

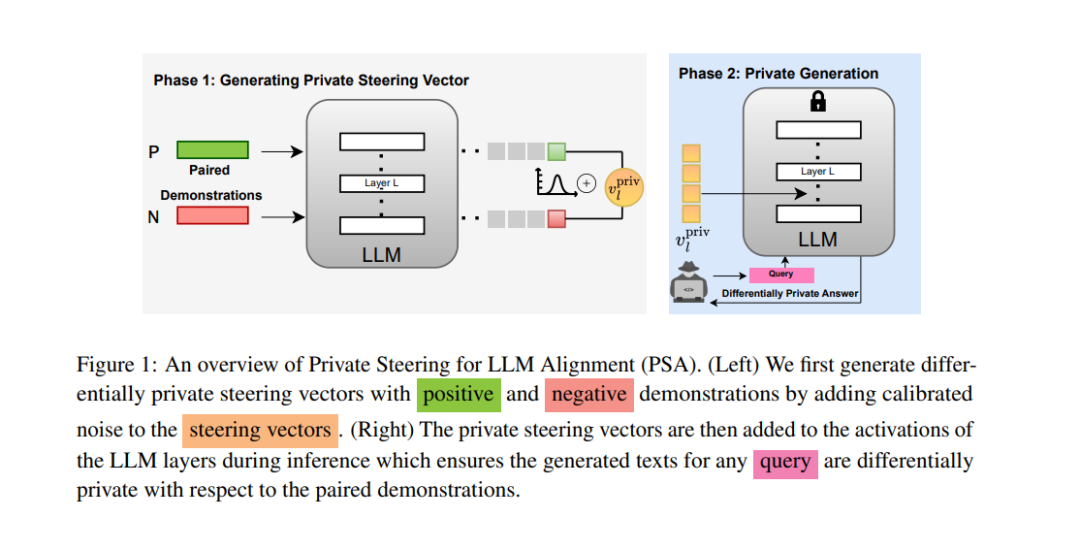
对齐大型语言模型(LLM)以符合人类价值观并避免不良行为(如幻觉)变得日益重要。近年来,通过激活编辑(activation editing)引导 LLM 朝向期望行为已成为一种有效的方法,可在推理时缓解有害生成内容。激活编辑通过保留正向示例(如真实信息)并最小化负向示例(如幻觉)的信息来修改 LLM 的表示。然而,当这些示例来自私有数据集时,经过对齐的 LLM 可能会泄露其中包含的私有信息。在本研究中,我们首次探讨了使用私有数据集对齐 LLM 行为的问题。我们提出了一种新算法——用于 LLM 对齐的差分隐私引导(PSA, Private Steering for LLM Alignment),该算法能够在差分隐私(DP, Differential Privacy)的保证下编辑 LLM 的激活状态。我们在七个不同的基准测试上进行了广泛实验,涉及不同规模(0.5B 到 7B 参数量)和不同模型家族(LLaMa、Qwen、Mistral 和 Gemma)的开源 LLM。实验结果表明,PSA 在保持 LLM 对齐的同时提供了 DP 保证,并且性能损失极小,包括对齐度量、开放式文本生成质量以及通用推理能力。此外,我们还提出了首个针对激活编辑的成员推理攻击(MIA, Membership Inference Attack),用于评估和审计 LLM 引导过程中的经验隐私。该攻击方法专为激活编辑设计,仅依赖于 LLM 生成的文本,而无需访问关联的概率分布。实验结果表明,与现有的非隐私保护技术相比,PSA 算法提供了更强的隐私保证,同时符合理论分析结果。
成为VIP会员查看完整内容