扩散模型生成带汉字图像,一键输出表情包:OPPO等提出GlyphDraw
机器之心编辑部
为了让 AI 生成的图像里带有真正的文字,人们想尽了办法。
近来,文本生成图像领域取得了很多意想不到的突破,很多模型都可以实现基于文本指令创建高质量和多样化图像的功能。虽然生成的图像已经很逼真,但当前模型往往善于生成风景、物体等实物图像,但很难生成带有高度连贯细节的图像,例如带有汉字等复杂字形文本的图像。
为了解决这个问题,来自 OPPO 等机构的研究者们提出了一个通用学习框架 GlyphDraw,旨在让模型能够生成嵌入连贯文本的图像,这是图像合成领域首个解决汉字生成问题的工作。

论文地址:https://arxiv.org/abs/2303.17870
项目主页:https://1073521013.github.io/glyph-draw.github.io/
我们先来看一下生成效果,例如为展览馆生成警示标语:

生成广告牌:

为图片配上简要的文本说明,文字样式也可多样化:

还有,最有趣也最实用的例子是生成表情包:

虽然结果存在一些瑕疵,但是整体生成效果已经很好了。总体来说,该研究的主要贡献包括:
该研究提出了首个汉字图像生成框架 GlyphDraw,其中利用一些辅助信息,包括汉字字形和位置在整个生成过程中提供细粒度指导,从而使汉字图像高质量无缝嵌入到图像中;
该研究提出了一种有效的训练策略,限制了预训练模型中可训练参数的数量,以防止过拟合和灾难性遗忘(catastrophic forgetting),有效地保持了模型强大的开放域生成性能,同时实现了准确的汉字图像生成。
该研究介绍了训练数据集的构建过程,并提出了一个新的基准来使用 OCR 模型评估汉字图像生成质量。其中,GlyphDraw 获得了 75% 的生成准确率,明显优于以前的图像合成方法。

模型介绍
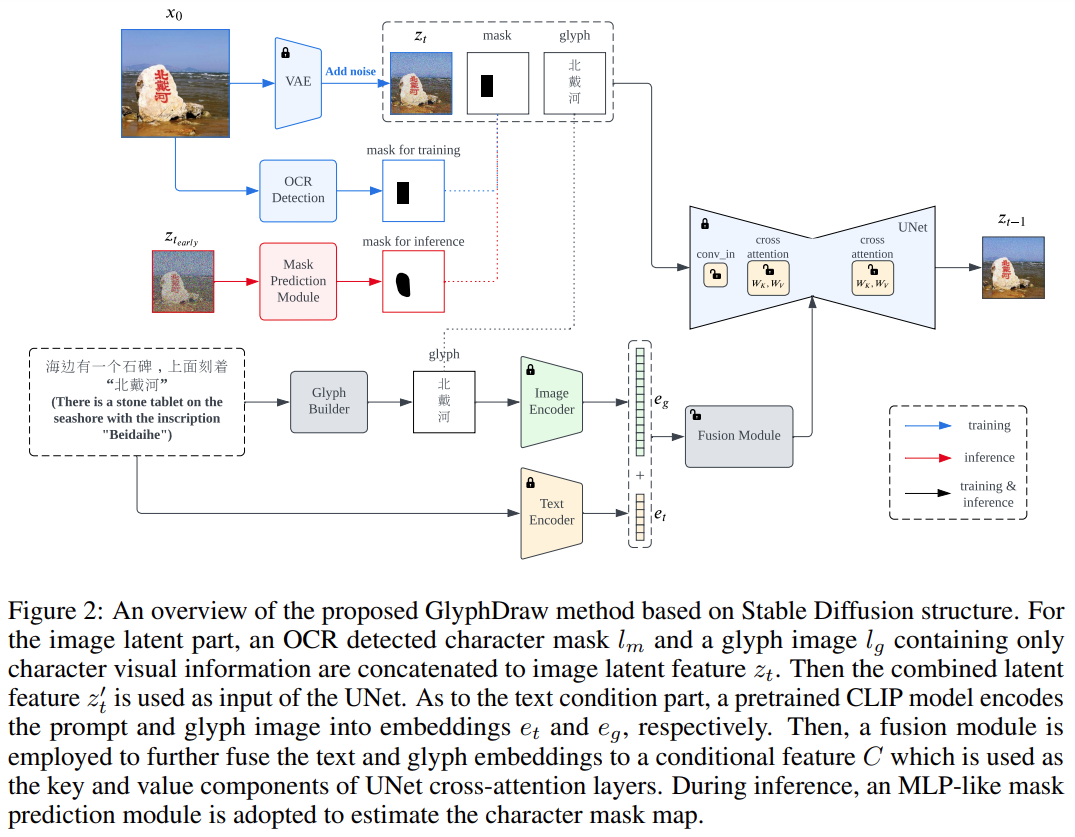
该研究首先设计了复杂的图像 - 文本数据集构建策略,然后基于开源图像合成算法 Stable Diffusion 提出了通用学习框架 GlyphDraw,如下图 2 所示。
Stable Diffusion 的整体训练目标可以表示为如下公式:
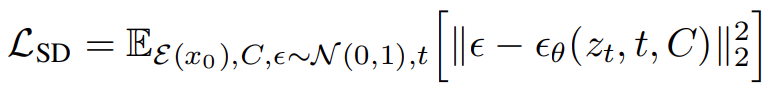
GlyphDraw 基于 Stable Diffusion 中的交叉注意力机制,原始输入潜在向量 z_t 被图像潜在向量的 z_t、文本掩码 l_m 和字形图像 l_g 的级联替代。
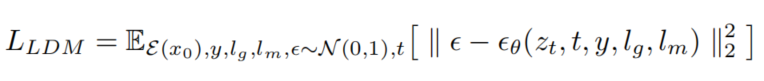
此外,通过使用特定领域的融合模块,条件 C 配备了混合字形和文本特征。文本掩码和字形信息的引入,让整个训练过程实现了细粒度的扩散控制,是提高模型性能的关键组成部分,最终得以生成带有汉字文本的图像。
具体来说,文本信息的像素表征,特别是象形汉字这种复杂的文本形式,与自然物体有明显的不同。例如,中文词语「天空(sky)」是由二维结构的多个笔画组成,而其对应的自然图像是「点缀着白云的蓝天」。相比之下,汉字有非常细粒度的特性,甚至是微小的移动或变形都会导致不正确的文本渲染,从而无法实现图像生成。
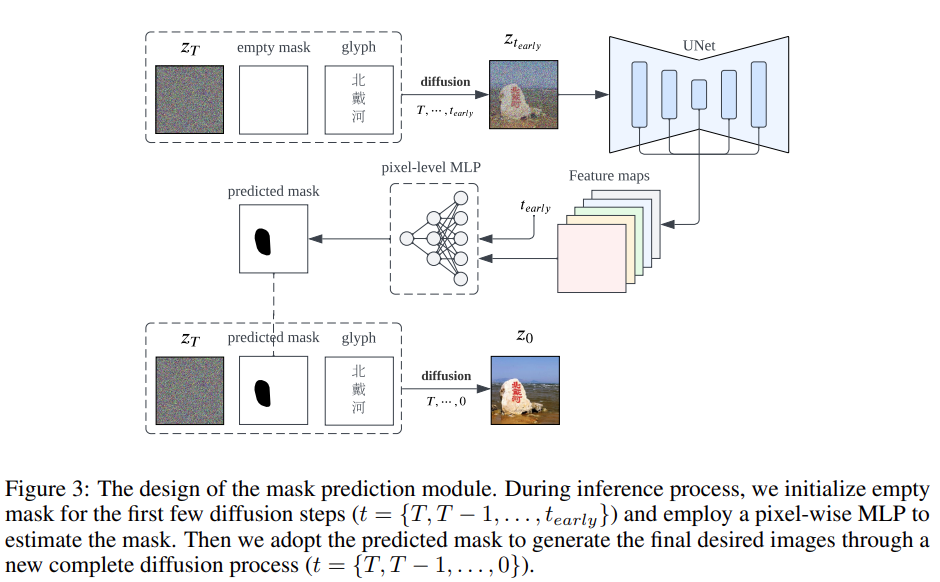
在自然图像背景中嵌入字符还需要考虑一个关键问题,那就是在避免影响相邻自然图像像素的同时,还要精确地控制文本像素的生成。为了在自然图像上呈现完美的汉字,作者精心设计了两个集成到扩散合成模型中的关键组件,即位置控制和字形控制。
与其他模型的全局条件输入不同,字符生成需要更多地关注图像的特定局部区域,因为字符像素的潜在特征分布与自然图像像素的潜在特征分布有很大差异。为了防止模型学习崩溃,该研究创新性地提出了细粒度位置区域控制来解耦不同区域之间的分布。
除了位置控制,另一个重要的问题是汉字笔画合成的精细控制。考虑到汉字的复杂性和多样性,在没有任何明确先验知识的情况下,仅仅只是从大量的图像 - 文本数据集中学习是极其困难的。为了准确地生成汉字,该研究将显式字形图像作为额外的条件信息纳入模型扩散过程。
实验及结果
由于此前没有专门用于汉字图像生成的数据集,该研究首先构建了一个用于定性和定量评估的基准数据集 ChineseDrawText,然后在 ChineseDrawText 上测试比较了几种方法的生成准确率(由 OCR 识别模型评估)。
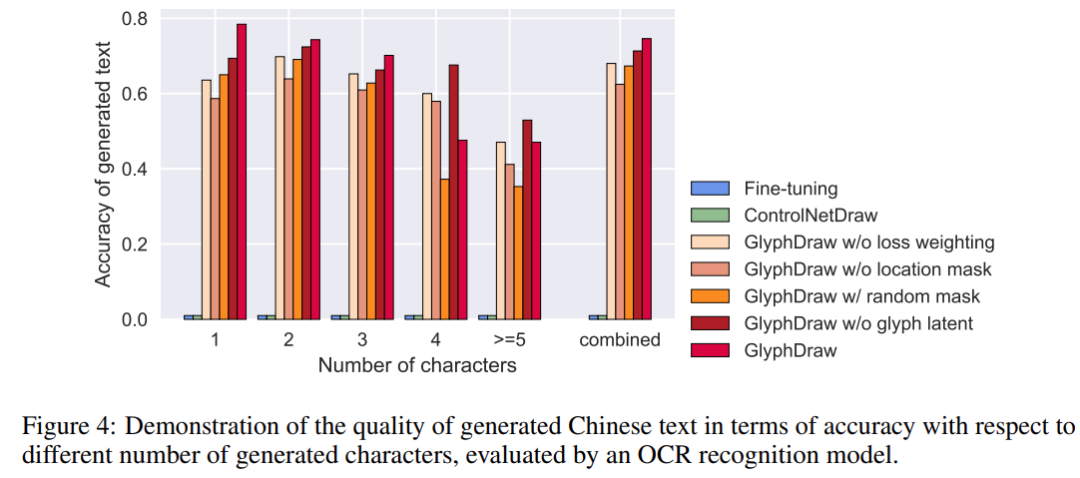
该研究提出的 GlyphDraw 模型通过有效地使用辅助字形和位置信息达到了 75% 的平均准确率,从而证明了该模型出色的字符图像生成能力。几种方法的可视化比较结果如下图所示:

此外,GlyphDraw 还可以通过限制训练参数来保持开放域图像合成性能,在 MS-COCO FID-10k 上一般图像合成的 FID 仅下降了 2.3。


感兴趣的读者可以阅读论文原文,了解更多研究细节。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


