

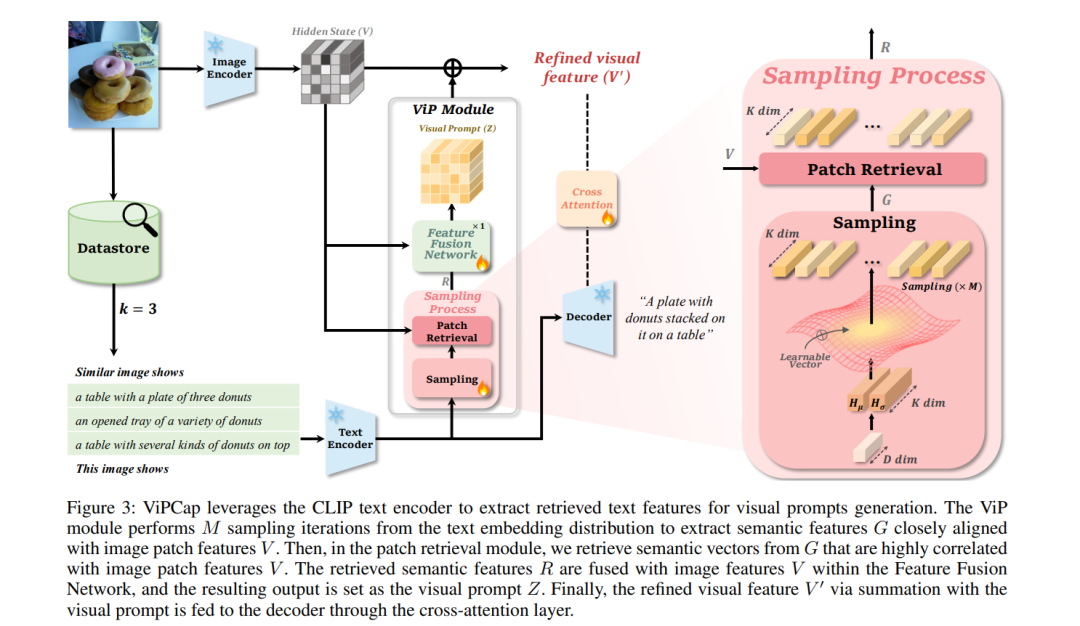
最近的轻量级图像描述模型使用检索数据,主要集中在文本提示上。然而,以往的研究仅将检索到的文本作为文本提示,视觉信息仅依赖于CLIP视觉嵌入。因此,存在一个问题,即提示中固有的图像描述未能充分反映在视觉嵌入空间中。为了解决这一问题,我们提出了ViPCap,一种用于轻量级图像描述的新型基于检索的文本视觉提示。ViPCap利用检索到的文本和图像信息作为视觉提示,增强模型捕捉相关视觉信息的能力。通过将文本提示映射到CLIP空间,并生成多个随机高斯分布,我们的方法利用采样探索随机增强的分布,并有效地检索包含图像信息的语义特征。这些检索到的特征被集成到图像中,并作为视觉提示,进而在COCO、Flickr30k和NoCaps等数据集上提高了性能。实验结果表明,ViPCap在效率和有效性上显著超越了以往的轻量级描述模型,展示了其作为即插即用解决方案的潜力。源代码可在https://github.com/taewhankim/VIPCAP找到。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
145+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
145+阅读 · 2023年3月29日