**摘要
3D点云表示在保持物理世界的几何保真度方面发挥着至关重要的作用,使得对复杂三维环境的理解和交互更加精确。人类可以通过多感官系统自然地理解物体之间的复杂关系、空间布局及其变化,而人工智能(AI)系统尚未完全复现这一能力。为了弥合这一差距,整合多种模态(如图像、文本、音频和点云)变得尤为重要。能够无缝集成并在这些模态之间进行推理的模型被称为基础模型(Foundation Models, FMs)。 在2D模态(如图像和文本)方面,基础模型的研究取得了显著进展,这主要得益于大规模数据集的丰富性。然而,在3D领域,由于标注数据的稀缺性和高计算开销,其发展相对滞后。针对这一问题,近年来的研究开始探索将FMs应用于3D任务的潜力,借助现有的2D知识克服这些挑战。此外,语言作为一种能够进行抽象推理和环境描述的媒介,通过大规模预训练语言模型(LLMs)提供了一种增强3D理解的潜在途径。 尽管近年来FMs在3D视觉任务中的发展和应用取得了快速进展,但仍缺乏全面和深入的综述性研究。本文旨在填补这一空白,系统性地回顾当前最先进的利用FMs进行3D视觉理解的方法。我们首先回顾了构建3D FMs所采用的各种策略,然后对不同FMs在感知任务等领域的应用进行分类和总结。最后,我们对该领域的未来研究方向进行了探讨。本综述旨在为研究人员和实践者提供一个结构化的指南,既总结现有知识,也为未来的探索提供一条清晰的路线图。 此外,为了补充本综述,我们提供了一个相关论文的精选列表:https://github.com/vgthengane/Awesome-FMs-in-3D
**关键词
点云、3D视觉、基础模型、视觉-语言模型、大型语言模型、多模态模型
1 引言
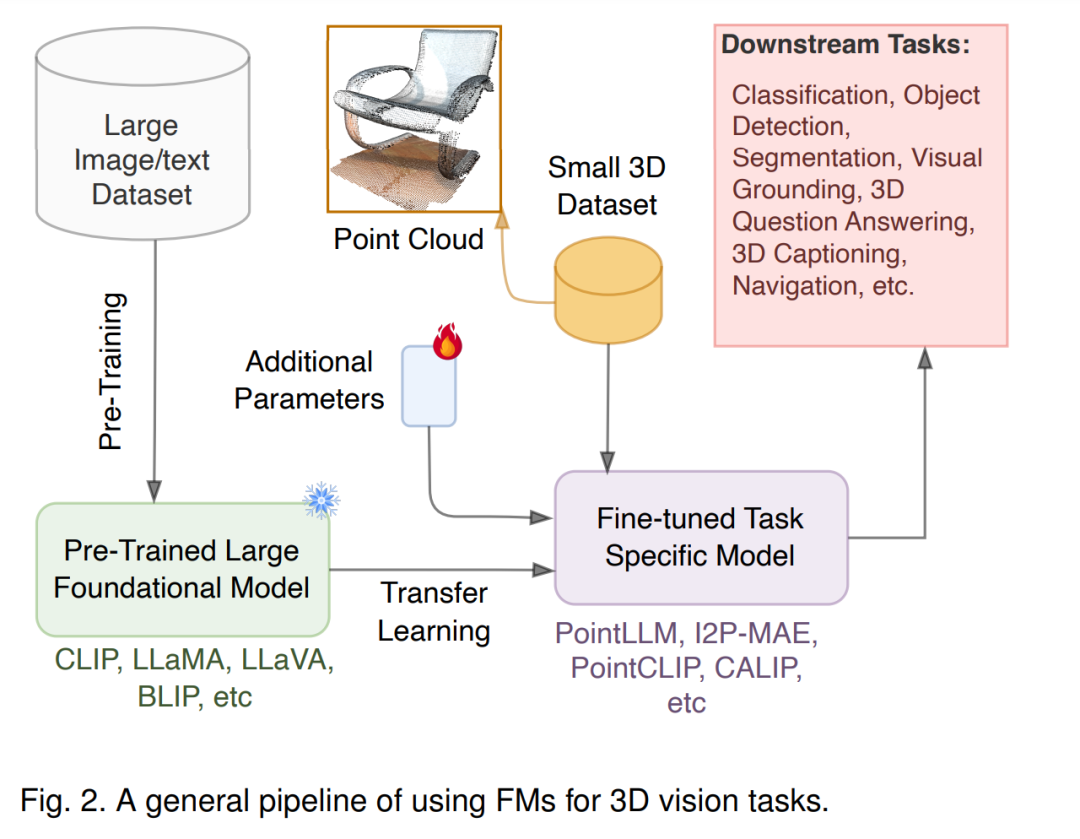
在当前推动人工智能(AI)系统向类人思维和行为发展的竞赛中,一个至关重要的因素是AI对三维(3D)世界的理解和导航能力。为了使AI系统能够有效地部署在现实环境中,它们必须具备稳健的三维世界感知能力[1]。三维世界可以采用多种形式进行表示,包括深度图像、网格(meshes)、体素网格(volumetric grids)和点云(point clouds)[2]。其中,点云是最常用的一种表示方式,由三维坐标系中的点集合构成[3]。 三维点云是空间数据表示领域中的核心范式[4],在多个领域发挥着关键作用,包括计算机视觉、机器人技术、自动驾驶、增强现实等[5]。在计算机视觉中,点云可用于精确建模现实场景,从而促进目标检测、场景理解和三维重建等任务[2]。同样,在机器人和自动驾驶领域,点云在感知和导航中起着至关重要的作用,有助于障碍物检测、环境建图和路径规划[6]。此外,在增强现实应用中,点云作为核心数据结构,支持虚拟对象在物理世界上的叠加,增强用户体验和交互[7]。总体而言,点云所蕴含的丰富信息和多功能性使其成为三维理解和交互不可或缺的工具。 尽管点云在三维数据处理中扮演着重要角色,但其应用仍面临诸多挑战。首先,三维数据集的采集过程复杂,成本高昂,且耗时较长[8]。此外,为点云数据提供用于目标识别、语义分割和推理等任务的标注(ground truth)极为繁琐,需依赖专业知识[9]。训练大规模模型需要处理海量数据集,这对计算资源和基础设施提出了较高要求,往往需要高性能计算系统[10]。更进一步,尽管点云能够捕捉几何细节,但其数据本质上是稀疏的,缺乏关于物体或场景的语义信息[11]。 这些挑战促使研究者们思考以下核心问题:我们能否利用其他数据模态,如图像、文本和音频,以增强对三维数据的理解,并借助能够提取特征的模型实现这一目标?此外,我们能否在无需大量数据采集和昂贵模型训练的情况下,弥补数据、标注和语义信息的缺失? 这种思考催生了基础模型(Foundation Models, FMs)。“基础模型”一词首次由文献[12]提出,指的是基于大规模数据集进行自监督学习训练的深度学习模型。这类模型展现出前所未有的适应性,可跨多种任务和领域应用,其特点包括预训练[13]、可泛化性、可通过迁移学习进行适配[14],在模型规模和数据规模上都具备大规模性,以及以自监督学习为核心的训练方式。 尽管基础模型(FMs)的基本组成部分(如神经网络和迁移学习)已存在多年,但近年来,它们在自然语言处理(NLP)领域取得了显著进展,尤其是在大型语言模型(LLMs)如BERT和GPT-3的推动下[15, 16]。随着NLP的成功,计算机视觉(CV)领域也取得了类似进展。例如,视觉-语言模型(Vision-Language Models, VLMs),如CLIP[17],在大规模图像-文本数据集上进行训练,在多个下游任务中展现出卓越的泛化能力[18, 19]。进一步地,SAM等模型[20]针对分割任务的适应性,使其能够用于无类别约束(class-agnostic)的分割应用,包括医学图像分割[21]和三维视觉任务[22]。 为了更有效地理解三维世界,研究者尝试结合图像、文本和音频等多模态信息,并借助基础模型(FMs)推动多种方法的发展[1]。例如,一种研究方向是利用二维基础模型(2DFMs)构建三维基础模型(3DFMs)[23, 24]。另一种方向是利用这些2DFMs进行点云分类[25, 18]、语义分割[26, 27]和目标检测[28, 29]等任务。此外,随着开源大型语言模型(LLMs)[30, 31, 32]的出现,一些方法已被提出用于三维理解,涵盖物体级别[33, 34]和场景级别[35, 36]的任务。尽管LLMs本质上是为基于文本的推理设计的,但它们可以通过与视觉模型结合来适用于三维任务。例如,LLMs从文本描述或指令生成的嵌入向量可以与三维模型的特征进行对齐,从而实现视觉定位(visual grounding)[37]、三维文本描述(3D captioning)[38]和三维问答(3D question-answering)[39]等任务。 尽管2DFMs在三维视觉任务中的应用取得了快速发展和广泛采用,但现有文献仍缺乏对这些方法的深入总结。为填补这一空白,我们提出了一份全面且结构化的指南,旨在为研究人员和实践者提供权威参考。
分类体系(Taxonomy)
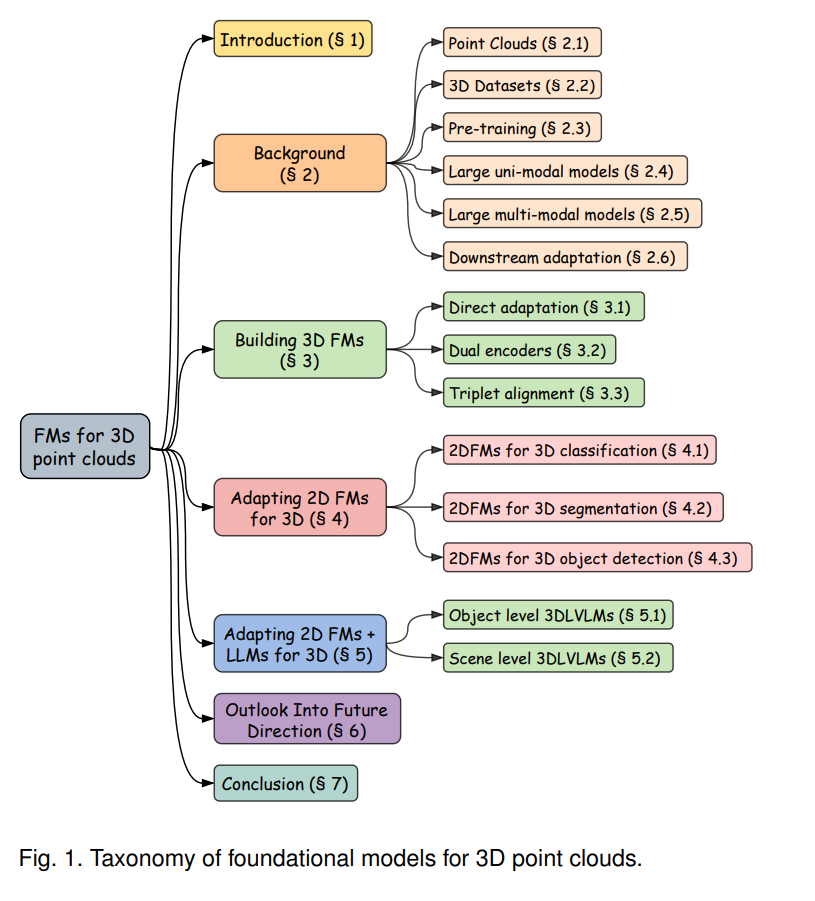
本综述详细分析了用于三维点云理解的二维基础模型(2DFMs)。它旨在为研究人员提供帮助,无论是新入门者还是经验丰富的专家,并通过结构化的分类体系(如图1所示)帮助理解关键概念。我们首先在第2节奠定基础,详细讨论点云、可用数据集、单模态和多模态模型以及下游任务适配等核心主题。随后,第3节探讨了利用2DFMs构建3D基础模型(3DFMs)的早期研究工作。接着,第4节分析了这些2D-和3DFMs在分类、分割和检测等3D任务中的应用。同样地,第5节探讨了2D-和3DFMs与LLMs结合以解决3D任务的研究进展。整个综述中,我们总结了相关方法,并分析了它们在不同数据集上的表现。此外,第6节展望了当前的局限性及未来发展方向,并在第7节对本综述进行总结。
研究范围(Scope)
本综述聚焦于针对三维点云的基础模型(FMs)。这些FMs涵盖了单模态模型(主要为文本处理的大型语言模型LLMs),如LLaMa[30]、GPT-3[16]和Vacuna[31],以及其多模态扩展模型,如CLIP[17]、SAM[20]、ImageBind[40]及其变体[41],以及融合LLMs的多模态模型,如LLaVa[42]和MiniGPT-4[43]。我们排除了使用2DFMs进行图像生成、操作或渲染的研究,因为这些方向已在现有文献中得到广泛覆盖。此外,我们未涉及医学影像或遥感等特定领域的应用,因为这些方向更适合独立的综述论文。相反,我们提供了对现有文献的全面概述,这些研究可广泛适用于多个领域。
相关综述(Related Surveys)
我们将本综述与现有三维点云相关文献进行比较。Guo等人[44]对深度学习在三维点云处理中的应用进行了全面回顾。此外,[5, 2, 45]提供了针对基于Transformer架构模型的详细分析,但仅关注于这一特定类别的模型。一些研究总结了自动驾驶领域的三维目标检测方法[6, 46, 47, 48],但未涵盖更广泛的三维应用。此外,这些综述较为过时,未能反映近年来利用预训练大模型进行三维理解的最新进展。Awaise等人[49]对2DFMs在计算机视觉任务中的应用进行了总结,但未涉及三维应用。其他文献如[7, 50]研究范围较为局限,例如,[7]仅关注于点云的自监督学习方法,[50]专注于点云的标签高效(label-efficient)学习方法。相比之下,我们的综述旨在提供尽可能全面的方法列表,涵盖利用2D/3D FMs解决各类三维下游任务的最新研究进展。
特性(Features)
本综述是首个对三维点云学习领域的基础模型(FMs)进行全面探讨的研究,填补了当前文献中的重要空白,旨在为新入门者和资深研究人员提供一个起点和参考指南。本综述的核心特性包括: ▶ 三维视觉任务与数据集背景介绍:提供点云基础知识,并概述用于训练和评估的多种数据集,重点分析其关键特性及面临的挑战。 ▶ 基础模型(FMs)及关键概念讨论:简明扼要地解释FMs的概念和重要术语,以确保读者能够清晰理解其在不同应用场景中的作用。 ▶ 方法的全面分析:详细回顾现有方法,并与替代方案进行比较,使读者能够清楚地理解各方法的优缺点及其适用场景。
贡献(Contributions)
本研究的主要贡献如下: ▶ 全面的背景介绍:我们介绍了三维点云的基本概念、现有可用的数据集,以及基础模型(FMs)及相关术语。这一背景知识为理解综述中讨论的方法奠定了基础。 ▶ 结构化分类体系(Taxonomy):我们提出了一种结构化的分类体系,使新研究人员能够快速理解该领域的核心概念,同时为资深研究者提供深入探索当前趋势的途径。该分类体系按照不同任务、模型适配策略以及其他重要因素对方法进行分组,以便更好地组织和理解现有文献。 ▶ 对未来发展方向的深入探讨:此外,我们基于本综述讨论的研究成果,对未来发展趋势进行了深入分析。内容涵盖数据集构建、模型适配三维任务的有效方法,以及该领域的其他新兴趋势。 通过对基础模型(FMs)、分类体系、数据集及方法的全面综述,本研究为研究人员、从业者和爱好者提供了有价值的指导,旨在推动三维世界理解领域的发展。