

计算处理能力的提高和数据存储的可负担性正在为机器学习开辟可能的应用范围。机器学习(ML)是一个研究类别,它侧重于从通常从外部设备收集的数据中学习,以建立一个模型,能够预测给定特定输入的正确输出。然而,尽管计算能力和存储能力不断提高,现代技术仍然难以跟上收集的数据量步伐,当这些信息必须传输到中央服务器进行处理时,会导致网络速度减慢。此外,收集的数据可能包含敏感信息,在进行这种传输时,用户的隐私面临风险。为了解决这些问题,联邦学习(Federated ML)正在广泛地获得势头。联邦学习(FL)是一种ML技术,其目的是在持有本地数据样本的多个分散的设备上训练算法,而不进行交换。在联邦学习中,参与训练的设备从服务器上检索模型,用本地数据在本地训练模型,然后将训练好的模型参数传回给服务器。然后,这些本地模型的更新被聚集起来。这个过程要重复多次,直到达到令人满意的精确度。然而,FL也带来了一些缺点。例如,数以百万计的模型参数的通信引入了通信开销。与经典ML相比,另一个区别是数据的异质性和设备能力及网络条件的异质性。目前的技术水平显示了大量试图解决上述问题的算法。不幸的是,流行的FL框架和仿真器使得尝试新算法和在具有典型联邦特征的环境中进行实验变得困难。
这篇论文有两个主要目标。第一个目标是提出一个FL仿真器,作为研究人员和开发者在联邦学习领域的起点。提出的FL仿真器不需要真实的物理联邦网络的存在,因为设备和服务器都是模拟的。易于定制也是所开发的模拟器的主要目标之一:设备和网络特性由用户选择,还有在联邦学习过程的不同阶段使用的技术。一旦模拟完成,就有可能产生结果的图表和统计。
论文的第二个目标是提出一些优化技术,以改善模拟。特别是,我们专注于客户选择技术的阐述,试图减少时间和消耗,同时提高准确性。
架构
仿真器是基于一个协调器-工作器的架构。有一个协调器进程,它是负责模拟中央服务器的行为者。有一个或多个工作器进程同时活动,执行本地步骤。每个工作者都作为一个单独的进程启动,与其他工作者并行运行。协调器和工作器之间的通信是通过它们各自的REST API实现的。所采用的基于协调器-工作器的架构允许将工作器进程分布在不同的设备上,因此可以利用边缘设备的计算能力,而不是将整个计算集中在一个设备上。此外,这种架构是高度可扩展的,因为工作器的数量可以根据可用的设备来增加或减少。在每一轮,协调器为每个选定的设备创建一个作业(JSON对象),包含执行训练或评估步骤所需的信息。一个可用的工作器请求一个作业,在本地完成它,然后将其结果传回。因此,工作器和设备之间不存在1:1的关系。一个工作器完成指定设备的作业。
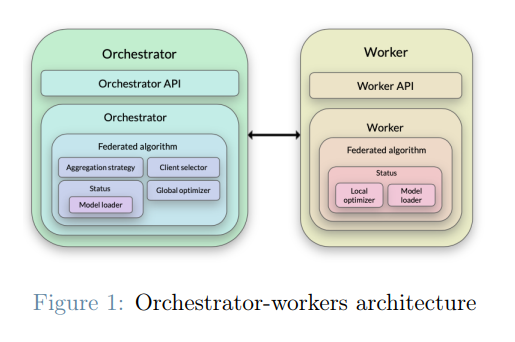
关键组件
图1显示了协调器和工作器的主要组件。下面是对每个组件的简要描述。
-
联邦算法是主要组件,它是最重要的,因为它是访问所有其他子组件的组件。每个联合算法的实现都是由研究人员提出的策略。每个联合算法的实现都分为从协调者角度实施的策略和从工作者角度实施的策略。
-
本地数据优化器是负责选择一个设备在参与一个回合时用于本地更新的样本的组件。
-
全局更新优化器是在训练或评估步骤之前使用,以计算设备必须执行的计算量。更详细地说,全局更新优化器必须为每个选定的设备计算历时数、批量大小和要使用的样本数。
-
模型加载器组件负责提供数据集和用于训练和评估的模型。
-
聚合策略组件定义了由设备计算的本地更新如何被聚合以形成全局模型。
-
客户端选择器是一个优化器,负责为下一个拟合或评估步骤选择设备。




