
转载机器之心报道编辑:Panda
去噪扩散模型(DDM)是当前图像生成技术的一大主流方法。近日,Xinlei Chen、Zhuang Liu、谢赛宁与何恺明四人团队对 DDM 进行了解构研究 —— 通过层层剥离其组件,DDM 的生成能力不断下降,但其表征学习能力却能得到一定的维持。这表明 DDM 的某些组件可能对表征学习作用不大。 对于当前计算机视觉等领域的生成模型,去噪是一种核心方法。这类方法常被称为去噪扩散模型(DDM)—— 它们会学习一个去噪自动编码器(DAE),其能通过一个扩散过程移除多个层级的噪声。
这些方法实现了出色的图像生成质量,尤其适合生成高分辨率、类似照片的仿真实图像。事实上,这些生成模型的表现如此之好,以至于看起来它们就好像具有强大的识别表征,可以理解这些视觉内容。
尽管 DAE 是当今生成模型的中流砥柱,但提出这种方法的最早论文《Extracting and composing robust features with denoising autoencoders》却是为了以监督式方法从数据学习表征。
在当今的表征学习社区,可以说 DAE 最成功的变体都是基于「掩码噪声(masking noise)」,比如预测语言中缺失的文本(如 BERT)或图像中缺失的图块。
但是,从概念上看,这些基于掩码的变体依然与移除加性噪声(如高斯噪声)大不相同:尽管掩码 token 会明确指定未知和已知内容,但在分离加性噪声的任务中并没有清晰的信息可用。然而,当今的用于生成任务的 DDM 主要是基于加性噪声,这意味着它们可能在学习表征时没有明确标记未知 / 已知内容。
最近,越来越多的人研究 DDM 的表征学习能力。这些研究是直接采用已有的预训练 DDM(这些模型原本是为生成任务设计的),然后评估它们在识别任务上的表征质量。使用这些面向生成的模型,他们得到的结果鼓舞人心。
但是,这些开创性研究也显然留下了尚未解决的问题:这些现成可用的模型是为生成任务设计的,而不是识别任务,所以我们不清楚其表征能力是在去噪驱动的过程中获得的,还是在扩散驱动的过程中获得的。
Xinlei Chen 等人的这项研究则在这一研究方向上迈出了一大步。

论文标题:Deconstructing Denoising Diffusion Models for Self-Supervised Learning * 论文地址:https://arxiv.org/pdf/2401.14404.pdf
他们没有使用现有的面向生成的 DDM,而是训练了面向识别的模型。这项研究的核心理念是解构 DDM,一步步地修改它,直到将其变成经典的 DAE。
通过这个解构研究过程,他们仔细探究了现代 DDM 在学习表征目标上的每个方面。该研究过程为 AI 社区带来了全新的理解 —— 要学习一个好表征,DAE 需要哪些关键组件。
让人惊讶的是,他们发现其中的主要关键组件是 token 化器,其功能是创建低维隐空间。有趣的是,这一观察结果很大程度上与具体的 token 化器无关 —— 他们探索了标准的 VAE、图块级 VAE、图块级 AE、图块级 PCA 编码器。他们发现,让 DAE 得到好表征的是低维隐空间,并不是具体的 token 化器。
得益于 PCA 的有效性,该团队一路解构下来,最终得到了一个与经典 DAE 高度相似的简单架构(见图 1)。

他们使用图块级 PCA 将图像投影到一个隐空间,添加噪声,再通过逆 PCA 将其投影回来。然后训练一个自动编码器来预测去噪后的图像。
他们将这个架构称为 latent Denoising Autoencoder(l-DAE),即隐去噪自动编码器。
该团队的解构过程还揭示了 DDM 和经典 DAE 之间的许多其它有趣的特性。
举个例子,他们发现,即使使用单一的噪声等级(即不使用 DDM 的噪声调度),也能通过 l-DAE 取得不错的结果。使用多级噪声的作用就像是某种形式的数据增强,这可能是有益的,但并非一个促成因素。
基于这些观察,该团队认为 DDM 的表征能力主要是通过去噪驱动的过程获得的,而不是扩散驱动的过程。
最后,该团队也将自己取得的结果与之前的基准进行了比较。一方面,新的结果比之前已有的方法更好:这符合预期,因为那些模型本就是解构过程的起点。另一方面,新架构的结果比不上基准的对比学习方法和基于掩码的方法,但差距减小了一些。这也说明 DAE 和 DDM 研究方向上还有进一步的研究空间。
背景:去噪扩散模型
这项解构研究的起点是去噪扩散模型(DDM)。
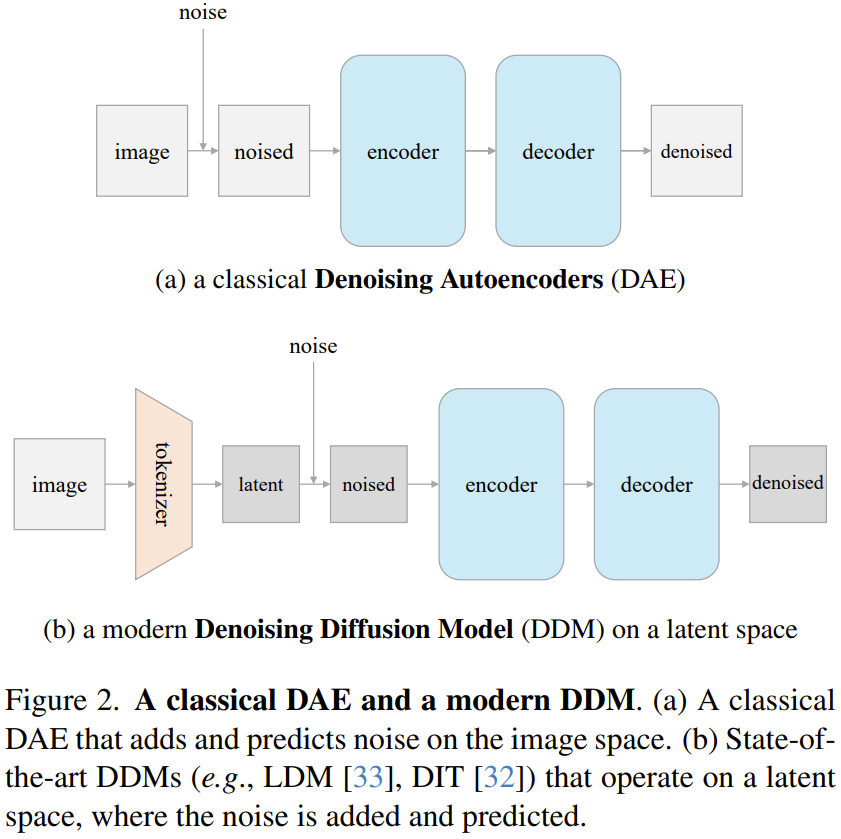
至于 DDM,可参阅论文《Diffusion models beat GANs on image synthesis》和《Scalable Diffusion Models with Transformers》以及机器之心的相关报道《统治扩散模型的 U-Net 要被取代了,谢赛宁等引入 Transformer 提出 DiT》。
解构去噪扩散模型
我们这里关注的重点是其解构过程 —— 这个过程分为三个阶段。首先是将 DiT 中以生成为中心的设置改成更面向自监督学习的设置。接下来,逐步解构和简化 token 化器。最后,他们尝试逆向尽可能多的 DDM 驱动的设计,让模型向经典 DAE 靠近。
**
**
让 DDM 重新转向自监督学习
尽管从概念上讲,DDM 是 DAE 的一种形式,但它其实一开始是为图像生成任务开发出来的。DDM 中的很多设计都是面向生成任务的。某些设计本身并不适合自监督学习(比如涉及类别标签);另一些设计则在不考虑视觉质量时并不是必需的。
这一节,该团队将把 DDM 的目的调整为自监督学习。表 1 展示了这一阶段的进展过程。

移除类别条件化处理
第一步是移除基准模型中的类别条件处理过程。
出人意料的是,移除类别条件化处理会显著提升线性探测准确度(linear probe accuracy,从 57.5% 到 62.1%),然而生成质量却如预期那样会大幅下降(FID 从 11.6 到 34.2)。
该团队猜想:直接在类别标签上对模型进行条件化处理可能会降低模型对编码类别标签相关信息的需求。而移除类别条件化处理则会迫使模型学习更多语义
解构 VQGAN
DiT 从 LDM 继承而来的 VQGAN token 化器的训练过程使用了多个损失项:自动编码重建损失、KL 散度正则化损失、基于为 ImageNet 分类训练的监督式 VGG 网络的感知损失、使用判别器的对抗损失。该团队对后两项损失进行了消融研究,见表 1。
当然,移除这两项损失都会影响生成质量,但在线性探测准确度指标上,移除感知损失会让其从 62.5% 降至 58.4%,而移除对抗损失则会让其上升,从 58.4% 到 59.0%。而移除对抗损失之后,token 化器本质上就是一个 VAE 了。
替换噪声调度
该团队研究了一个更简单的噪声调度方案以支持自监督学习。
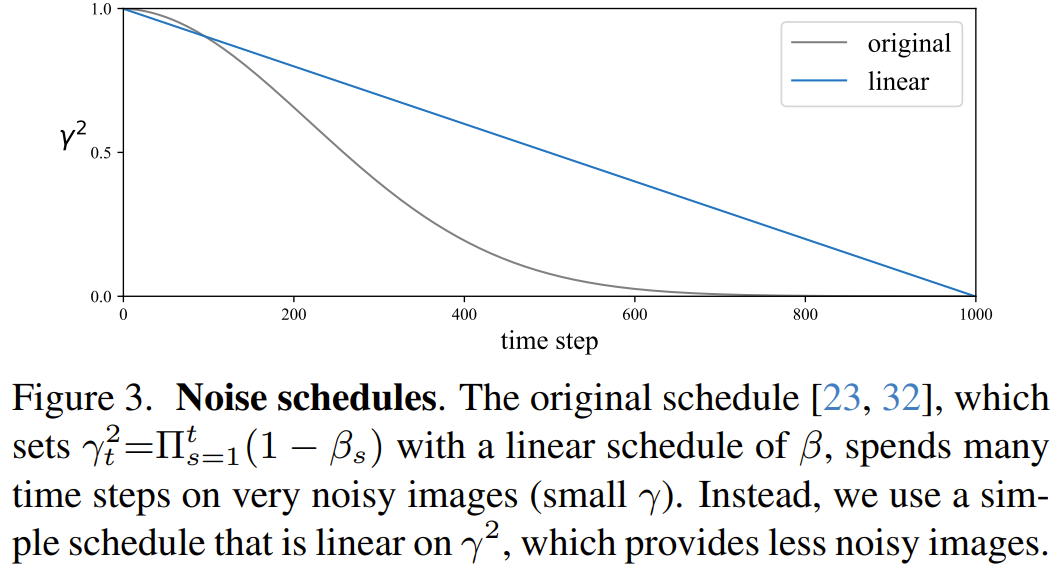
具体来说,就是让信号的缩放因子 γ^2_t 在 1>γ^2_t≥0 的范围内线性衰减。这让模型可把更多能力投放到更清晰的图像上。这会让线性探测准确度从 59.0% 显著升至 63.4%。
解构 token 化器
接下来通过大量简化来解构 VAE token 化器。他们比较了四种作为 token 化器的自动编码器变体,每一种都是前一种的简化版本:
卷积 VAE:这是上一步解构的结果;常见情况是这种 VAE 的编码器和解码器是深度卷积神经网络。 * 图块级 VAE:让输入变成图块。 * 图块级 AE:移除了 VAE 的正则化项,使得 VAE 本质上变成 AE,其编码器和解码器都是线性投影。 * 图块级 PCA:即在图块空间上执行主成分分析(PCA),这是一种更简单的变体。很容易证明 PCA 等价于 AE 的一个特例。
由于使用图块很简单,因此该团队对三个图块级 token 化器在图块空间的过滤器进行了可视化,见图 4。

表 2 总结了使用这四种 token 化器变体时 DiT 的线性探测准确度。
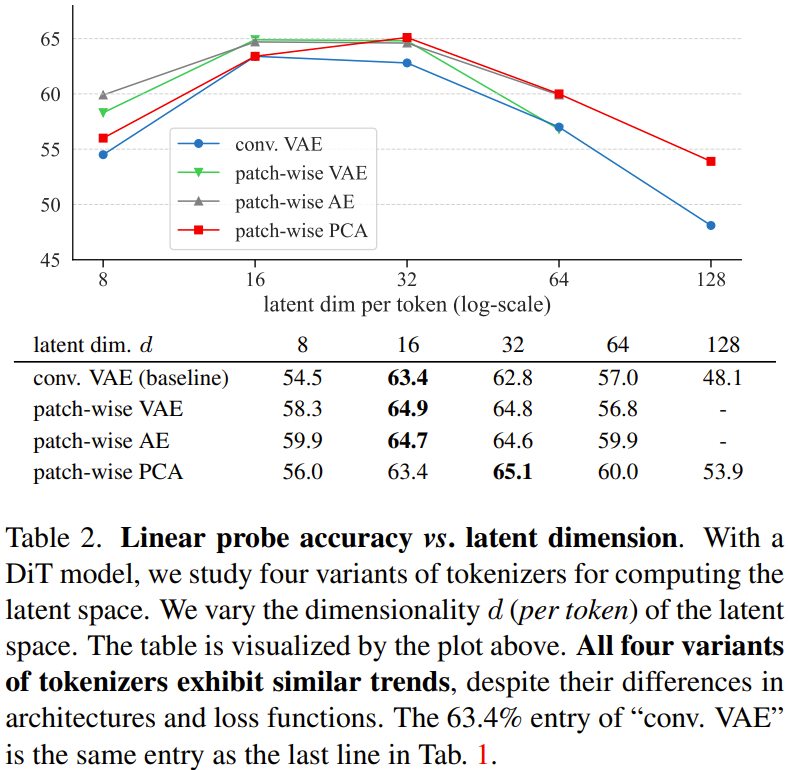
他们观察到了以下结果:
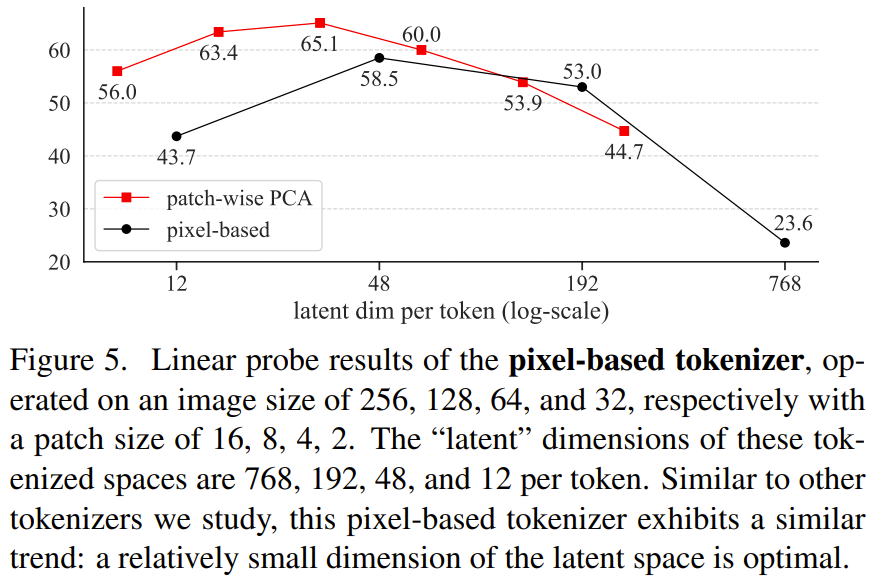
要让 DDM 很好地执行自监督学习,token 化器的隐含维度至关重要。 * 对自监督学习而言,高分辨率的、基于像素的 DDM 效果很差(见图 5。
变成经典的去噪自动编码器
解构的下一步目标是使模型尽可能地接近经典 DAE。也就是要移除让当前的基于 PCA 的 DDM 和经典 DAE 不同的各个方面。结果见表 3。

预测清晰的数据(而非噪声)
现代 DDM 通常是预测噪声,而经典 DAE 则是预测清晰数据。该团队的做法是通过调整损失函数来为更清晰的数据的损失项赋予更多权重。
如此修改会让线性探测准确度从 65.1% 降至 62.4%。这表明预测目标的选择会影响表征的质量。
移除输入缩放
在现代 DDM 中,输入有一个缩放因子 γ_t。但经典 DAE 中却不常这样操作。
通过设定 γ_t ≡ 1,该团队发现得到了 63.6% 的准确度(见表 3),相比于 γ_t 可变的模型(62.4%)还好一些。这说明在当前场景中,对输入进行缩放是完全没必要的。
使用逆 PCA 对图像空间进行操作
到目前为止,对于前面探索过的所有条目(图 5 除外),模型都运行在由 token 化器生成的隐含空间上(图 2 (b))。理想情况下,我们希望 DAE 能直接操作图像空间,同时还能位置优良的准确度。该团队发现,既然使用了 PCA,那么就可以使用逆 PCA 来实现这一目标。参见图 1。
通过在输入端进行这样的修改(依然在隐含空间上预测输出),可得到 63.6% 的准确度(表 3)。而如果进一步将其应用于输出端(即使用逆 PCA 在图像空间上预测输出),可得到 63.9% 的准确度。两个结果都表明,使用逆 PCA 在图像空间上进行操作得到的结果近似于在隐含空间上的结果。
预测原始图像
虽然逆 PCA 可以在图像空间中得到预测目标,但该目标不是原始图像。这是因为对于任何经过降维的维度 d 而言,PCA 都是有损编码器。相比之下,更自然的解决方案是直接预测原始图像。
当让网络预测原始图像时,引入的「噪声」包括两部分:加性高斯噪声(其内在维度为 d)和 PCA 重建误差(其内在维度为 D − d(D 为 768))。该团队的做法是对这两个部分分开进行加权。
通过该团队的设计,可让预测原始图像实现 64.5% 的线性探测准确度。
这个变体在概念上非常简单:其输入是一张有噪声图像,其中噪声是添加到 PCA 隐含空间中,它的预测结果是原始的干净图像(图 1)。
单一噪音等级
最后,在好奇心的驱使下,该团队还研究了具有单一噪音等级的变体。他们指出,通过噪声调度实现的多级噪声是 DDM 的扩散过程的一个属性。而经典 DAE 在概念上并不必需要多级噪声。
他们将噪声等级 σ 固定成了一个常量 √(1/3)。使用这个单级噪声,模型的准确度为相当不错的 61.5%,相比于多级噪声的 64.5% 仅降低了三个百分点。
使用多级噪声类似于 DAE 中一种形式的数据增强:它是有益的,但不是促成因素。这也意味着 DDM 的表征能力主要来自去噪驱动的过程,而不是来自扩散驱动的过程。
总结
总而言之,该团队对现代 DDM 进行了解构,让其变成了经典 DAE。
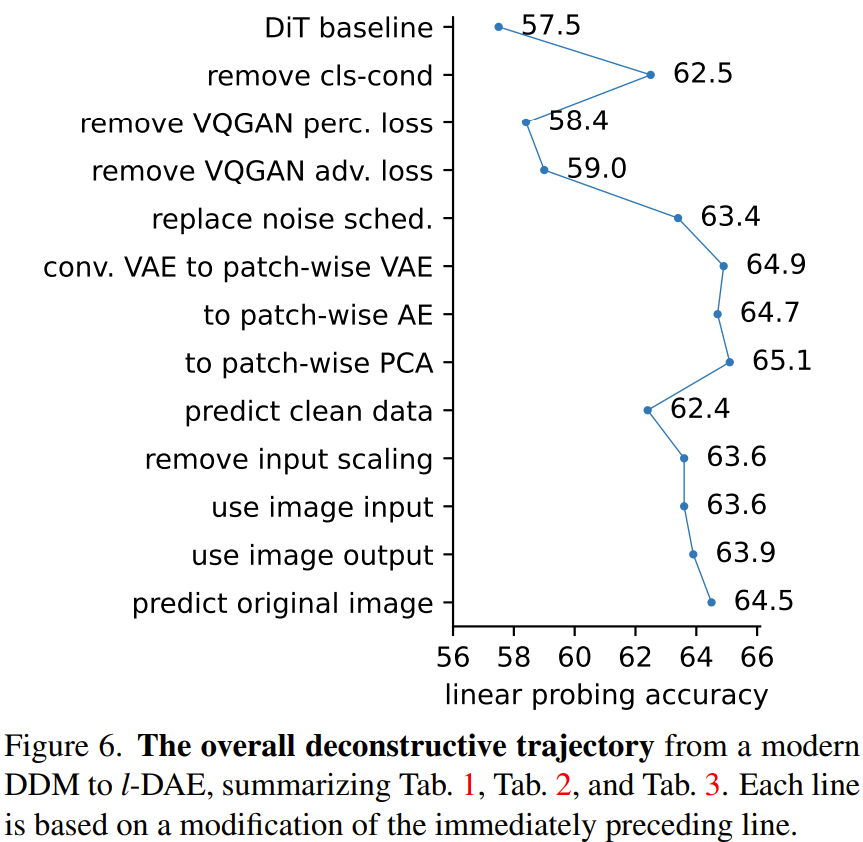
他们去除了许多现代设计,并且在概念上只保留了两个承袭自现代 DDM 的设计:低维隐含空间(这是添加噪声的位置)和多级噪声。
他们使用表 3 最后一项作为最后的 DAE 实例(如图 1 所示)。他们将这种方法称为 latent Denoising Autoencoder(隐去噪自动编码器),简写成 l-DAE。
分析与比较
可视化隐含噪声
从概念上讲,l-DAE 是 DAE 的一种形式,可学习移除添加到隐含空间的噪声。由于 PCA 很简单,于是可以轻松地对逆 PCA 的隐含噪声进行可视化。
图 7 比较了添加到像素和添加到隐含空间的噪声。不同于像素噪声,隐含噪声很大程度上与图像的分辨率无关。如果使用图块级 PCA 作为 token 化器,隐含噪声的模式主要由图块大小决定。

去噪结果
图 8 展示了基于 l-DAE 的更多去噪结果示例。可以看到,新方法能得到比较好的预测结果,即便噪声浓厚。

数据增强
需要指出,这里给出的所有模型都没有使用数据增强:仅使用了图像中心区域裁剪,没有随机的大小调整或颜色抖动。该团队做了进一步的研究,测试了为最终的 l-DAE 使用温和的数据增强:
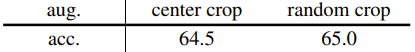
结果略有改善。这表明 l-DAE 的表征学习能力很大程度上与数据增强无关。在 MAE 中也观察到了类似的行为,参阅何恺明等人的论文《Masked autoencoders are scalable vision learners》,这与对比学习方法大不相同。
训练 epoch
之前的所有实验都基于 400 epoch 的训练。按照 MAE 的设计,该团队也研究了 800 和 1600 epoch 的训练:

相比之下,当 epoch 数从 400 升至 800 时,MAE 有显著增益(4%);但 MoCo v3 在 epoch 数从 300 升至 600 时却几乎没有增益(0.2%)。
模型大小
之前的所有模型都是基于 DiT-L 变体,其编码器和解码器都是 ViT-1/2L(ViT-L 的一半深度)。该团队进一步训练了不同大小的模型,其编码器是 ViT-B 或 ViT-L(解码器的大小总是与编码器一样):
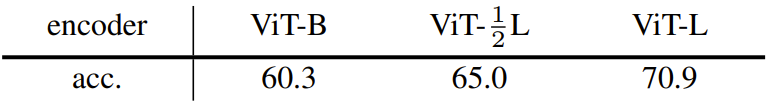
可以看到:当模型大小从 ViT-B 变大成 ViT-L 时,能获得 10.6% 的巨大增益。
比较之前的基准模型
最后,为了更好地理解不同类型的自监督学习方法的效果,该团队进行了一番比较,结果见表 4。

有趣的是,相比于 MAE,l-DAE 的表现还算不错,仅有 1.4% (ViT-B) 或 0.8% (ViT-L) 的下降。另一方面,该团队也指出 MAE 的训练效率更高,因为它只处理无掩码图块。尽管如此,MAE 和 DAE 驱动的方法之间的准确度差距已经在很大程度上缩小了。
最后,他们还观察到,相比于该协议下的对比学习方法,基于自动编码器的方法(MAE 和 l-DAE)仍然存在不足,特别是当模型很小时。他们最后表示:「我们希望我们的研究能够吸引人们更加关注用基于自动编码器的方法实现自监督学习的研究。」

