摘要| 视频理解是计算机视觉领域中最具挑战性的前沿课题之一,它要求模型具备对复杂时空关系、长期依赖以及多模态证据进行推理的能力。近期兴起的视频多模态大模型(Video-LMM),通过将视觉编码器与强大的基于解码器的语言模型相结合,已在视频理解任务中展现出卓越的性能。然而,使这些模型从基础感知系统进化为复杂推理引擎的关键阶段——后训练(post-training),在现有文献中仍呈现出碎片化的局面。 本综述首次对Video-LMM的后训练方法进行了系统而全面的研究,涵盖三个核心支柱: (1)带有思维链(chain-of-thought)机制的有监督微调(SFT); (2)基于可验证目标的强化学习(RL); (3)通过增强推理计算的测试时扩展(TTS, Test-Time Scaling)。 我们提出了一个结构化的分类体系,用以阐明这些技术的角色、相互联系及其在视频任务中的特定适配方式,重点讨论了诸如时间定位、时空对齐、长视频处理效率与多模态证据融合等独特挑战。通过对代表性方法的系统分析,本文总结了关键的设计原则、实践洞见与评测流程,同时识别出在奖励函数设计、可扩展性以及性能-成本优化方面的若干开放性问题。 此外,我们整理了用于评估后训练效果的核心基准测试、数据集与评测指标,以支持更为严格的性能检验。本综述旨在为研究者与实践者提供一个推进Video-LMM能力演进的统一框架。更多相关资源与更新可访问: 🔗 https://github.com/yunlong10/Awesome-Video-LMM-Post-Training!
1. 引言
“一鲸落,万物生。” ——现代谚语,灵感源自《野性的修行》[1] 近年来,多模态大模型(Large Multimodal Models, LMMs) [2–6] 正在迅速从简单的问答系统演进为具备可解释长链式思维(Chain-of-Thought, CoT)推理能力的通用问题求解框架 [7]。其中,视频理解作为计算机视觉中最复杂、最全面的研究方向之一,涉及复杂的时空关系、事件因果性与长期记忆机制,天然需要强大的语言推理与任务接口能力 [8]。因此,以解码器为中心架构(decoder-centric architecture)的视频多模态大模型(Video-LMM)逐渐成为主流范式 [8, 9]。此类系统通常以强大的大语言模型(LLM)作为推理引擎,使用视频编码器(video encoder)提取视觉表征,再通过投影模块(projection module)将视觉特征对齐至LLM的token嵌入空间,从而实现指令理解与答案生成,在初始化性能与泛化能力上均表现突出 [8]。 视频语言建模(video-language modeling)经历了三次重要的范式转变: (1)CNN+RNN时代,聚焦于利用循环神经网络进行时间特征聚合 [10]; (2)基于Transformer的视频模型时代,尤其是BERT式/仅编码器结构,强调双向编码下的跨模态对齐与检索 [11, 12]; (3)当前视频编码器 + 解码器式LLM架构,突出语言模块的通用性与可组合性,同时最大化复用预训练LLM的知识与推理能力 [8, 9, 13]。 这种架构的核心优势在于:语言领域中依托互联网规模的自监督学习,通过下一个token预测这一统一目标,大规模涌现出知识、推理与接口能力;而视觉领域仍缺乏可高效处理互联网规模原生视频数据的自监督学习机制。尽管已有工作探索端到端联合建模视觉与语言的原生多模态方法 [14, 15],但其在计算效率与工程可复用性方面尚未超越当前的“分而治之”策略。 在这一总体框架下,后训练(post-training)阶段成为决定Video-LMM能否从基础感知跃升为高级推理的关键环节。如图1所示,后训练主要包括三个部分: (i) 有监督微调(Supervised Fine-Tuning, SFT):结合思维链(CoT)与推理风格蒸馏,用于引导模型形成推理格式与任务跟随能力 [16–18]; (ii) 强化学习(Reinforcement Learning, RL):从RLHF、PPO、DPO发展到R1-style/GRPO [19]等新方法,摆脱了偏好数据与显式奖励模型的依赖,通过可验证目标与系统性探索实现更强的推理与自我纠错能力 [20–23]; (iii) 测试时扩展(Test-Time Scaling, TTS):通过增强推理计算来提升可靠性,包括推理样本增强、投票机制、自洽性检查、外部验证器及多路径搜索等 [24–26]。 这一演进路线与LLM社区的后训练发展保持高度一致,在理论原则与工程实践上具备较强的可迁移性。 然而,将这些范式适配于视频场景会面临显著不同于静态图文任务的挑战: * 时间定位(Temporal Localization):模型需生成时间上精确锚定至特定片段的答案 [27, 28]; * 时空对齐(Spatiotemporal Grounding):要求模型在空间与时间维度上保持对目标、部件及动作的一致追踪 [22, 29]; * 长视频理解(Long Video Understanding):需采用复杂的采样策略、自适应路由、层次化观看协议及高效缓存机制 [30, 31]; * 多模态证据融合(Multimodal Evidence Integration):要求模型联合推理视频帧、字幕文本、音频转录及外部知识 [32–34]。
这些特征催生了视频特定的后训练策略: * 在RL框架中引入可验证的时空奖励(如tIoU、区域一致性指标); * 设计TTS方法,引导模型自主选择关键信息帧,执行分阶段观看、多轮反思与自我校正; * 将多样化任务(问答、时间定位、时空对齐)统一至一致的对齐与优化框架下,构建**“观看—思考—定位—回答”**的层级式推理流水线 [24, 27, 28]。
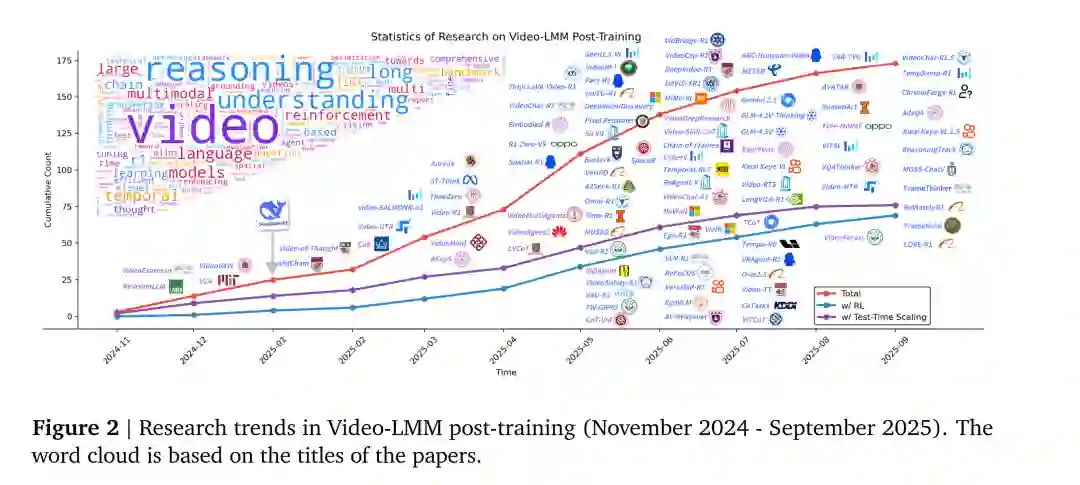
近期研究成功地将GRPO/R1式强化学习与扩展推理的TTS机制融合进视频理解任务中(见图2)。部分工作侧重于可验证奖励设计以增强时间推理与定位 [27, 28];部分扩展至联合时空对齐 [22];亦有研究聚焦长视频场景的高效训练与推理 [30, 35],以及支持交互式观看与多轮证据累积推理的范式 [24, 36, 37]。这一系列工作验证了将LLM后训练范式迁移至视频理解的可行性,并揭示了数据构建、奖励鲁棒性、评测标准化及成本性能优化等共同挑战,凸显出从后训练视角系统审视Video-LMM推理方法的必要性。 因此,本综述聚焦于Video-LMM的后训练研究,系统梳理了SFT、RL与TTS三大关键技术及其在视频场景下的特定适配方案。我们总结了代表性方法的设计原则与工程洞见,并在统一的评测与报告标准下探讨未来研究方向。 本文主要贡献如下:
全面综述 Video-LMM的后训练方法,涵盖SFT、RL与TTS三大核心优化组成部分; * 提出系统化分类体系,明确各类后训练技术的功能角色与相互关系,并总结其开放问题与未来方向; * 提供实践指南,汇总用于评估Video-LMM后训练效果的关键基准、数据集与指标。
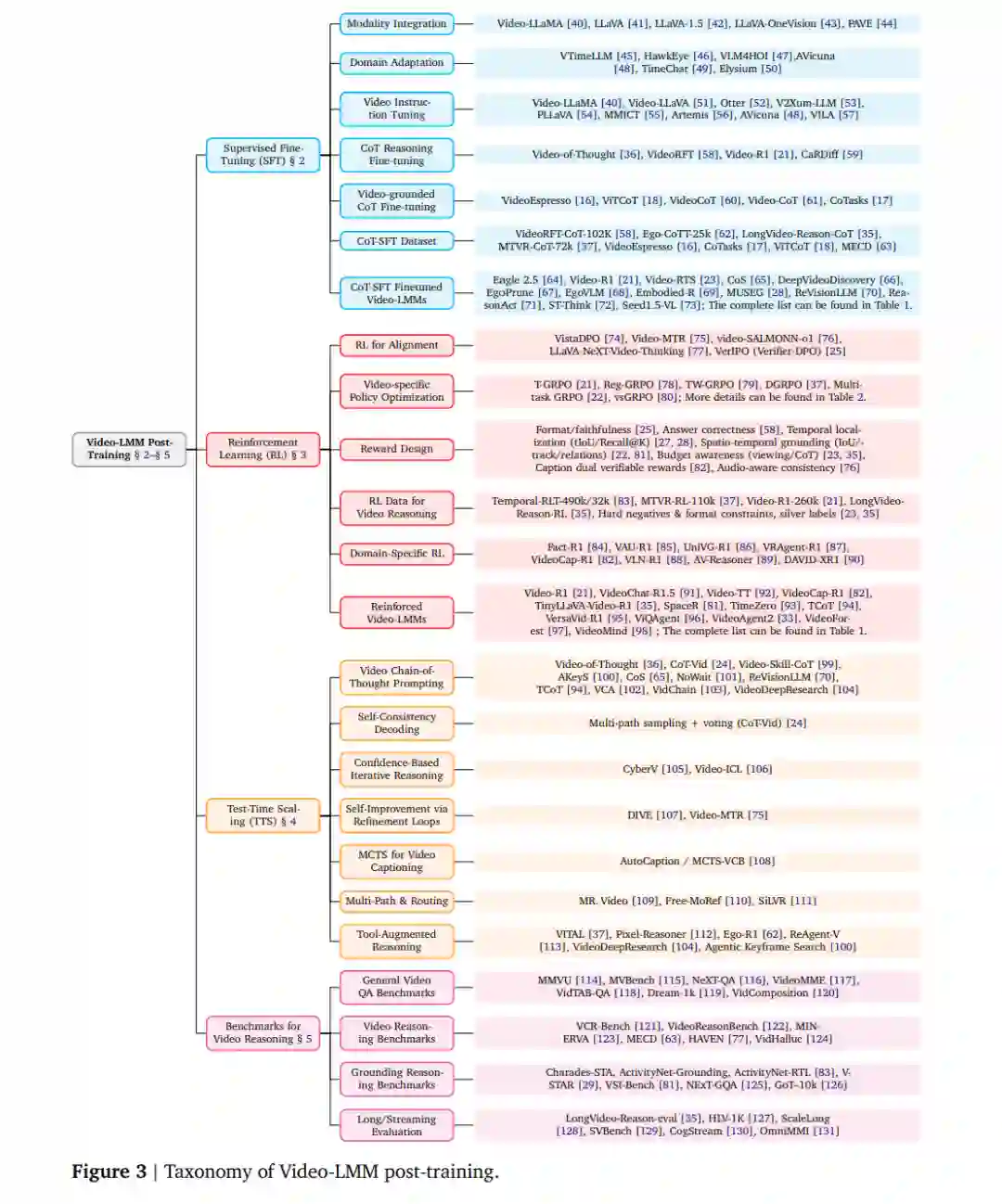
相关综述: 现有研究已探讨了基于大语言模型的视频理解 [8, 9, 38, 39]、多模态思维链推理 [7] 以及LMM中的强化学习方法 [20]。然而,本综述的独特之处在于——系统化组织并分析针对Video-LMM的后训练方法论,在统一框架下综合讨论SFT、RL与TTS三大方向。 论文结构: 第2节探讨SFT及其在Video-LMM中的思维链微调策略;第3节回顾基于LLM的RL基础,系统分析用于视频推理的R1式RL算法的模型结构、数据准备、优化策略及策略/奖励设计;第4节研究视频特定的TTS方法,重点讨论自适应观看机制、多路径推理与验证架构;第5节综述数据集、基准与评测指标;第6节展望未来研究方向。更多资源与更新请参阅: 🔗 https://github.com/yunlong10/Awesome-Video-LMM-Post-Training