辨识性特征学习及在细粒度分析中的应用
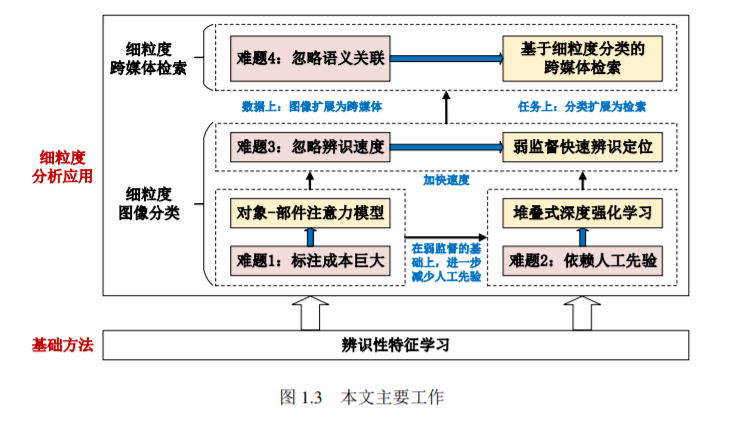
细粒度分析旨在对粗粒度的大类进行细粒度的子类划分,如把鸟划分为里海燕鸥、 北极燕鸥等子类别。其广泛应用于智能农业、智能医疗等智能产业,具有重要的研究 和应用价值。其挑战在于类间差异小、类内差异大。以图像为例,不同子类别在形状、 颜色上差异细微,难以区分;相同子类别在姿态、视角上差异显著,容易误分。因此, 关键科学问题是:如何获取细粒度子类别的辨识性信息并有效表达,突破细粒度分析难题。针对上述问题,本文从减少标注成本、减少人工先验、提高辨识速度、提高语义 关联四个方面展开辨识性特征学习研究,并分别应用于细粒度图像分类和细粒度跨媒 体检索任务。主要工作总结如下:
-
在减少标注成本上,提出了基于对象-部件注意力模型的细粒度图像分类方法。在对象级注意力上,提出注意力选择和显著性提取,自动定位对象区域,学习更 精细的对象特征。在部件级注意力上,提出空间关联约束和部件语义对齐,实现 辨识性部件的有效定位,排除了姿态、视角等差异的干扰。两者结合能够学习 到多粒度的辨识性特征,准确率超过了使用对象、部件人工标注的强监督方法。
-
在减少人工先验上,提出了基于堆叠式深度强化学习的细粒度图像分类方法。首 先,层次化地定位图像中的多粒度辨识性区域,并自适应地确定其数目。然后, 通过多尺度区域的定位及辨识性特征学习,进一步提升细粒度图像分类准确率。学习过程由语义奖励函数驱动,能够有效捕捉图像中的辨识性、概念性的视觉 信息,实现弱监督甚至无监督条件下的辨识性特征学习。
-
在提高辨识速度上,提出了基于弱监督快速辨识定位的细粒度图像分类方法。首 先,提出多级注意力引导的辨识性定位,通过显著图生成伪监督信息,实现了 弱监督条件下的辨识性定位。进一步显著图驱动二次定位学习,增强了定位的 准确性。然后,提出多路端到端辨识性定位网络,实现多个辨识性区域的同时 定位,从而提高了辨识速度。多个辨识性区域之间互补促进,提升细粒度图像 分类准确率。
-
在提高语义关联上,引入文本、视频、音频等跨媒体数据,提出了基于细粒度 分类的跨媒体检索方法。建立了首个包含 4 种媒体类型(图像、文本、视频和 音频)的细粒度跨媒体检索公开数据集和评测基准 PKU FG-XMedia。提出了能 够同时学习 4 种媒体统一表征的深度模型 FGCrossNet,确保统一表征的辨识性、 类内紧凑性和类间松散性。实现图像向跨媒体的扩展,分类向检索的扩展。