

经典自然语言处理(NLP)的进展主要受到机器学习的推动,这种机器学习通过优化在大规模任务特定的标记示例集上的系统来实现。这种学习范式限制了机器在处理新任务时与人类具有相同能力的能力,因为人类通常可以通过一些示例和任务说明来解决未知任务。此外,对于新任务,我们可能没有机会准备大量的任务特定示例,因为我们无法预测下一个需要解决的任务以及为此任务进行复杂标注的需求。因此,任务说明充当了一种新颖且有前景的监督资源。本教程呈现了一系列以任务指令为驱动的多样化NLP研究,试图回答以下问题:(i) 什么是任务指令?(ii) 如何创建数据集和评估系统的过程是如何进行的?(iii) 如何编码任务指令?(iv) 有时候为什么会有一些指令效果更好?(v) 在以LLM为驱动的任务遵循中还存在哪些关切?我们将讨论一些处理这些挑战的前沿研究方向,并通过勾画进一步研究的方向来总结本教程。

介绍(幻灯片) 为什么“从指令中学习”很重要? 什么是“指令”?(面向LLM的指令与面向人的指令) 具有代表性的指令遵循研究 指令遵循的数据集和评估(幻灯片) 人工生成数据集LLM-generated数据集 自动评价与人工评价 方法——促使(幻灯片) 人类启发的提示技术(推理、增强、验证、反馈和细化) llm驱动的自动提示工程 方法论——llm中的对齐 人类的价值观表现为多种形式 LLM不同阶段的对齐技术(预训练,监督微调,基于奖励的调优,测试时间,部署,工具使用) 指令遵循的挑战和问题 llm处理否定时的逆标度律 llm很难像人类一样掌握指令 对抗性指令攻击 结论和未来方向

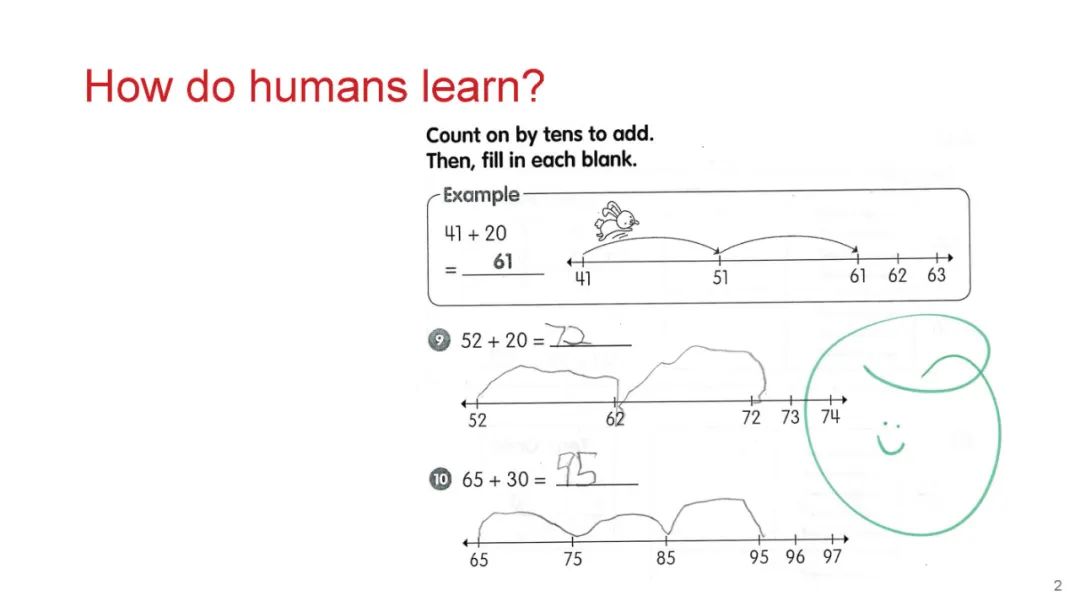
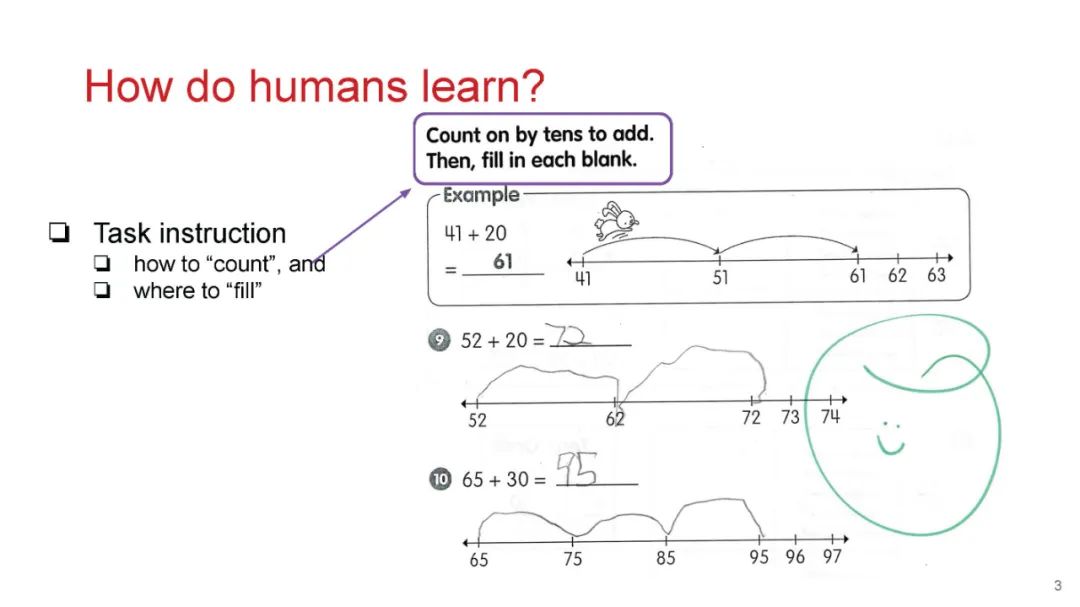
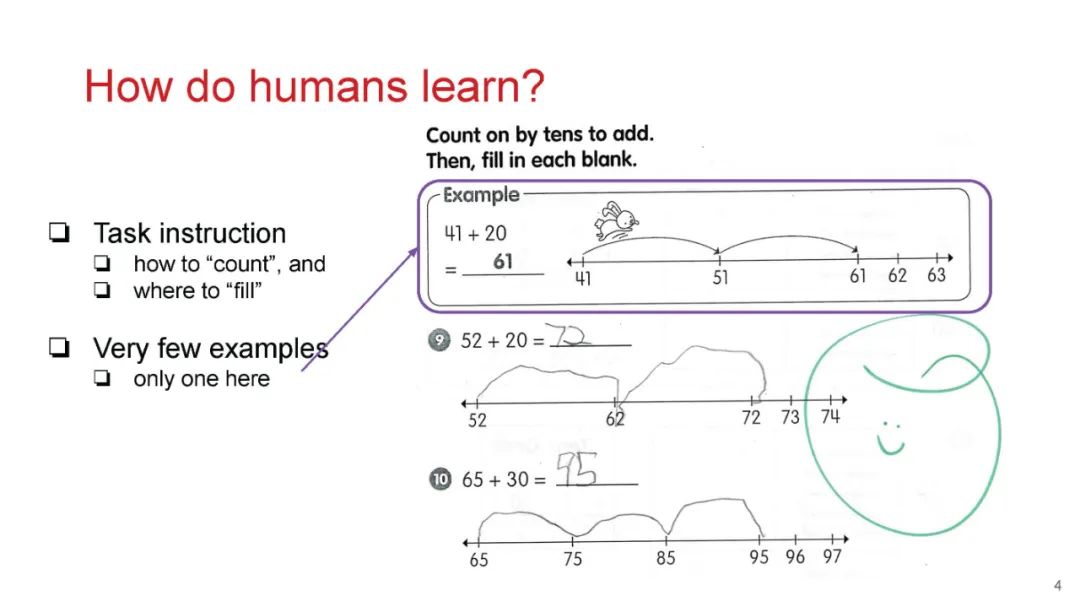


成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日