
导读 本文将介绍小米数据中台部门在销售数仓建设方面的实践。文章将从小米销售数仓的发展历程开始,介绍其定位、内容、作用、规模等,并分享数仓建设常用的维度建模和分层理论,以及小米销售数仓的架构演进和能力沉淀。
****文章将围绕以下六个内容展开:****1. 销售数仓介绍2. 数仓建设理论3. 销售数仓架构介绍4. 数仓能力层5. 总结与展望6. 问答环节 分享嘉宾|沈子阳 小米 高级软件研发工程师编辑整理|天天内容校对|李瑶出品社区|DataFun
01****销售数仓介绍首先介绍下小米销售数仓,包括发展历程、销售数仓定义、数据获取使用、销售数仓的内容和规模。在 2019 年前,小米的中国区、国际部等业务数据团队在进行独立的数仓建设,这个时期是烟囱式的开发。随着业务飞速发展,在集团技术委 ABC(AI、Big data、Cloud)策略的指导下,开始建设统一的销售数仓。在 2020 年,完成了离线销售数仓的建设,同时在筹备实时数仓的建设。2021 年,实时数仓建设完毕,随着后续的业务和技术升级,进入了迭代优化和数据应用阶段。 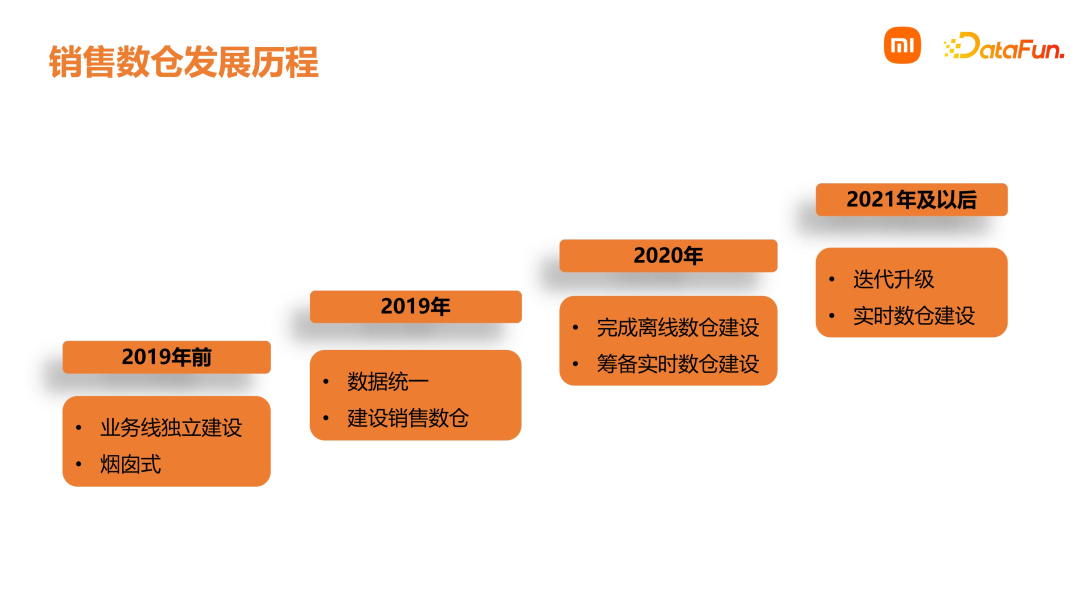
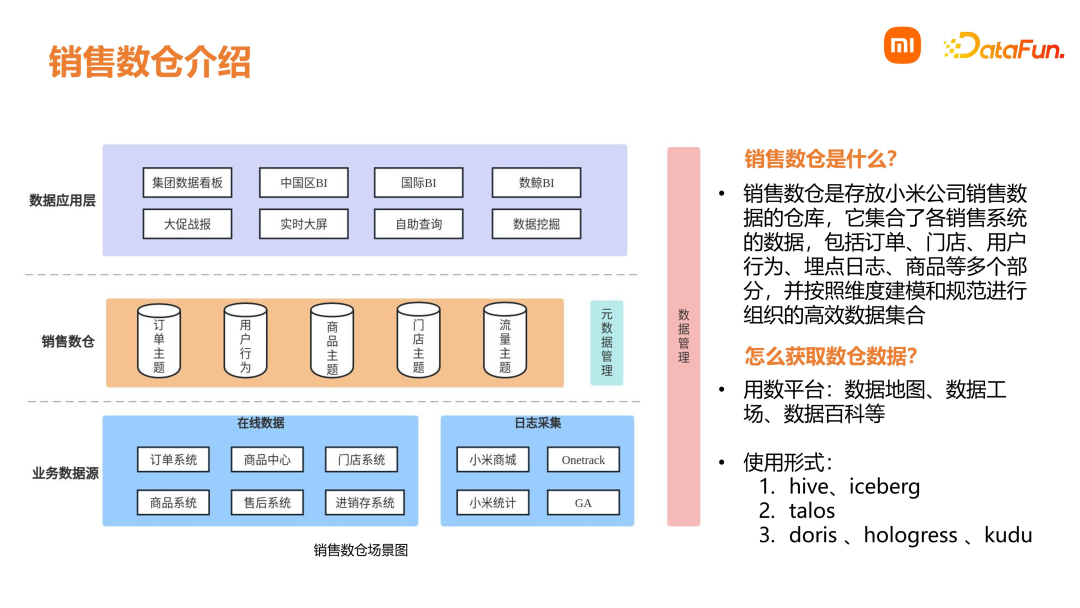
- 用户通过数据地图进行查询,数据地图中会显示集群、存储介质、表详情、血缘等。
- 通过数据工场,可以进行数据查询以及任务的开发部署等。
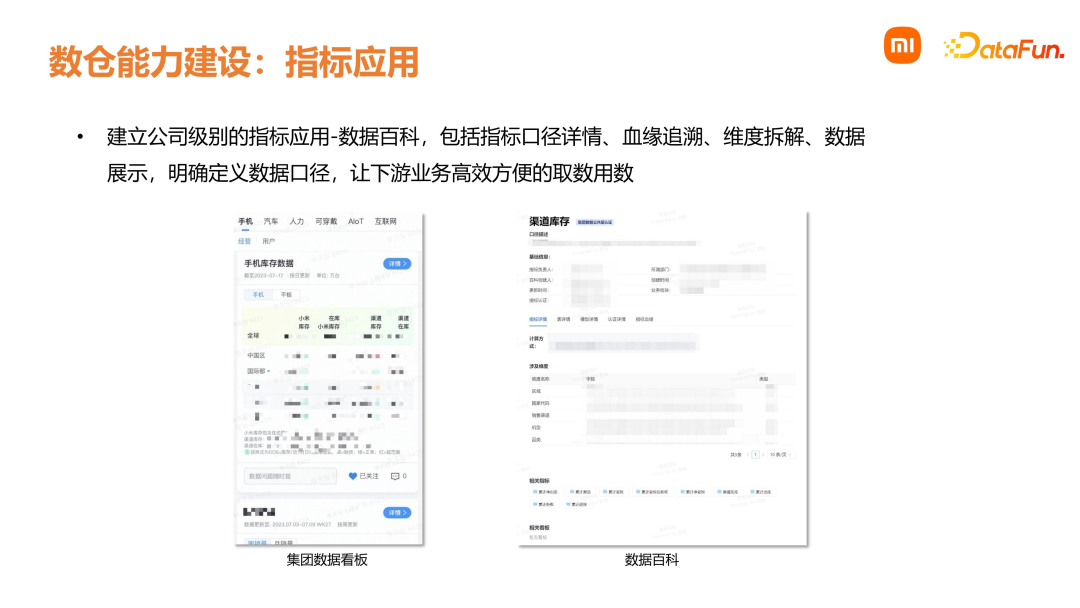
- 通过数据百科,对数据指标进行管理录入和使用。 数仓的使用形式有多种,包括传统的离线 Hive、数据湖 Iceberg、实时消息队列 Talos、OLAP 引擎、即时查询等。销售数仓的目标是为公司提供准确好用的销售数据。在区域方面,包含全球的业务;在品类方面,包含手机、笔记本、大家电、生态链等;在渠道方面,包含小米网、商城、米家、三方平台等。我们的日单量在千万级别,每天会处理上亿条日志数据。
02****
 02****
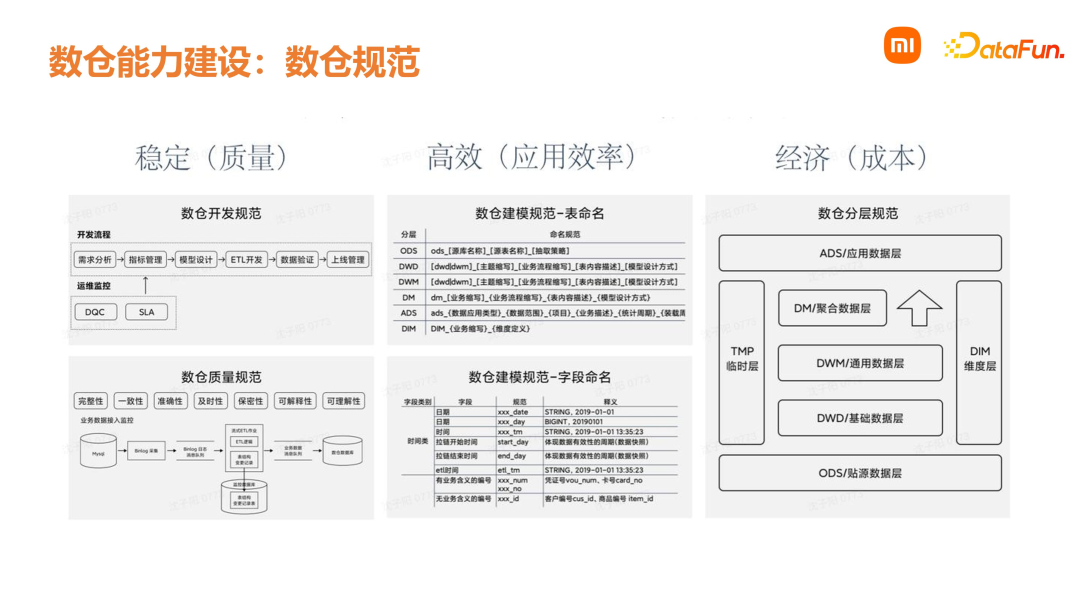
02****数仓建设理论****在进行数仓建设时,首先是梳理业务,找到核心业务逻辑,对业务过程进行认识和理解,并在数据库中找到相关的数据表。在此基础上,站在更高维度对业务流和数据流进行汇总和分类,划分好主题域,便于后续的管理。然后进行事实表和维表的梳理,借助数据百科进行指标梳理,以具体的业务为核心,指标与维度同等重要。接下来对数仓进行建模,按照维度建模方式组织数据,在这个过程中需要注意分层和规范。最后就是物理实现,这个环节重点关注的是开发规范、交付物、质量等 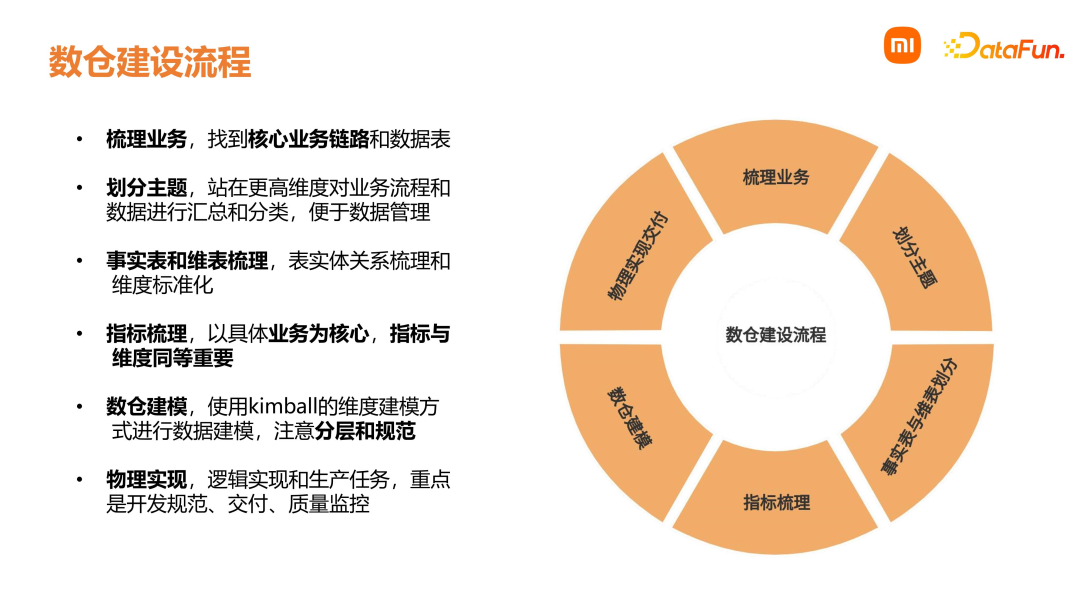
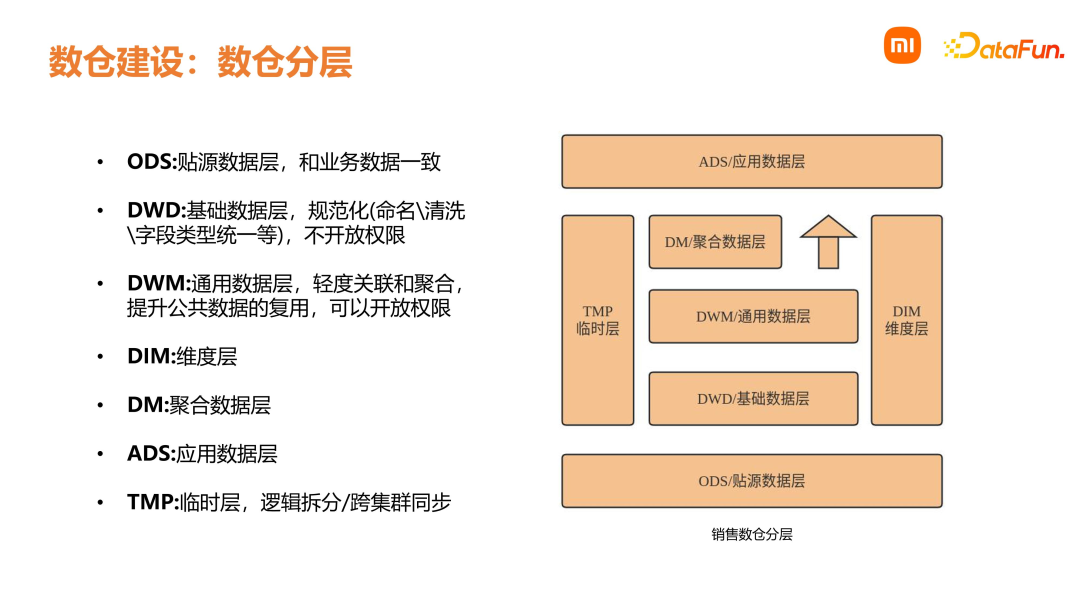

1. 高内聚低耦合将业务相近的数据设计为一个逻辑模型或者物理模型。例如订单有很多来源,包括小米商城、小米网、有品商城以及三方数据等。在 DW 层会整合为同一个订单表,同时会对一些缺失字段进行默认处理,保证所有来源的数据最终在 DW 层是统一的,从而实现高内聚。订单和物流被划定为不同的主题,以减少其耦合度。 2. 公共逻辑下沉前面介绍数仓分层时,指出公共逻辑要尽量放在 DWM 层处理,对下游使用方尽量屏蔽复杂的业务逻辑,从而做到口径统一。例如在订单处理过程中,会有很多无效的订单,识别无效订单的核心逻辑在 DWM 层,这样下游业务方就可以直接使用。 3. 成本与性能平衡一定的数据冗余,虽然可能带来成本增加,但查询性能可以得到提高。例如在区域维表设计中,针对国家、省份、城市、区县,通过一个区域层级字段将其分类,虽然数据是冗余的,但用户使用起来会比较方便,并且查询更快速。

4. ****一致性在数仓建模过程中,要保证字段含义和命名规范是统一的,这样可以降低理解和使用的成本。 5. ****数据可回滚要保证数据可回滚,在不同时间去执行数仓的调度,针对历史数据计算出的结果是一致的。那我们是如何进行指标管理呢?在小米内部会通过 OSM 模型,根据公司的目标和策略,通过数仓中的度量值进行考核。 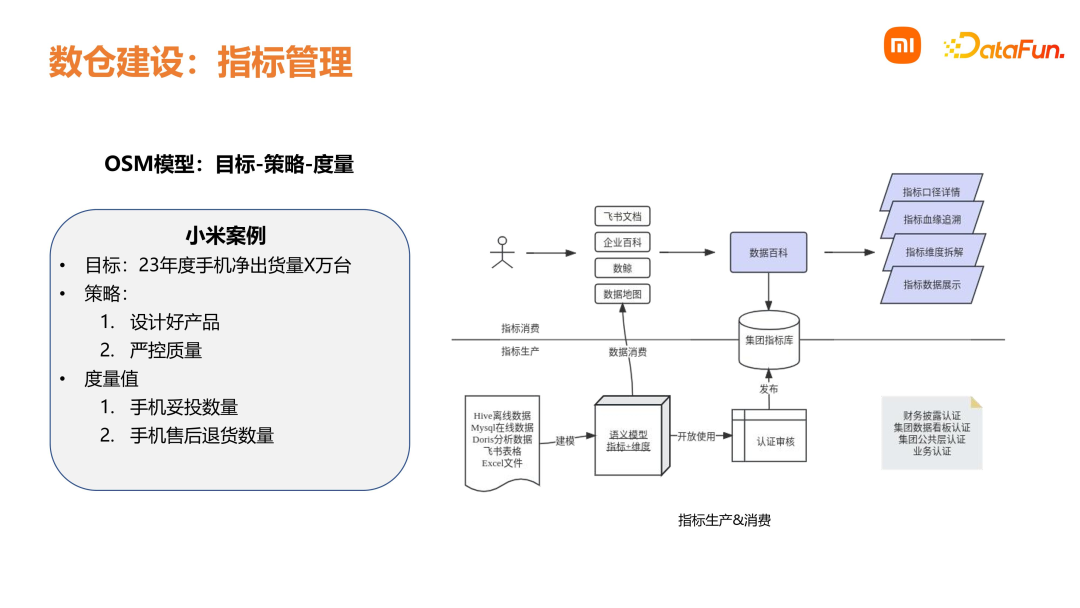
销售数仓架构介绍****
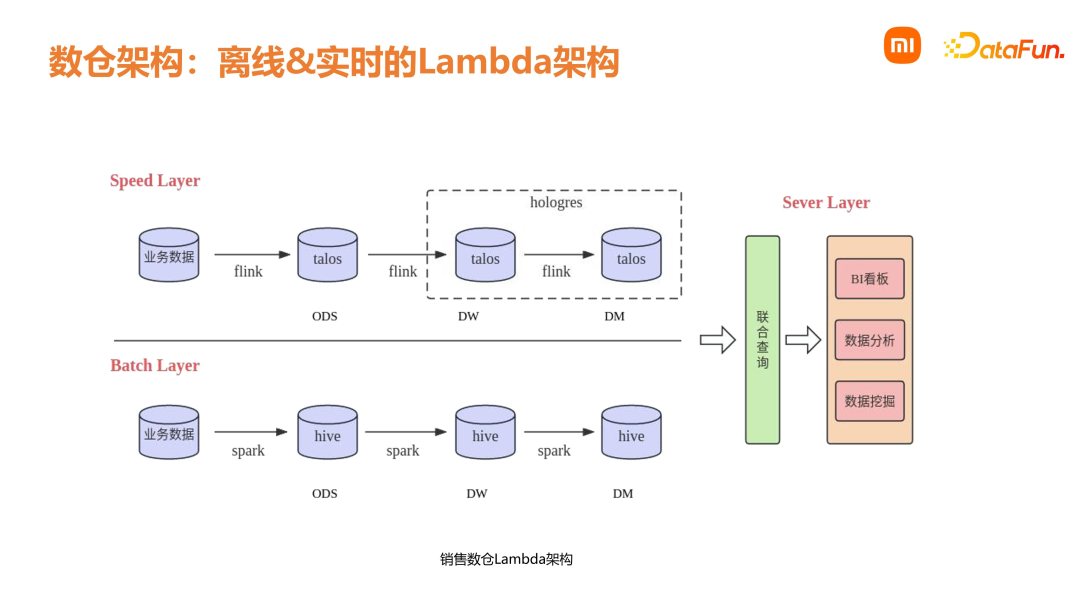
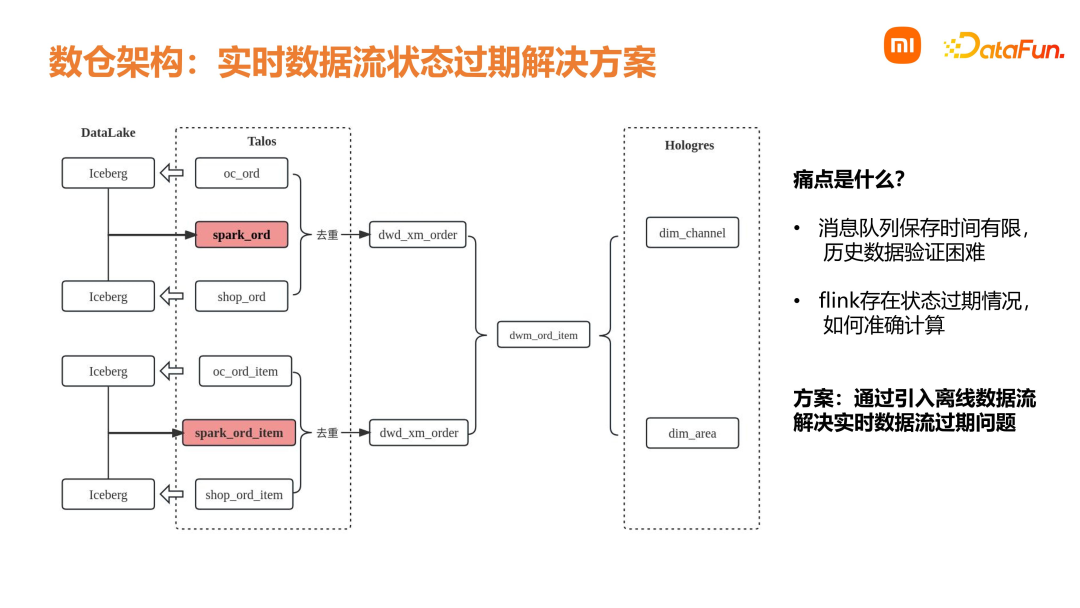

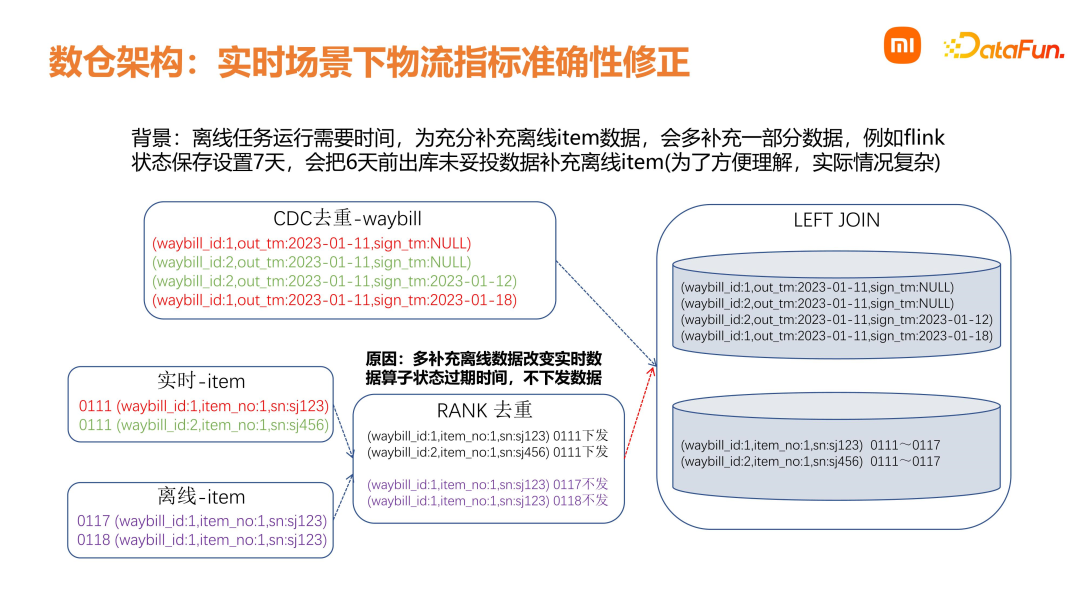
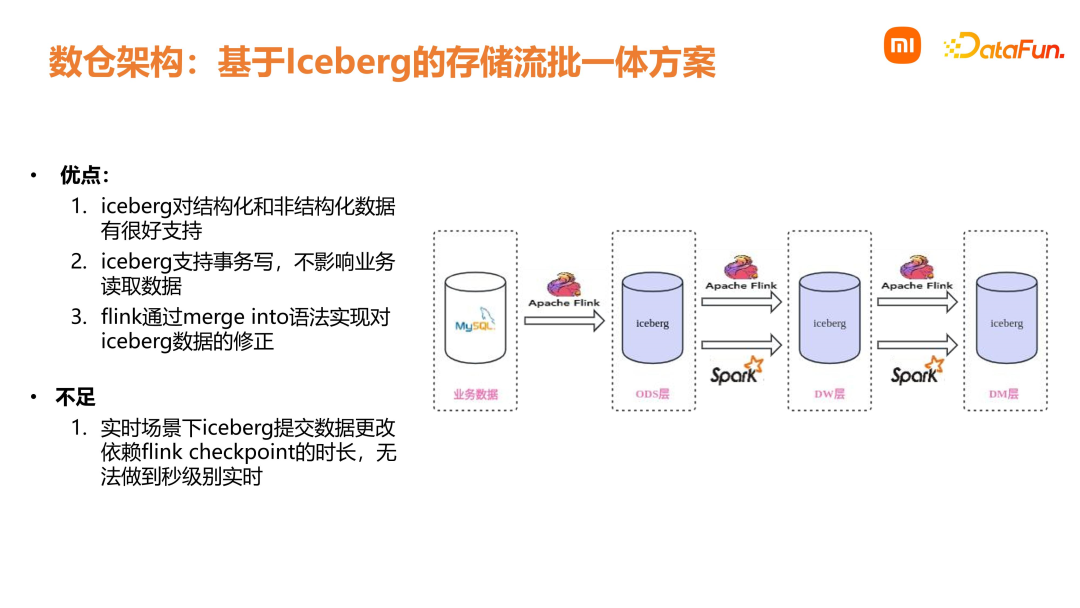
数仓能力层下面介绍销售数仓能力层,即数仓经过一定的建设和升级,逐渐沉淀下来的一些公共能力。首先是统一的数据架构。准实时数据需求是基于 Iceberg 的分钟级流批一体处理方案;在实时方面,是基于 Flink + Talos 的秒级处理方案及离线批处理方案。 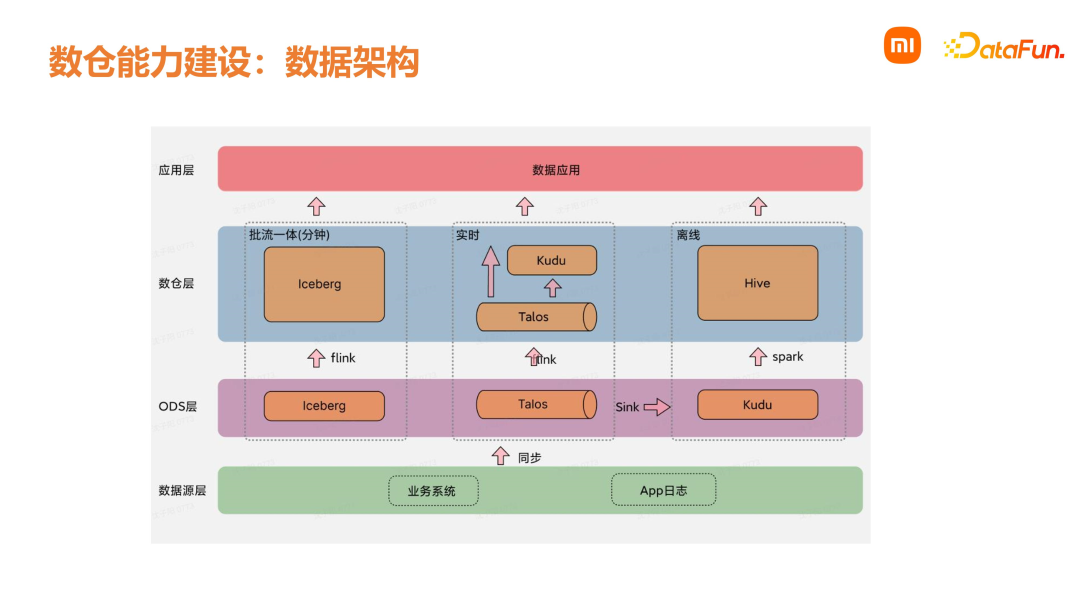

总结与展望最后进行一下总结和展望。经过几年的建设和应用,我们已经基本建成了离线销售数仓,公司的运营和管理层都在深度且广泛的使用销售数仓数据。团队内部沉淀了数据架构和数仓能力规范,会不断与业界进行交流学习,探索最佳实践案例。销售数仓未来的两个趋势,一是数据的价值化,二是指标的实时化。由于目前公司处于快速发展的过程中,数据部门和业务需要更紧密地结合,充分挖掘数据的价值,真正将数据的价值体现出来,去赋能业务,为公司带来业绩的增长。目前实时化是一个大的趋势,数据以及业务的变化,都需要及时体现出来,做到高实时性。 
问答环节******Q1:支付订单完成订单之后,可能会发生周期性退款的问题,正常的 DWD 模型或 DWS 模型通常会存在多分区表,针对这种类似于多状态不断更新的表,例如有一段退款之后就会发生历史回溯修改 DWS 模型,小米是如何解决的?**A1:我们是通过离线的方式去对数据准确性进行修正。在离线里面会跑全量数据,即每次跑的时候是从 ODS 层采集到 DW 层的处理,以及 DM 层,每个分区里面都是全量数据。这一块计算会比较重,用来解决状态经常变化的问题。**Q2:数据权限一般存储在哪一层?**A2:我们会有一个平台部门去负责整体的数据权限,我们在每一层,从ODS到DWD、DWM都会有权限管控。**Q3:物流这块引入 Kudu 或者 Doris 可以吗?**A3:目前在部门内部 Kudu 是将要被替换的状态。因为 Kudu 是一个相对小众的产品,运维成本会比较高。我们正在用阿里的 Hologres 去替代 OLAP 引擎,包括Kudu 和 Doris。 目前在我们的离线和实时数据生产中,会使用Doris去加速结果表,我们会把一些中间结果或者最终的汇总数据存到 Doris 里面(主要是汇总数据),之后利用 Doris 的 OLAP 能力去对查询进行加速。**Q4:DWM 是跨域的宽表吗?DWD 和 DWM 到底哪个是明细层?**A4:我们将 DWD 和 DWM 统称为 DW,都是明细层。DWD 主要是进行规范化,把可能不同的异构数据统一到 DWD 来。在这个过程中除了 ETL、规划化、标准化之外,不会进行特别复杂的操作。在 DWM 层我们会加工一些公共的复杂的逻辑。DWM 层也是明细数据,是把多个 DWD 表做关联,生成的明细宽表。**Q5:DM 层以下的分层会提供给用户访问吗?**A5:我们的 ODS、DWD 以及 TMP 层是不提供外部访问的,其它层基本都可以对外部提供读权限。DW 层例如 DWM 是可以提供给外部访问的。因为 DWM 已经进行了逻辑的封装,用户使用 DWM 通过简单的计算就能得到我们在 DM 中最终得出的指标。**Q6:维度指标是单独分开存储的吗?**A6:不是,我们是存在一块的。以上就是本次分享的内容,谢谢大家。


分享嘉宾
INTRODUCTION
沈子阳
小米
高级软件研发工程师

南开大学硕士,小米集团高级软件研发工程师,担任销售数仓负责人,主导小米销售数仓的建设和应用。
