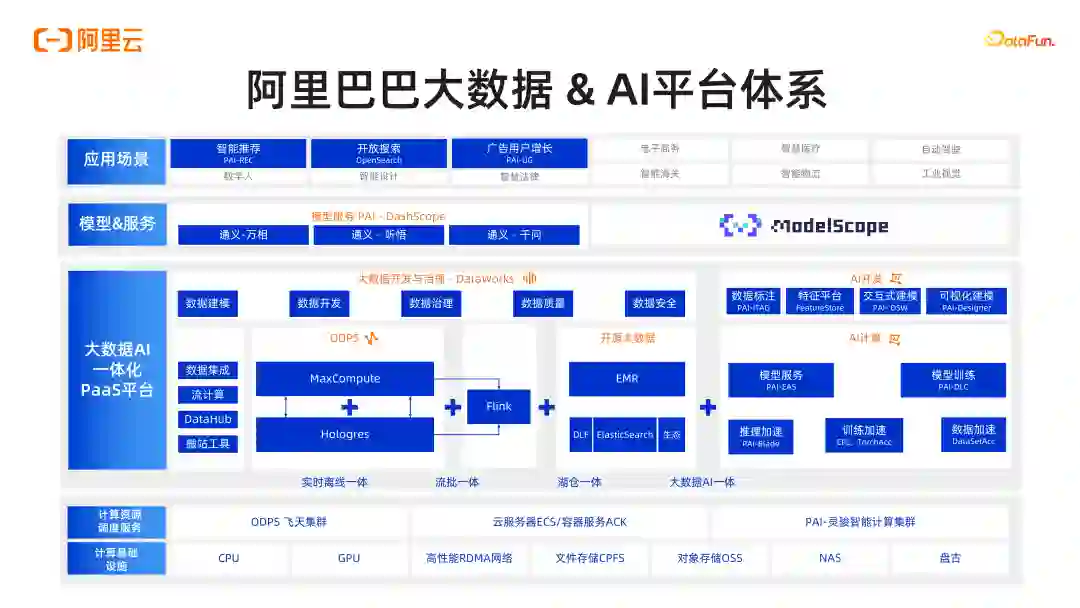
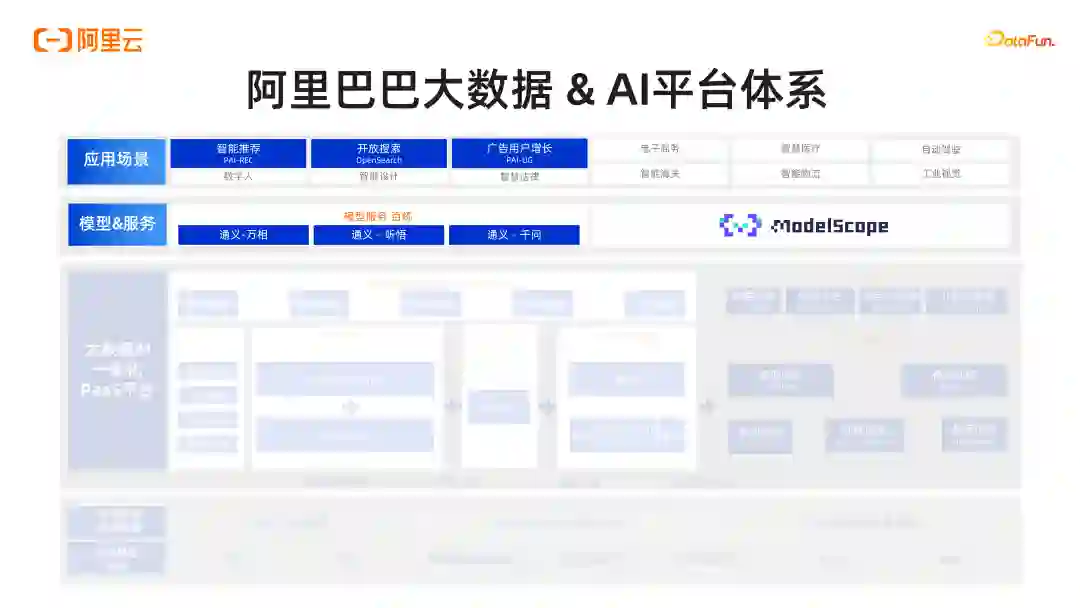
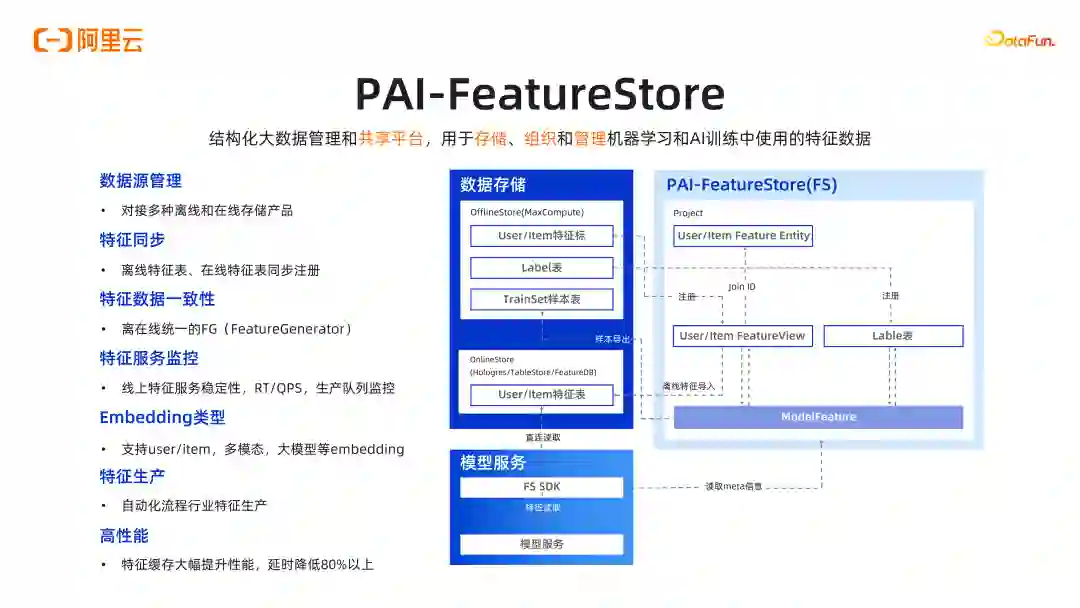
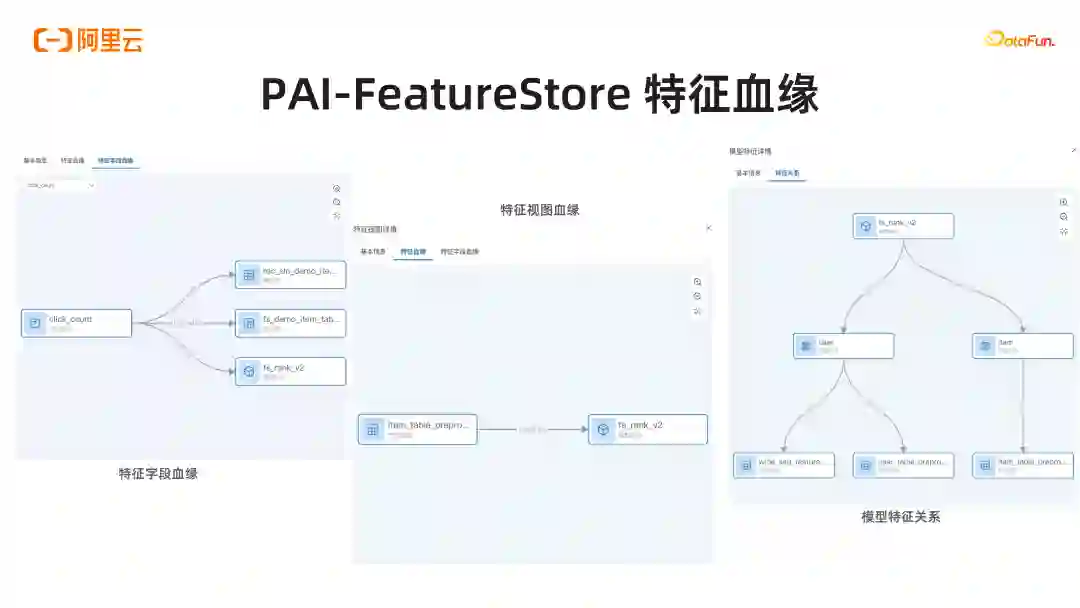
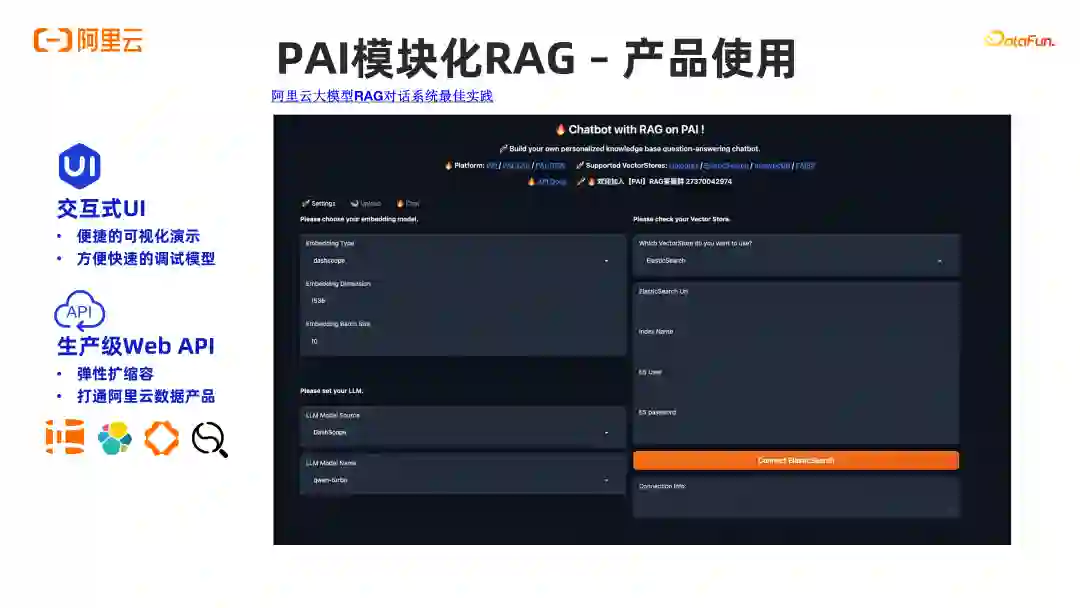
导读 大家好,我是施兴(花名叔宝),来自阿里云机器学习平台 PAI,主要负责产品架构。我们团队主要负责:①搜索推荐,这是我们较为成熟的一个领域;②涉及图像和视频多模态处理,如图像视频打标和 Stable Diffusion 文生图,文生视频等相关工作;③在大模型场景下,阿里有通义系列大模型,我们负责通义的底层平台及相关训练推理优化工作;④进行 RAG 工程链路搭建和大模型评测,包括使用大模型评测大模型。








分享嘉宾
INTRODUCTION

施兴
阿里云
阿里云人工智能平台-PAI产品架构负责人
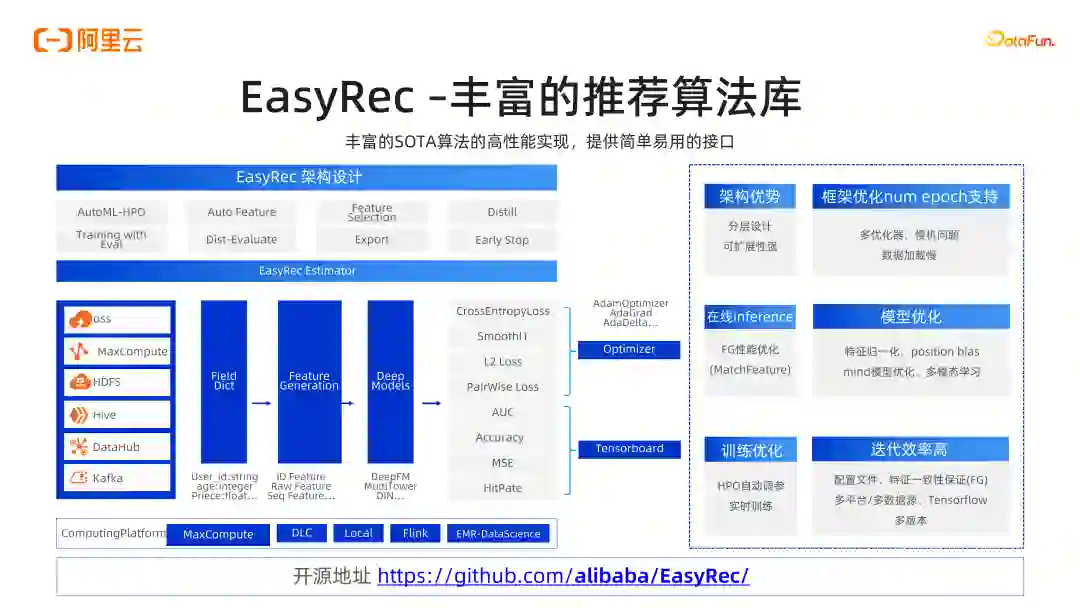
PAI 人工智能平台场景化应用负责人,负责云原生训练推理平台工程以及基于平台之上的智能推荐,用户增长,图像视频生成,大语言模型的算法工程技术。旨在通过提供标准化的 AI 产品方案,更好地服务开发者和企业用户使用云上产品,支持好大规模的 AI 训练和服务,解决客户业务问题。目前开源 EasyRec(推荐),EasyPhoto(AI 写真),EasyAnimate(类 Sora),PAI-RAG 等项目。



