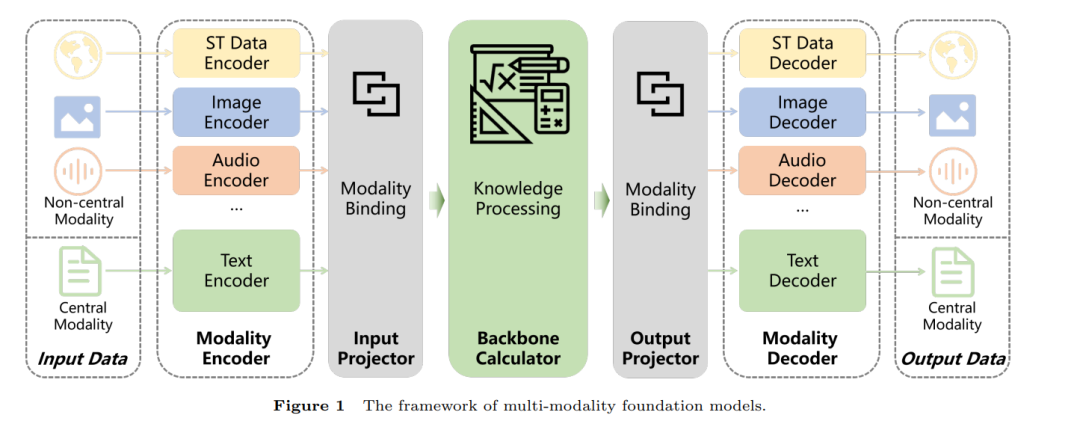
ChatGPT 和其他基于基础模型的产品在人类语言理解方面的出色表现促使学术界和工业界探索如何将这些模型定制化应用于特定行业和应用场景。这一过程被称为领域特定基础模型的定制化,它解决了通用模型的局限性,因为通用模型可能无法完全捕捉领域特定数据的独特模式和需求。尽管领域特定基础模型的定制化非常重要,但目前关于构建领域特定基础模型的综述性论文相对较少,而关于通用模型的资源却非常丰富。为填补这一空白,本文提供了关于定制领域特定基础模型方法的及时且全面的综述。本文介绍了基本概念,概述了通用架构,并综述了构建领域特定模型的关键方法。此外,文章还讨论了可以从这些专门模型中受益的各种领域,并强调了未来的挑战。通过这篇综述,我们希望为来自不同领域的研究人员和实践者开发他们自己的定制基础模型提供有价值的指导和参考。 ChatGPT 以其卓越的表现重新定义了人们对人工智能的理解。作为其核心技术,大型语言模型(LLM)已成为各领域研究人员和从业者改善工作流程的重要工具。通用基础模型通常在大型公共数据集上进行训练,使其能够学习并解决广泛的常见问题。然而,这些数据集并不能完全涵盖某些特定领域的所有专业知识和技术细节。因此,尽管通用基础模型拥有广泛的通用知识,但它们缺乏满足某些特定领域复杂需求所需的深度[1]。因此,针对特定行业需求构建领域特定的基础模型变得尤为重要。领域特定基础模型,也称为行业特定基础模型,是使用特定领域的数据和应用开发的。与通用基础模型相比,它们通过大量领域特定的数据进行训练,能够更准确地理解和生成领域内的专业内容。 随着类似 ChatGPT 的产品的广泛应用,“基础模型”的范围也在逐渐扩大。因此,有必要首先对本文讨论的基础模型进行明确定义,为后续有关领域特定基础模型定制化的讨论奠定基础。本文所提到的基础模型是指包含至少一个通用多模态基础模型中的五个模块之一(稍后详细说明)的神经网络模型。这些模型还具有以下特点:
- 大数据:利用涵盖各种场景的大量数据进行模型训练,为模型提供充足的知识。
- 大参数:模型拥有庞大的参数量,足以将大数据所隐含的知识嵌入到模型的参数中。
- 通用性:模型的数据输入格式和数据处理流程可以适应不同任务场景的需求。
- 泛化性:模型表现出一定的泛化能力,能够在未知数据域中也表现良好。
根据基础模型能够处理的模态数量,它们可以分为单模态基础模型和多模态基础模型,如表 1 所示。
在构建领域特定基础模型的过程中,会出现一系列挑战,尤其是在数据获取和预处理阶段。例如,所需的领域特定数据可能不是开源或容易获取的,因为它通常具有高度的保密性。此外,领域特定数据的模态可能与用于训练通用基础模型的模态不同,这使得现有模型难以适应处理这些数据。再者,领域特定数据收集的环境可能与预训练数据集的环境有很大差异,导致预训练模型不熟悉这些领域特定的知识。 总的来说,构建领域特定的基础模型既具有挑战性,又成本高昂,并且对技术安全有着重大影响,但预计会带来很高的经济效益。因此,有必要对构建这些模型的方法进行深入的综述和探索,为研究人员和实践者提供指导。 值得注意的是,之前的综述文章主要集中在通用基础模型的发展上。最近,虽然有几篇综述文章开始探讨基础模型的领域特定适应性,但在文献中仍然存在一个重要的空白,即对适用于所有模态的基础模型适应策略进行全面探索,涵盖语言、视觉或任何单一模态之外的各个应用领域。我们在表 2 中总结了关于基础模型的代表性综述或综述文章。本文旨在通过介绍构建领域特定基础模型的关键方法,向有兴趣构建领域特定基础模型应用的研究人员和实践者提供方法论参考。此外,本文还将讨论实际案例和未来的研究方向。