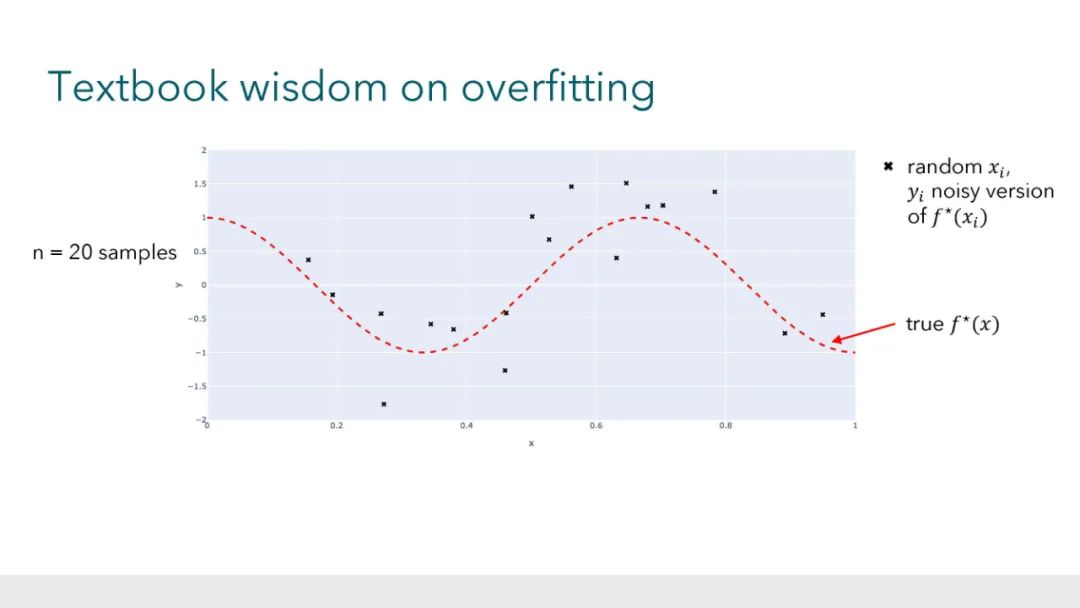
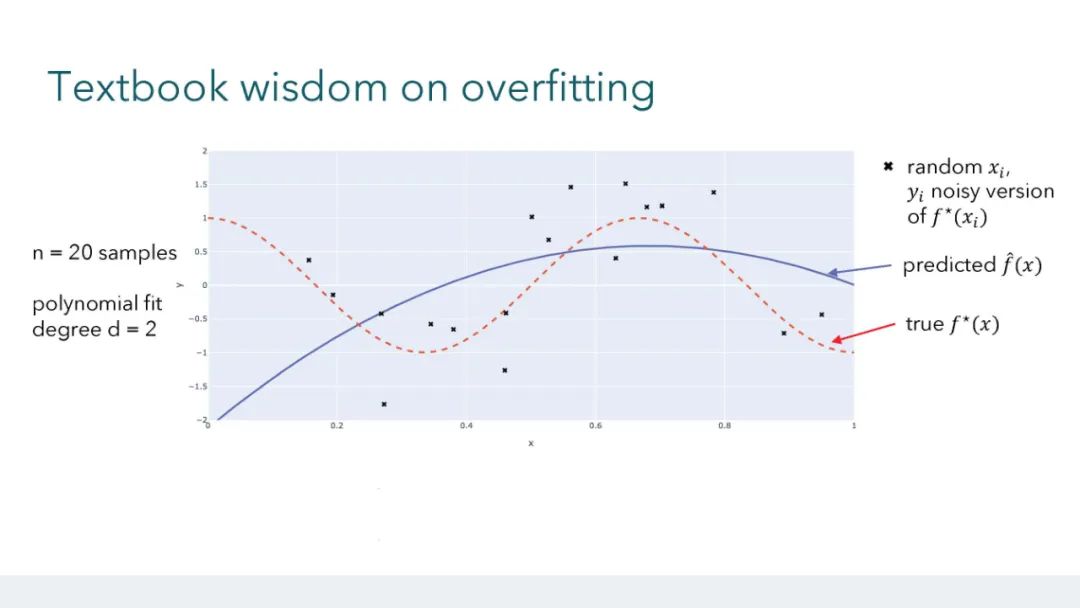
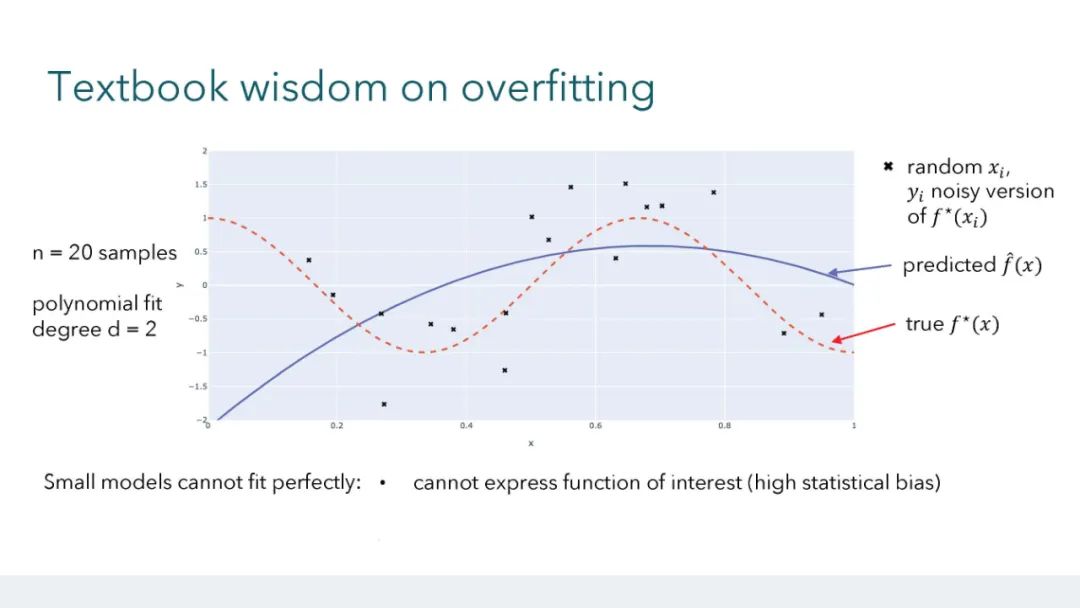
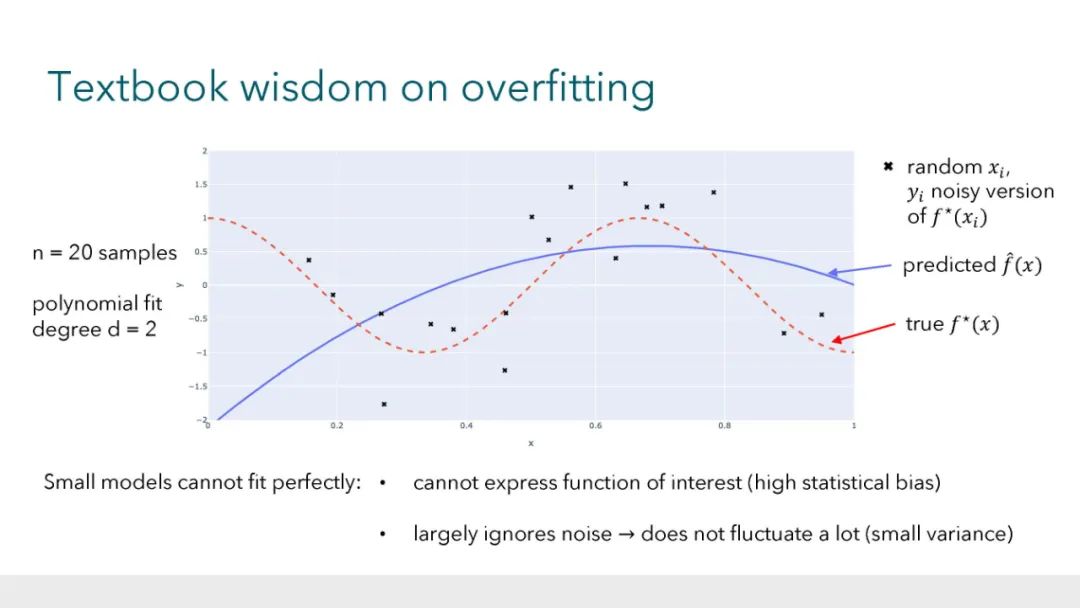
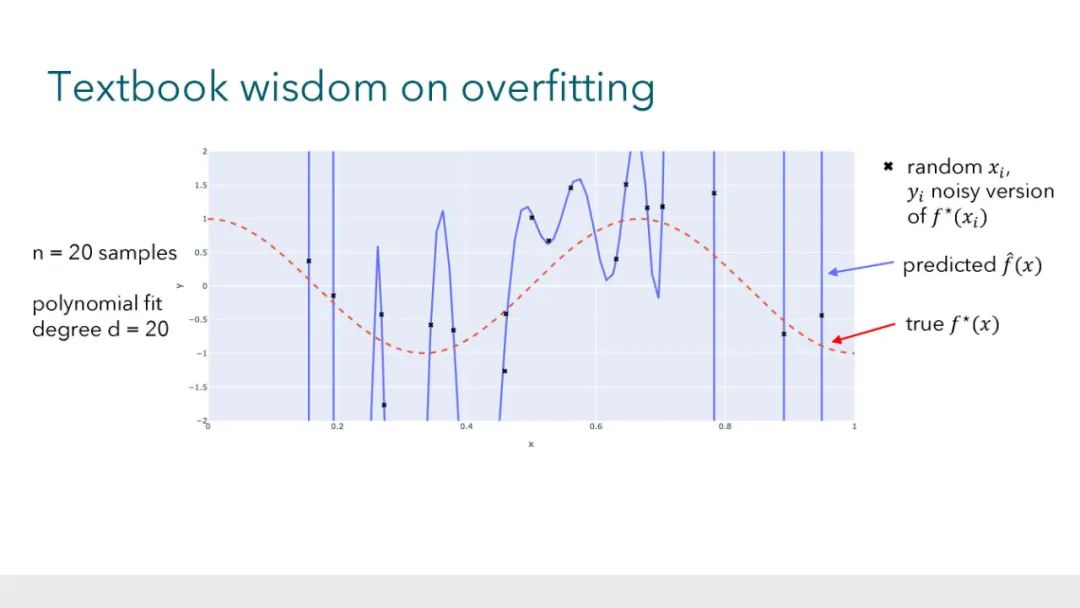
大型的、过度参数化的模型(如神经网络)现在是现代机器学习的主力。这些模型通常在有噪声的数据集上训练到接近于零的误差,同时很好地泛化到未见过的数据,这与教科书中关于过拟合风险的直觉形成了对比。与此同时,近乎完美的数据拟合可能在鲁棒性、隐私和公平性的背景下存在严重的问题。由于过度参数化,经典的理论框架几乎没有为导航这些问题提供指导。因此,发展关于过拟合和泛化的新直觉至关重要,这些直觉反映了这些经验观察。在本教程中,我们将讨论学习理论文献中的最新工作,这些工作为这些现象提供了理论见解。 参考文献: * Hastie, Trevor and Montanari, Andrea and Rosset, Saharon and Tibshirani, Ryan J (2022). Surprises in high-dimensional ridgeless least squares interpolation. Annals of Statistics. * Bartlett, Peter L and Long, Philip M and Lugosi, Gabor and Tsigler, Alexander (2020). Benign overfitting in linear regression. PNAS. * Muthukumar, Vidya and Vodrahalli, Kailas and Subramanian, Vignesh and Sahai, Anant (2020). Harmless interpolation of noisy data in regression. IEEE Journal on Selected Areas in Information Theory. * Wang, Guillaume and Donhauser, Konstantin and Yang, Fanny (2022). Tight bounds for minimum ℓ1-norm interpolation of noisy data. In: AISTATS. * Donhauser, Konstantin and Ruggeri, Nicolo and Stojanovic, Stefan and Yang, Fanny (2022). Fast rates for noisy interpolation require rethinking the effects of inductive bias. In: ICML. * Hsu, Daniel and Muthukumar, Vidya and Xu, Ji (2021). On the proliferation of support vectors in high dimensions. In: AISTATS. * Muthukumar, Vidya and Narang, Adhyyan and Subramanian, Vignesh and Belkin, Mikhail and Hsu, Daniel and Sahai, Anant (2021). Classification vs regression in overparameterized regimes: Does the loss function matter?. Journal of Machine Learning Research. * Frei, Spencer and Vardi, Gal and Bartlett, Peter and Srebro, Nathan and Hu, Wei (2023). Implicit Bias in Leaky ReLU Networks Trained on High-Dimensional Data. In: ICLR. * Frei, Spencer and Vardi, Gal and L., Peter and Srebro, Nathan (2023). Benign Overfitting in Linear Classifiers and Leaky ReLU Networks from KKT Conditions for Margin Maximization. In: COLT. * Xu, Xingyu and Gu, Yuantao (2023). Benign overfitting of non-smooth neural networks beyond lazy training. In: AISTATS.