

近年来,假新闻泛滥成灾,有可能对全球社会造成危害和挑拨离间,因而备受关注。为解决这一问题,人们在一项被称为假新闻检测(FND)的任务中采用了机器学习技术,以评估文本新闻内容的真实性。然而,注释假新闻数据的稀缺性给开发有效的监督模型带来了挑战。本研究试图通过研究各种数据增强技术对最先进的深度学习 FND 分类器性能的影响来解决这一局限性。我们研究了不同数据增强技术的功效,其中包括基于从预先训练的大型语言模型(Vicuna 和 ChatGPT)生成增强数据的新型技术,以及一种被称为 "灰度缩放 "的方法,该方法涉及用强度较低的同义词替换单词。我们使用两个流行数据集的小型随机子集,评估了这些数据增强技术与 BERT-base(一种广泛使用的 FND 分类器)相结合的效果: WELFake 和 LIAR。结果表明,采用数据增强技术后,分类性能略有提高,但并不显著。我们的研究结果表明,文本数据扩增并不总能大幅提高 FND 性能,基于知识、基于传播和基于来源的方法等替代策略可能更有成效。对于未来的研究,我们建议研究基于 GPT-4 的数据增强技术、假新闻生成与检测之间的关系,以及探索使用瑞典新闻数据进行假新闻检测,从而为现有的非英语数据集研究做出贡献。
假新闻现象
虚假或误导性信息的传播是数字时代一个日益严重的问题,已成为社会关注的一个主要问题,对个人、组织、政府和整个社会都产生了重大影响。因此,"假新闻 "一词的使用在现代语言中越来越流行。尽管 "假新闻 "是一个模棱两可的术语,但它通常被用来描述蓄意传播的虚假或误导性信息,目的是伤害个人、社会团体、组织或国家,或获取利益或影响力。值得注意的是,该术语的范围远远超出了完全虚假的新闻报道,因为有些新闻可能具有误导性,包含部分真相,同时缺乏关键的背景信息、可靠的消息来源或经过核实的事实。该术语还被用来描述新闻讽刺、新闻模仿和新闻宣传。此外,假新闻的形式多种多样,既有捏造的新闻文本,也有篡改的图片和视频(Kalsnes,2018 年;Tandoc、Z. W. Lim 和 Ling,2017 年)。
编造新闻创作和传播背后的两大兵力是经济利益和意识形态(Allcott 和 Gentzkow,2017 年)。吸引大量关注的误导性报道可以带来利润的增长,或被用作左右公众舆论的手段。例如,在 2016 年美国总统大选中,社交媒体渠道上的假新闻明显激增,其目的是操纵公众的看法。在 COVID-19 大流行期间,社交媒体上虚假信息的传播仍在继续,导致公众普遍产生误解(Gabarron、Oyeyemi 和 Wynn,2021 年)。
虽然假新闻一词并不新鲜,但其当代意义和有害影响近年来明显扩大,这主要是由于社交媒体平台的出现(Kalsnes,2018 年)。与报纸和电视等传统新闻渠道不同,假新闻可以更快、更廉价地在网上生成和传播。此外,结合人工智能模型能够批量生产可信度越来越高的文字、图片和视频的前景,未来,为了限制虚假内容的传播和可能造成的危害,有效的假新闻检测(FND)的重要性可能会增加。
利用机器学习检测假新闻
机器学习(ML)技术已被用于假新闻检测,使用了多种不同的方法和途径。首先,假新闻检测任务被视为有监督、半监督或无监督任务(Hu 等人,2022 年;X. Zhou 和 Zafarani,2020 年)。第二个考虑因素是训练模型时使用的数据类型,因为假新闻可能以多种(和组合)格式出现,包括视频、音频、图像和文本(Kalsnes,2018 年)。通常,研究中使用的数据集还包括其他数据,如有关发布者的数据(如用户账户、网站或新闻机构)、评论和传播数据,这些数据也有助于指导特定 ML 方法的选择。
然而,由于故意歪曲信息,使用 ML 模型检测假新闻具有挑战性。此外,由于缺乏有注释的假新闻数据,尤其是假新闻在不断演变,新类型不断出现,因此开发高性能的监督模型受到了阻碍。为了缓解有限注释数据带来的挑战,研究中采用了各种数据增强技术来增加数据的规模和多样性。数据增强是指通过对现有数据进行各种扰动来生成新的合成训练数据的一组技术(B. Li、Yongpan Hou 和 Che 2022)。其中一些技术已被证明有利于提高各种分类任务的分类准确性,包括假新闻检测 Keya 等人(2022 年)和 Sastrawan、Bayupati 和 Arsa(2022 年)。
研究目标与范围
本研究探讨了各种数据增强技术对最先进的 FND 分类器性能的影响。过去的研究主要集中在有监督的文本假新闻分类上,探索如何使用不同的数据增强技术来提高分类性能。然而,只有有限的分类模型、数据集和数据增强技术得到了探索。因此,本论文的主要目的是扩展先前的研究,从而为正在进行的开发更有效的书面假新闻内容检测方法的工作做出贡献。因此,本论文将只考虑文本增强技术。
此外,与传统的机器学习方法相比,基于深度学习的分类模型表现出更优越的检测性能。因此,为了提供更贴切的研究结果,本论文将重点探讨数据增强技术对选定的基于深度学习的分类模型的影响。
论文提纲
论文的其余部分将按以下步骤进行:首先,将通过文献综述介绍全面的背景情况,以提供研究背景并确定研究缺口。这将为后续章节奠定基础,并强调研究的意义。接下来,将详细介绍开展研究的方法。研究方法之后,将介绍研究结果。然后,讨论部分将根据研究目标和现有文献对结果进行解释和分析,强调研究的主要局限性,并对未来的研究课题提出建议。最后一节是论文的总体结论。
研究结果
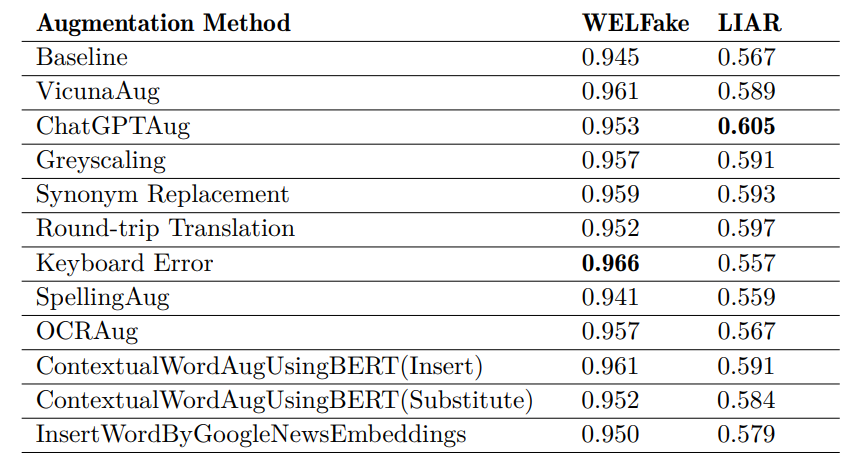
表 5:针对 LIAR 和 WELFake 数据集的每种增强方法的平均 F1 分数。每个数据集的最高值以粗体标出。
如表 5 所示,原始数据集和增强数据集的 F1 分数差异显示,在增强数据集上训练的大多数模型的 F1 分数都有适度提高,尽管这种提高在两组数据集上都没有显示出统计学意义。因此,回到论文的研究问题,我们的研究结果并没有提供证据表明,采用文本数据增强技术可以提高 BERT-base 的分类性能。这些结果与之前调查文本数据增强对 FND 的影响的研究结果部分一致。如第 2.3.3 节所述,一些研究报告称性能没有明显改善(Ashraf 等人,2021 年;Amjad、Sidorov 和 Zhila,2020 年),而另一些研究报告称性能有较大幅度提高(Keya 等人,2022 年;Hua 等人,2023 年;Júnior 等人,2022 年)。例如,Ashraf 等人(2021 年)发现,对于各种类型的分类模型(逻辑回归、多层感知器、支持向量机和随机森林),单词插入和单词替换的增强对提高分类性能并无益处。Keya 等人(2022 年)则观察到,基于 BERT 的分类器在经过词插入和词替换增强的数据集上进行微调后,分类性能显著提高。这些差异与 Salah、Jouini 和 Korbaa(2023 年)得出的结论一致,即不存在一种适用于所有情况的增强技术。相反,特定增强技术的功效似乎因分类器和数据集的选择而异。
此外,我们还注意到,在不使用数据增强技术的情况下,仅使用预先训练好的大型语言模型也能有效地进行假新闻检测。特别是,在未经扩增的 WELFake 数据集上使用 BERT-base 时,平均 F1 得分高达 94.5%,超过了一个基于扩增的模型,令人印象深刻。反过来,对于 LIAR 模型,基线模型的表现也优于两个基于增强的模型。因此,正如 Salah、Jouini 和 Korbaa(2023 年)所总结的那样,我们的研究结果表明,文本增强技术并不一定能提高检测性能。如第 2.2.1 节所述,处理 FND 任务的四种主要策略包括基于知识的方法、基于风格的方法、基于传播的方法和基于来源的方法。本研究采用基于风格的方法,通过微调大型语言模型来评估文本的书面风格,以区分假新闻和真新闻,从而专注于假新闻检测。然而,由于假新闻在写作风格上可能与真新闻十分相似,因此我们推测,仅仅通过分析语言模式、语义细微差别和存储在词嵌入中的上下文线索来辨别新闻文章的真伪,可能会有很大的局限性。因此,采用任何其他策略都可能会在性能指标方面带来更多实质性的改进。不过,值得注意的是,虽然在增强数据集上训练的模型表明性能仅有微弱提高,但考虑到一个被错误归类为真实的假新闻实例的传播可能会造成严重的有害影响,这种微小的提高对于假新闻检测仍具有实用价值。
局限性
本研究的第一个主要局限是使用了小型数据集,这可能会忽略大型数据集的性能差异。由于时间和资源限制,使用的数据集规模较小,未增强数据集的条目数为 512 个,增强数据集的条目数为 1024 个。此外,每篇文章都被截去了前 150 个字符,忽略了文章其余部分可能有用的信息。此外,数据集在语言和新闻主题方面的范围可能会限制我们的研究结果对以其他语言撰写的虚假新闻的适用性,或对我们的数据集中未涉及的主题的文章的适用性。在本研究中,我们使用了两个数据集: LIAR 和 WELFake。虽然这些数据集是假新闻检测领域常用的数据集,涵盖了广泛的新闻主题,但它们表现出对西方媒体和政治新闻的偏见。另一个局限是使用单一的预训练语言模型作为分类器。虽然 BERT-base 已被公认为各种 NLP 任务的最先进模型,但在假新闻检测方面还有许多其他选择。因此,我们的发现并不一定适用于其他模型类型和架构。最后,值得注意的是,本研究将 FND 问题定义为二元分类任务,将每篇新闻文章分为 "必真 "或 "必假 "两类。选择这种分类方法是为了使任务更易处理。然而,现实世界中的文章经常表现出更大程度的细微差别,因为它们可能包含半真半假或部分误导Tandoc, Z. W. Lim, and Ling (2017)。因此,研究结果不一定能转化为更细化的虚假性评估。
未来研究
未来的研究可能包括探索使用基于 GPT-4 的增强技术,以提高增强的质量。本研究的结果表明,Vicuna 和 ChatGPT 的性能都有所提高,因此基于 GPT-3.5 的 ChatGPT(OpenAI 2023)的更高级版本 GPT-4 可能会提供更强大、更多样化的增强功能,从而有可能带来更大的性能提升。另一个值得研究的课题是假新闻生成与假新闻预测之间的关系,因为根据非正式测试,我们怀疑 LLM 生成假新闻的能力远远强于检测假新闻的能力。我们还呼吁有必要进一步研究使用瑞典新闻数据进行假新闻检测的问题,以便为在非英语数据集上进行的假新闻检测研究做出贡献,这些数据集包括用德语、西班牙语、葡萄牙语、中文和乌尔都语等语言编写的假新闻(H. Wang, S. Wang, and Han Han. Wang, S. Wang, and Han 2022; Vogel and Jiang 2019; Ţucudean and Bucos 2022; Martínez-Gallego, Álvarez-Ortiz, and Arias-Londoño 2021; Garcia, Afonso, and Papa 2022)。虽然大多数研究主要集中在英文文本上,但研究其他语言的文本有助于扩大假新闻检测模型的范围和适用性。另一个值得关注的相邻研究课题是跨多种语言的假新闻检测研究,这可以找出挑战和解决方案的共性和差异。

