

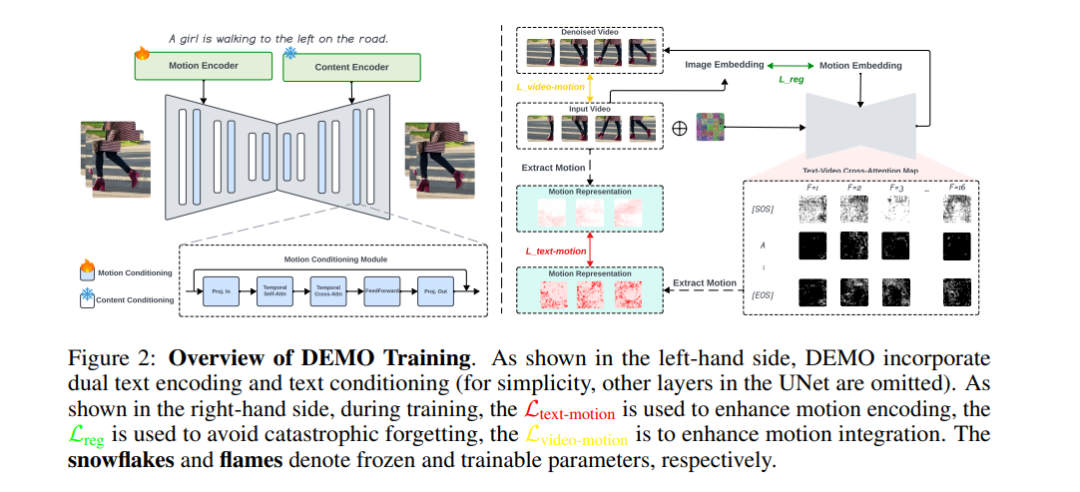
尽管文本到视频(T2V)生成技术已经取得了进展,制作具有真实运动的视频仍然具有挑战性。当前模型通常产生静态或动态变化极少的输出,未能捕捉文本中描述的复杂运动。这个问题源于文本编码中的内部偏差,这些偏差忽视了运动,并且T2V生成模型的条件机制不足。为了解决这个问题,我们提出了一种新颖的框架,称为分解运动(DEMO),该框架通过将文本编码和条件控制分解为内容和运动组件来增强T2V生成中的运动合成。我们的方法包括一个用于静态元素的内容编码器和一个用于时间动态的运动编码器,以及单独的内容和运动条件控制机制。关键是,我们引入了文本-运动和视频-运动的监督,以提高模型对运动的理解和生成能力。在MSR-VTT、UCF-101、WebVid-10M、EvalCrafter和VBench等基准测试中的评估表明,DEMO在生成具有增强运动动态的视频方面表现优越,同时保持高视觉质量。我们的方法通过直接从文本描述中整合全面的运动理解,显著推动了T2V生成的进展。项目页面:https://PR-Ryan.github.io/DEMO-project/
成为VIP会员查看完整内容
相关内容
Arxiv
36+阅读 · 2023年4月19日
Arxiv
169+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
169+阅读 · 2023年4月7日