

尽管形式各异的视觉数据(如图片和视频)的呈指数级增长,为我们解释周围环境提供了前所未有的机会,自然语言依然是我们传递知识和信息的主要方式。因此,目前迫切需要构建一个框架来实现不同模态信息之间的交互。在这篇论文中,我研究了实现多模态信息有效交互的三个方向。第一个方向关注于构建具有相似语义意义信息的一致性表示。更具体地说,在高维语义空间中,相似信息的表示应该在适当的范围内彼此接近,不论它们的模态如何。第二个方向是实现图像视觉属性与相应语义词之间的有效关联,这首先要求网络能够识别图像和文本中的不同语义信息,然后允许它们进行交互。第三个方向是构建一个轻量级架构的模型,用于处理来自多个域的输入。这是因为当网络涉及多模态信息时,可能需要大量增加可训练参数的数量,其目的是允许网络全面学习捕捉具有域间差异的信息之间的相关性。需要大量计算资源的要求可能会极大地阻碍框架的部署,这对于现实世界应用中的实现来说是不切实际的。这些方向的贡献如下。
首先,为了有一个一致的表示,生成网络采用了对比学习和聚类学习,其中对比学习可以最大化由给定数据集提供的成对实例之间的互信息,而聚类学习可以将具有相似语义意义的实例分组到同一个簇中,并将不同的实例推得彼此远离。通过这样做,可以构建一个结构化的联合语义空间,在这个空间内,具有相似语义意义的实例可以在适当的范围内紧密地聚集在一起,以确保不论其模态如何,都能有一个一致的表示。
其次,为了实现多模态信息之间的有效关联,提出了三种不同的方法,有效地将图像视觉属性与相应的语义文本描述相关联,使网络学习理解文本和图像信息的语义意义,然后实现有效的交互。更特别的是,为了探索相关性,我首先研究了基于单词级别注意力的连接,并辅以补充的单词级别鉴别器,其中注意力允许网络学习识别与相应语义词对齐的特定图像视觉属性,而补充的单词级别鉴别器提供细粒度的训练反馈,以允许网络正确捕捉这种关联。然后,介绍了文本-图像仿射组合,采用仿射变换将文本和图像特征结合在生成过程中,使网络具有区域选择效应,有选择地将文本所需的图像属性融合到生成流程中,并保留与文本无关的内容。此外,提出了一种半参数的记忆驱动方法,它结合了参数技术和非参数技术的优点。非参数组成部分是一个存储库,由训练数据集构建而成的预处理信息库,而参数组成部分是一个神经网络。通过这样做,参数方法可以实现高度表达模型的端到端训练的好处,非参数技术允许网络在推理时充分利用大型数据集。
第三,提出了两种解决方案来减轻由于不同模态输入而需要的网络计算资源成本,允许网络在各个领域中轻松实施。更具体地说,我们改进了条件GAN中生成器和鉴别器的能力,以避免盲目增加网络的可训练参数数量,并构建了一个单向鉴别器,将两个训练目标(即获得更好的图像质量和文本-图像语义对齐)结合到一个方向(即提高融合特征的质量)中,以减少条件GAN中的冗余。这项工作为构建一个轻量级框架铺平了道路,该框架旨在实现多模态信息之间的有效交互,并且也可以轻松部署在各种真实世界的应用中。
引言
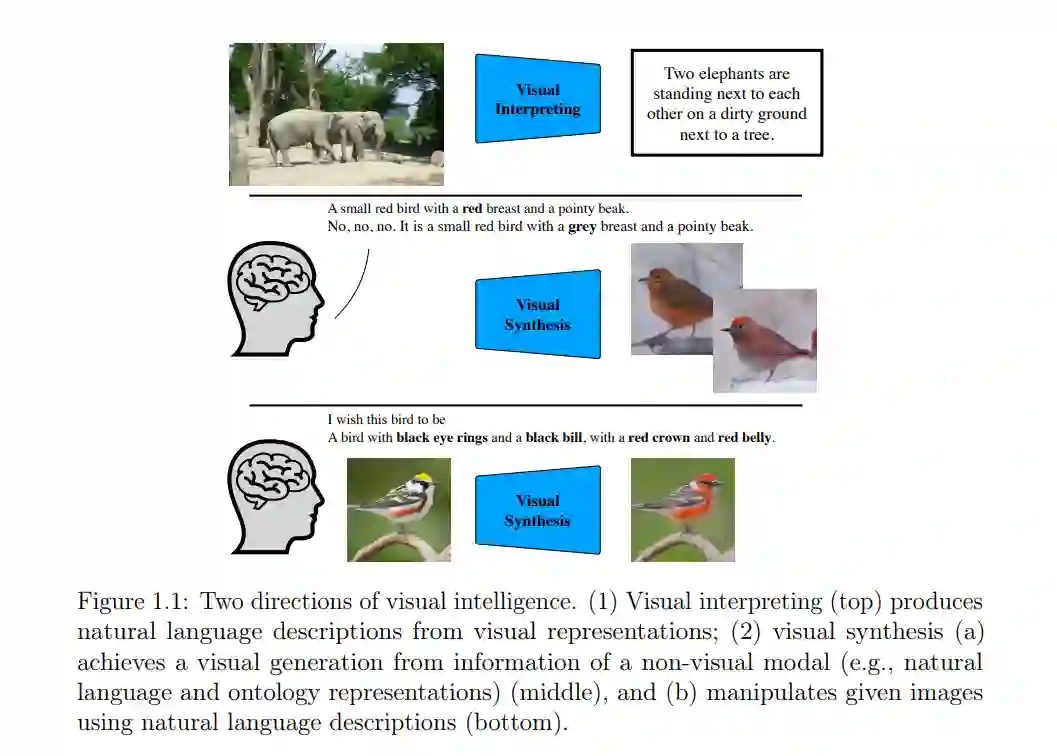
视觉感知是人类解释周围环境的最重要能力之一。每天,人类消耗的视觉信息量令人难以置信,他们观看视频、拍照、欣赏绘画以及在社交媒体上分享。例如,YouTube每天几乎有50亿视频被观看;仅Instagram每天就有超过9500万照片被上传。如此大量的视觉数据的可用性为研究人员提供了前所未有的机会来构建各种视觉解释和合成方法,如(1)物体/场景分类(He等,2016年;Simonyan和Zisserman,2014年;Szegedy等,2015年,2016年;Zhou等,2014年b),(2)物体检测(Girshick等,2014年;Long等,2015年;Ren等,2015年;Ronneberger等,2015年;Howard等,2017年;Redmon等,2016年),(3)图像描述(Donahue等,2015年;Xu等,2015年),(4)视觉问题回答(Andreas等,2016年;Johnson等,2017年;Lu等,2016年;Nam等,2017年;Antol等,2015年;Anderson等,2018年;Yang等,2016年),(5)文本到图像生成(Reed等,2016年b;Xu等,2018年;Zhang等,2017年a,2018年a),(6)图像到图像翻译(Isola等,2017年;Park等,2019年;Wang等,2018年;Zhu等,2017年),(7)文本引导的图像操作(Dong等,2017年;Li等,2020年a,c;Nam等,2018年),(8)故事可视化(Li等,2019年c;Song等,2020年;Maharana等,2021年;Maharana和Bansal,2021年)等等。这些方法旨在实现多模态表征之间的跨域转换,例如,将非视觉数据(如自然语言描述或场景图)转换成视觉信息(如视频或图像),反之亦然,并旨在实现它们之间的有效交互。 在这篇论文中,我专注于探索实现多模态信息(例如,语言和视觉信息)之间有效交互的原则,包括(1)如何在一个联合语义空间中为这些信息构建一致的表示,(2)如何有效地连接并融合来自不同模态的特征,以及(3)如何减轻计算需求以实现有效的交互。我的研究可以在许多领域启用无数潜在的应用,包括设计、视频游戏、艺术、建筑和医学诊断等等。
为了实现多模态信息之间的有效交互,首先,重要的是对具有相似语义含义的信息有一个一致的表征。这是因为来自不同领域的信息可能有它们自己的表征形式,因此,在一个高维语义空间中,这些特征的位置可能会彼此相距甚远,即使它们表达的是相似的语义含义。即使是来自同一领域的信息也会发生这种情况(Mikolov等人,2013年),例如,对于意思相同但使用同义词的两个句子,比如“猫”和“小猫”,它们在语义空间中的表征可能不会完全相同。当特征的维度增加时,这种情况可能会变得更糟,这是由维度的诅咒(Bellman,1966年)引起的:随着特征或维度的数量增长,我们需要准确概括的数据量呈指数增长。所以,一个问题出现了:如何为具有相似语义含义的同一领域或不同领域的信息构建一致的表征?这一点很重要,因为具有一致的表征意味着具有相似语义含义的信息可以在高维语义空间中有固定且接近的位置,因此即使来自不同模态的信息也可以在空间中的适当范围内容易地从一个转换到另一个,这与本论文实现多模态信息之间有效交互的目标是一致的。
为了考虑实例之间的相似性,我们首先从对比学习中寻求帮助,对比学习是自监督表征学习的一个强大方案(Oord等人,2018年;He等人,2020年;Chen等人,2020年;Zhang等人,2021年),它可以通过对比正样本对和负样本对来强化不同增强下的表征一致性。然而,对比学习并没有考虑样本的语义信息和语义相似性,它简单地将两个样本视为正样本对,只要它们位于将通过网络传播的训练样例的相同位置(即在同一个批次中),并且当它们在不同的批次中时视为负样本对,而不考虑它们的语义信息。通过这种做法,学到的表征可能会受到相当大的影响。例如,简单采用对比学习可能会将具有相似语义含义但在不同批次中的实例推得相距甚远,从而可能破坏它们之间的语义一致性。
为了考虑样本之间的相似性,聚类算法(Alwassel等人,2020年;Asano等人,2020年;Caron等人,2020年;Li等人,2020年d)可以补救上述问题,聚类算法将相似的实例(即具有相似语义含义的实例)分组到同一个簇中,并将不同的实例推到不同的簇中。因此,对比学习和聚类学习互为补充,采用对比学习可以让我们更好地探索跨模态的互信息,并且使用聚类学习将具有相似语义含义的信息分组到同一个簇中,从而实现一致的表征。更多细节将在第三章中呈现。
在为具有相似语义含义的同一或不同模态信息建立了一致的表征之后,另一个问题出现了:如何实现这些信息之间的有效交互?更具体地说,如何有效地构建图像中的视觉特征与句子中相应的语义词之间的连接?这是因为机器需要理解给定文本描述的语义含义,并且识别特定的图像区域,然后它才能生成具有文本要求的对象和属性的图像,或者修改特定的图像区域以匹配给定的文本描述。
为了实现不同模态信息之间的有效交互,提出了三种方法:(1)基于词级注意的连接,辅以补充的词级鉴别器提供细粒度的训练反馈,(2)文本-图像仿射组合模块,以及(3)基于记忆的方法。这些方法使网络能够有效地将图像区域的视觉属性与相应的语义词联系起来。更多细节将在第四章中呈现。
在有了一个框架以实现多模态信息之间的有效交互之后,又出现了一个问题:这个框架能否在大多数设备中轻松部署?更具体地说,有可能开发一个不依赖昂贵计算资源的框架吗?这主要是因为,当一个网络涉及到不同模态的信息时,可能需要大量增加可训练参数的数量,这旨在让网络能够全面学习捕捉多模态信息之间的相关性,并弥合领域差距。需要大量计算资源的要求可能会大大阻碍这个框架的部署,这对于实际应用中的实现来说是不切实际的。为了解决这些问题,我们提出提高基于GAN网络的生成器和鉴别器的能力,并重新思考条件GAN中鉴别器的架构,而不是盲目地通过增加大量的可训练参数来增加网络的特征维度。更多细节将在第五章中呈现。




相关内容

牛津大学是一所英国研究型大学,也是罗素大学集团、英国“G5超级精英大学”,欧洲顶尖大学科英布拉集团、欧洲研究型大学联盟的核心成员。牛津大学培养了众多社会名人,包括了27位英国首相、60位诺贝尔奖得主以及数十位世界各国的皇室成员和政治领袖。2016年9月,泰晤士高等教育发布了2016-2017年度世界大学排名,其中牛津大学排名第一。
