
当前假新闻已成为全球性严峻挑战,社交媒体快速传播错误信息的能力加剧了这一问题。本文提出基于大语言模型(LLM)能力的新型特征计算流程构建方法,应对假新闻检测的紧迫挑战。核心目标在于优化可疑文本属性转化为分类适用数值向量的过程,从而填补系统整合语言线索与深度上下文嵌入的研究空白。在英语(FakeNewsNet)和乌克兰语(真假新闻)数据集上的实验表明:该方法以88.5%(英语)和86.7%(乌克兰语)准确率超越四个基线模型。关键发现显示:将复述比率、情感比率等数值指标与LLM嵌入结合,可提升欺诈文章检测召回率,较标准技术平均提高2-3个百分点。这些结果表明所提特征计算流程在保持模型决策透明度的同时显著提升检测精度。研究最终强调:系统化设计的数值特征对LLM嵌入的补充至关重要,为构建更可靠、适应性强且可解释的假新闻检测系统指明路径。
假新闻——伪装成可信新闻的虚假或误导性内容——在数字时代已发展为全球性重大威胁[1,2]。超过36亿社交媒体用户使未经核实信息突破传统编辑监管快速传播,加速虚假叙事扩散[2]。2016年美国总统大选[3]与2019年印度大选[4]等事件印证了错误信息影响舆论的速度。例如新冠疫情期间,关于病毒及疫苗的有害谣言在网络蔓延,削弱公共卫生信息公信力。研究表明假新闻比真实新闻传播更快更广[5],可能加剧社会极化、侵蚀主流媒体信任[6]甚至煽动暴力[7,8]。过去十年研究者聚焦机器学习(ML)与自然语言处理(NLP)方法实现大规模虚假信息识别[9]。早期尝试将假新闻检测形式化为二分类问题——仅通过文本分析区分真假新闻[2]。传统方法采用朴素贝叶斯、支持向量机(SVM)或随机森林等算法,结合n元语法或专业词典等特征工程,有时取得较好效果[10]。然而假新闻制造者适应伪装能力意味着捕捉深层语义线索仍是开放挑战[7,11,12]。
深度神经网络(特别是卷积神经网络CNN与长短期记忆网络LSTM)被提出用于自动学习潜在文本表征。尽管LSTM在某些基准任务中准确率超99%[10],但综合实验证实:除非融入更丰富上下文理解,高度复杂或领域特定的假新闻仍能规避这些模型[7,8]。同时词嵌入技术(如TF-IDF、Word2Vec和FastText)通过将单词映射为稠密向量改进了词袋模型[13]。尽管能捕获语义关系,这些静态嵌入仍难以应对多义词与语境变化[1]。基于Transformer的模型开创了上下文嵌入新范式:双向Transformer编码器(BERT)[14]可捕捉微妙语言线索,尤其在领域特定任务微调后。研究证实BERT在包括虚假信息检测的多个NLP任务中显著超越传统基线[15]。但在实际假新闻场景(尤其多语言环境)部署BERT仍受限于领域数据匮乏与资源开销[16]。
大语言模型(LLM)如OpenAI的GPT-4[17]与Meta的LLaMA[18]的兴起,为利用海量预训练语料获取高级文本表征提供机遇。初步研究表明LLM嵌入能识别小模型无法察觉的微妙虚假信息线索[19]。然而高计算需求与LLM决策解释难题仍未解决[20,21]。对此可解释人工智能(XAI)领域研究提出将深度学习预测能力与可解释机制结合以阐明分类结果[22]。但多数文本分类XAI方法仍难将内在特征映射为终端用户可理解的文本线索。基于这些挑战,本研究引入新型特征计算流程构建方法,借鉴可解释LLM流程的洞见:将检测分解为合成可疑特征→数值化计算特征→构建鲁棒模型→生成透明结论的链式任务。
本研究目标是通过整合LLM驱动的特征提取选择框架与阐明特征重要性的可解释策略,增强假新闻检测能力。旨在证明该流程能提升多语言文本数据的准确性与可解释性。主要贡献如下:
• 受可解释AI研究启发,提出假新闻检测特征计算流程构建方法
• 在传统LLM对比(TF-IDF/Word2Vec/BERT)基础上,新增使用大语言模型计算解释特征的显式步骤,弥合原始嵌入与透明决策的鸿沟
• 在双数据集验证LLM驱动特征实现最高精度(英语88.5%/乌克兰语86.7%),并阐释框架如何揭示文本被判定虚假的原因
本文结构如下:第2章精炼相关工作,阐明方法如何融合现有特征提取技术与可解释性;第3章详述新提出的任务分解架构、数据流及特征计算优化机制;第4章报告实验结果(含现有方法定量对比);第5章探讨优势缺陷与开放性问题;第6章展望未来(聚焦数值结果、现存挑战及研究方向)。
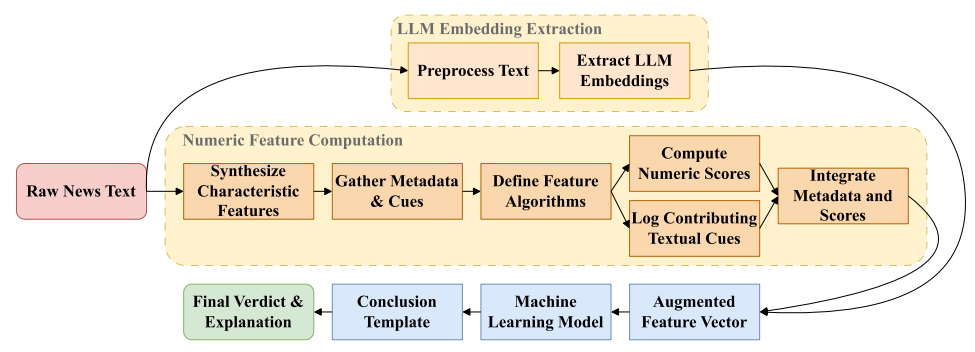
图1:本方案整体工作流程
融合基于LLM的嵌入表示、数值化特征计算及最终专家结论模板。图示阐明本方法的四大核心任务:
(i) 特征合成 → (ii) 特征计算流程构建 → (iii) 机器学习模型建立 → (iv) 专家结论模板生成
展示原始文本与衍生特征在各阶段的流向。

