
文/庄越挺
本文共分四个部分,首先是研究背景和内容,接着介绍目前的两条研究途径,然后是研究基础及取得的进展,最后是总结和展望。
1 研究背景和内容
目 前, 大 模 型 / 多 模 态 大 语 言 模 型(LLM/MLLM)在多模态理解、推理和认知决策能力上达到新的高度,多种任务上的表现甚至超过人类水平。从图 1 可以看到,包括 OpenAI、Google 等公司所做的工作,现在都是多模态的,有些水平非常高,参数量从百亿到万亿规模不断增长。但是,大模型并非万能,而是如同强大但是资源受限的 AI“巨人”,根据 Scaling Law,参数规模一旦增大,就会涌现出很多新的能力,但同时,存在幻觉、推理效率低和成本高、专用能力缺乏等问题。
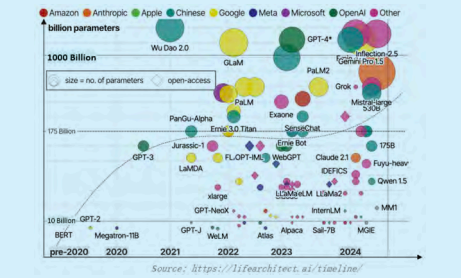
图 1 大模型的发展态势
目前,AI 社区已积累了很多小模型(SLM),这些小模型虽然规模较小,但是丰富多样、轻量高效、专用性强、可实时学习,在特定的任务中表现很出色,所以也不可忽视。例如,Hugging Face 和魔搭社区上托管了 30 多万小模型,涵盖图像、视频、语言、音频、3D 等模态上的多种任务,国内也有很多这类的小模型。
所以,我们提出大小模型紧密协作、优势互补,更加精确、高效、低成本地完成跨模态智能任务。通过探索大小模型协同方法,克服单一模型的局限性,充分发挥各自优势,以实现更高效、更精确的包含感知、理解、推理决策等方面的跨媒体智能系统。但是,构建这样的智能系统面临着三个挑战。
挑战 1:大小模型协同机理不明晰
虽然大小模型协同的趋势越来越明显,但迄今尚处于初级阶段,主要表现在协同方式以单向调用为主,缺乏更复杂协同机制的探索。如图 2 所示,GPT-4 中图像的生成实际调用的是以文生图的大模型 DALL-E 3;GPT Store 打造的生态系统里,GPT也是广泛地调用专用模型。但大小模型之间的关系,显然不是单纯的调用和被调用的关系。如何能从“单向调用”转到“网状协同”,是第一个研究挑战。
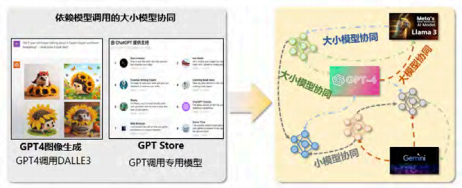
图 2 大小模型单向调用到网状协同
挑战 2:缺乏统一的计算框架
当前大小模型通常是独立训练的,然后通过链式串联的方式使用。各自训练意味着其训练数据不同,能力泛化后串在一起可能会有问题。因此,更好的方法,应是采用统一的训练和协同的推理方式。如何能从“独立训练、链式串联”到“统一训练、协同推理”,即设计一个统一的训练推理计算框架(见图 3),这是第二个挑战。
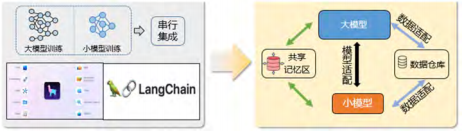
图 3 大小模型的简单部署到统一计算框架
**
**
挑战 3:大小模型知识难融合
大小模型可以看成异构的知识表达,模型不同即其表达方式也不同,包括:模型规模的差异,通用模型和专用模型之间的知识层次差异;以及数据模态不同。因此,如何从“单一模型知识”转化为“跨模型知识融合”,是我们面临的第三个挑战(见图4)。
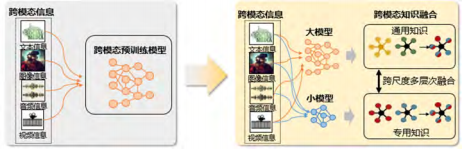
图 4 “单一模型知识”到“跨模型知识融合”
**
**
大小模型协同框架旨在整合大模型的广泛知识和小模型的专业能力。为此,要基于规划、分工与协作机制,实现知识融合,将大模型的基础知识与小模型的专用知识有机结合。具体地,首先制定整体策略,指导大小模型协同;要明确大模型和小模型各自的职责和任务,建立模型间的沟通机制、数据交换方式。通过整合大模型的广泛理解和小模型的专业知识,显著提高任务精确度;利用小模型的高效性提升整体处理效率,通过合理分配任务,降低计算成本;在专业领域,结合大模型的推理能力和小模型的专业知识,实现性能跃升,取得 1+1>2 效果。
2024 年 11 月 Wang Fali 等的综述文章(arXiv:2411.03350)中有一个大小模型的下载量统计,从中看到小模型下载量远高于大模型下载量,意味着在大模型时代小模型还是被广泛使用的。
为此,我们研究大小模型协同基础理论,提出统一训练和协同推理的计算框架,融合基础大模型、专用小模型、专家知识与知识图谱等多重知识表达,更精确、高效、低成本地完成跨模态知识融合计算,实现具备感知、理解、推理和决策能力的人工智能系统。这是我们的研究目标,具体包括四个课题,如图 5 所示。
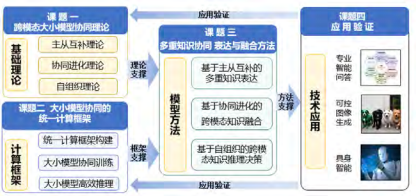
图 5 整体研究内容与思路
**2 **研究途径
****大小模型的协同有两条途径,下面分别叙述。
2.1 小模型增强大模型方法
小模型增强大模型方法分别为数据优化、弱到强学习、能力扩展和推理效率提升等方面。
(1) 数 据 优 化:使 用 SLMs 来 筛 选 和 重 构预训练和指令调整数据,以提高数据质量。例如Deepmind、Stanford 大学通过小模型进行数据加权(arXiv: 2305.10429),改善大规模预训练数据的质量,优化大模型。
(2)弱到强学习:即通过较小的模型来指导和监督更强大的 LLMs,实现知识转移。例如Weak-to-Strong范式(arXiv:2312.09390),利用小模型指导大模型 (OpenAI),在没有完整或可靠人类监督的情况下,让机器互教互学,通过小模型的弱监督来训练Human-level大模型,提出“从弱到强的泛化”,使用弱模型来监督强模型。
(3)能力扩展:通过小模型或外部工具扩展大模型的能力。例如,Toolformer(arXiv: 2302.04761)通过自监督学习,使语言模型能够自主决定何时,以及如何使用外部工具(如计算器、问答系统、搜索引擎、翻译系统和日历)来辅助任务完成。
(4)推理效率提升:通过模型级联或模型路由,将不同大小的模型结合使用以提高推理效率。如图 6 所示 Hybrid LLM(arXiv: 2404.14618) 中,采用混合推理方法,结合大小模型的优势,通过一个路由器(router)小模型动态地根据预测的查询难度和期望的质量水平来分配查询给大模型,从而充分发挥各自的长处。
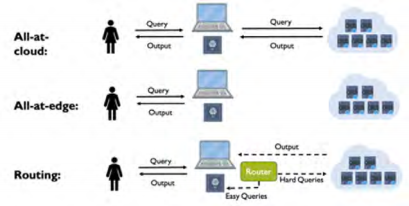
图 6 混合推理方法
此外,代理微调(proxy fine-tuning)(arXiv:2401.08565)是一种通过调整小模型(专家模型)的方法 。通过比较专家模型和未调整的模型(反专家模型)的预测结果,将两者的差异反馈至大模型的预测中,从而引导大模型向更准确的方向调整。
2.2 大模型增强小模型方法
大模型增强小模型的方法主要包括知识整理和数据合成两类。
(1)知识蒸馏:包括白盒和黑盒方法,用于将大模型的知识转移到小模型中。例如,从多个 LLMs中蒸馏出 TinyLLM(arXiv:2402.04616),学习到多样化的知识和推理技能(见图 7)。将来自不同教师模型的理由整合到一个统一的多任务指令调整框架中。不仅学习预测正确答案,还学习教师模型产生的理由。
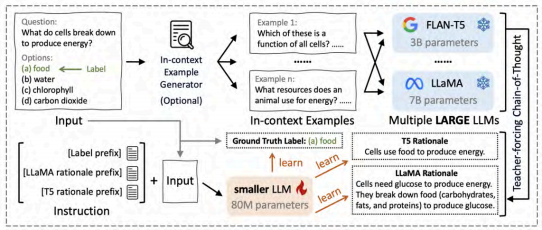
图 7 TinyLLM
**
**
(2)数据合成:利用大模型生成高质量训练数据或增强现有数据,能够显著提升小模型的性能,在特定任务上接近甚至超越大模型。例如 Zerogen(EMNLP 2022) 提出一种零样本学习框架,在没有人类标注数据的情况下,通过大模型生成数据并训练小型任务模型,来实现高效的推理和部署。图 8 来自于 Zerogen。
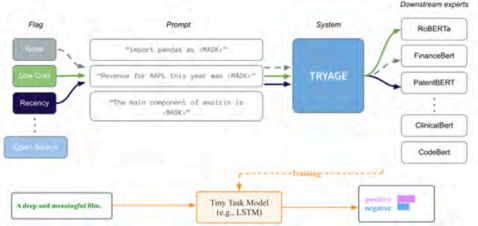
图 8 利用 LLM 生成用于解决下游任务的数据集
3 研究基础与进展
3.1 HuggingGPT:大小模型协同的智能体范例
我 们 于 2023 年 提 出 的 HuggingGPT (NeurIPS2023) 是体现大小模型协同的一个典型范例。现在虽然有许多针对各种领域和模态的 AI 模型可用,但是它们不能自主地处理任务,缺少一个能够在复杂的多领域多模态场景下解决问题的通用框架。HuggingGPT 以语言作为接口,利用 LLM 作为控制器来管理现有的 AI 模型,可以解决复杂的 AI 任务。例如,ChatGPT 实现了从文本到文本,但是它无法处理任何跨模态的任务。因此,我们用大语言模型(ChatGPT)作为一个控制器,来规划、调用小模型, 如图9所示,HuggingGPT基于大小模型的协作,可以产生很好的跨模态的感知与推理能力。
图 9 大语言模型作为工具规划、调用小模型
**
**
HuggingGPT 发表于 NeurIPS 2023,被引 900余次,其中图灵奖获得者 Bengio 和 Hinton(2024年的诺奖得主)一作论文中也引用了此文。斯坦福客座教授吴恩达、英伟达 GEAR Lab 主任 Jim Fan、OpenAI 研究员等科学家在其博文中对此文进行了推荐;GitHub 仓库获得 2 万多次收藏,获得国际测试委员会颁发的 2022—2023 Top-100 开源成就奖,Demo 系统获得 Hugging Face Space Top 10;同时在工业界产业了重要的影响,如 Hugging Face、Langchain、ModelScope 等 团 队 推 出 的TransformersAgent、Langchain HuggingGPT 和 ModelScope Agent。 **
**
3.2 大规模多模态预训练模型
我们在多模态预训练大模型以及多模态生成式处理任何跨模态的任务。因此,我们用大语言模型(ChatGPT)作为一个控制器,来规划、调用小模型, 如图9所示,HuggingGPT基于大小模型的协作,可以产生很好的跨模态的感知与推理能力。大模型等方面做了很多工作。2022 年 10 月发布了和华为的合作成果——多模态预训练大模型 LOUPE(NeurIPS 2022),其多模态细粒度语义理解能力超越 OpenAI CLIP 数倍,获华为云优秀创新合作团队奖;2023 年 9 月研发的多模态预训练大模型——Cheetor( ICLR 2024 Spotlight 前 5%),提出了可控知识注入机制,支持图文交错的多模态智能问答,并且在 MME 等多个多模态指令理解数据集上实现了最佳性能;2024 年 2 月研发的多模态生成式大模型——Morph MLLM ( ICML 2024 Spotlight) ,在多个图文内容生成、图像编辑的数据集上都显著超越已有模型,这些工作是接下去进行大小模型协同研究的重要基础。 **
**
3.3 大小模型协同
3.3.1 TeamLoRA
多 LoRA 架构被提出用于解决多维任务场景中性能不足的问题。朴素的多 LoRA 架构引入了倍增的矩阵操作次数,大幅增加了训练成本和推理延迟,与 PEFT 方法的高效率特性相悖;多 LoRA 架构通常采用门控机制决定专家的参与程度,可能存在负载不平衡和过度自信等缺陷,从而影响多任务学习中专家知识的整合与迁移的有效性。
我们提出的TeamLoRA(arXiv:2408.09856)引入了协作和竞争模块,实现了更高效和准确的 PEFT范式。其中,高效的协作模块设计了一种新颖的知识共享和组织机制,适当减少矩阵操作的规模,从而提高训练和推理速度。有效的竞争模块利用了基于博弈论的交互机制,鼓励专家在面对多样化的下游任务时针对性迁移对应的领域特定知识,从而提高性能。
从与已有模型对比结果看出,TeamLoRA 在大语言模型和多模态大模型都取得了显著的性能提升;相较于多LoRA架构平均减少了约 30% 的训练时间,获得 1.4 倍的推理响应。
3.3.2 HyperLLaVA
现行的多模态大模型范式如 LLaVA,往往采取静态网络(参数固定)实现视觉 - 文本特征的对齐与多模态指令微调。然而,这种参数共享的静态参数的学习策略存在多任务之间的干扰,限制了模型处理跨场景多任务的性能。我们提出了HyperLLaVA(arXiv:2403.13447),引入动态专家模型,实现与多模态大模型的动态学习。其中,引入的视觉专家模型,可基于图片输入自适应提取视觉特征,实现动态视觉 - 文本投影;引入的语言专家模型,可捕获和辨析多任务场景的相关性,利用动态 LLM参数生成进行样本级指令微调。此文中,我们提出了一个综合多模态任务基准 (CMT),涵盖了 Visual QA、Visual Captioning Spatial Inference、Detailed Description、Visual Storytelling、Knowledge OCR和 Text-Rich Images QA 七大类任务;训练集包含505 405 组指令;测试集包含 1149 组指令。 **
**
相 较 于 LLaVA-1.5,HyperLLaVA-7B 模 型 在12 个 benchmark 上 获 取 最 优 结 果,HyperLLaVA-13B 模 型 在 10 个benchmark 获 取 最 优 结 果;HyperLLaVA-7B 和 HyperLLaVA-13B 在 CMT 基准上都取得了最优结果。
3.3.3 TaskBench
评估大小模型协同过程的效果是一项重要但极具挑战性的任务,涉及大小模型协同过程中任务规划、工具选择和参数预测等环节。由于评测系统的复杂性和高质量标注数据的缺乏,准确评估大模型调用小模型的效果并对其进行优化一直存在困难。为此,我们提出了 TaskBench(NeurIPS 2024),一个专门针对大小模型协同和大模型任务自动化的评测框架。
TaskBench 设计了知识引导的指令数据生成和多层次评测方法,实现了基于知识的指令数据逆向生成。通过构建工具型知识图谱,建立了涵盖任务规划、工具调用和参数解析的多层级评测体系。通过 TaskBench,可以全面评估大小模型协同在多任务场景中的表现,这一评测框架及其数据生成机制能够优化大语言模型任务处理能力,对于推动复杂多任务场景下的大小模型协同研究具有深远意义。
3.3.4 Data-Copilot
能源、气象、金融、零售等行业,每日都产生海量的结构化数据,但当前的大语言模型无法直接处理海量的结构化数据,也存在数据泄露的风险。因此,我们设计了一个能听懂自然语言,便于交互的数据管理、分析的可视化的系统 Data-Copilot(arXiV:2306.07209)。面对海量动态数据和敏感信息处理需求,Data-Copilot 通过大模型解析用户自然语言指令,生成任务规划,小模型则负责具体数据操作与工具调用,从而实现高效、动态的数据管理与分析。
借助大小模型的协作,Data-Copilot 不仅大幅提升了结构化数据分析的效率,还实现了自然语言驱动的交互与智能反馈,为能源调度、气象预警、金融风控和零售管理等领域提供了便捷的智能解决方案。
3.3.5 Data Shunt
如图 10 所示,Prompt Pruning (PP) 利用小模型的预测结果来精炼大型模型的预测空间。通过将小模型的预测置信度整合到提示中,可以增强大型模型对其他分布的辨别能力。Prompt Transferring (PT)将复杂任务分解为多个子任务,其中一些简单的子任务可以由小模型处理。这样让大型模型专注于困难的子任务,从而提高整体性能。
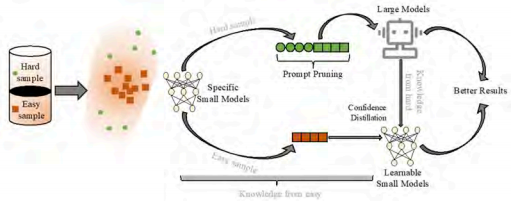
图 10 Data Shunt 系统
大模型对小模型2-Stage Confidence Distillation,通过基于小模型和大模型的置信度水平进行知识蒸馏,将大模型的知识传授给小模型,同时防止小模型遗忘在训练阶段获得的知识。
数据分流(data shunt)中(arXiv:2406.15471),DS+ 利用小模型的置信度来决定输入数据是仅通过小模型处理,还是需要大模型参与处理。如果小模型的置信度超过阈值,则小模型处理,否则大模型处理;即可以根据不同调度数据的大小模型,降低成本。
4 总结和展望
由于大模型可以提供广泛的知识和强大的推理能力,小模型贡献专业领域能力和计算效率,因此达到了优势互补;通过合理分配任务,减少了对大模型的过度依赖,降低了整体计算成本和能源消耗,的预测结果来精炼大型模型的预测空间。通过将小模型的预测置信度整合到提示中,可以增强大型模型对其他分布的辨别能力。Prompt Transferring (PT)将复杂任务分解为多个子任务,其中一些简单的子任务可以由小模型处理。这样让大型模型专注于困难的子任务,从而提高整体性能。达到了资源优化;小模型处理特定任务,提高整体响应速度,大模型专注于复杂问题,提升了系统整体表现,使模型整体性能得到提升。此外,大小模型协同根据任务需求动态调整模型组合,增强了系统在不同场景下的适应性。大模型可以指导小模型进行知识更新;小模型可以为大模型提供专业领域的新知识,使它们能够持续学习。
近年来,大小模型协同的研究发展趋势日益明显,相关文献与应用也不断涌现,表明这一方向在学术界和工业界均具有广泛前景。尽管我们的研究工作仍处于初步阶段,但这些探索为大小模型协同的未来发展提供了重要启发。随着协同机制的持续优化,大小模型协同将为多模态任务、复杂推理,以及专业领域智能系统的构建开辟更多可能性。
(参考文献略)

庄越挺
浙江大学学术委员会副主任,CAAI 常务理事,浙江大学求是特聘教授,国家杰青获得者、CAAI Fellow;教育部人工智能协同创新中心主任,数字图书馆教育部工程研究中心主任,浙江省计算机学会理事长。曾担任“973 计划”项目首席科学家,“百千万人才工程”国家级人选,教育部“网络多媒体智能信息处理技术”创新团队带头人。主要从事人工智能、多媒体信息检索、跨媒体计算理论、数字图书馆技术等领域研究,发表论文 300 余篇。
选自《中国人工智能学会通讯》 2024年第14卷第12期 大模型技术专栏
