CL(Annual Meeting of the Association for Computational Linguistics) 2024,即第62届国际计算语言学年会,正在2024年8月11日至8月16日在泰国曼谷召开。ACL 会议是计算语言学和自然语言处理领域排名第一的顶级学术会议,也是研究者展示最新成果、交流学术思想的重要平台。ACL是CCF(中国计算机学会)为A类的会议,近几年录取率在**20%**左右。

最佳论文

https://arxiv.org/abs/2406.04327
理解语言模型中的记忆现象具有实际和社会意义,例如研究模型的训练动态或防止侵犯版权。先前的研究将记忆定义为训练过程中使用某个实例对模型预测该实例能力的因果影响。这一定义依赖于反事实:观察如果模型未见过该实例会发生什么的能力。现有方法难以提供计算上高效且准确的反事实估计。此外,它们通常估计的是模型架构的记忆能力,而不是特定模型实例的记忆能力。本文填补了文献中的一个重要空白,提出了一种新的、原则性和高效的方法,基于计量经济学中的差分法设计来估计记忆现象。使用该方法,我们通过仅观察训练过程中的一小部分实例来表征模型的记忆特征——即其在整个训练过程中记忆趋势的表现。在使用Pythia模型套件的实验中,我们发现:(i) 较大的模型中记忆现象更强且更持久;(ii) 记忆现象受数据顺序和学习率的影响;(iii) 记忆趋势在不同模型规模中具有稳定性,因此可以从较小模型预测较大模型中的记忆现象。

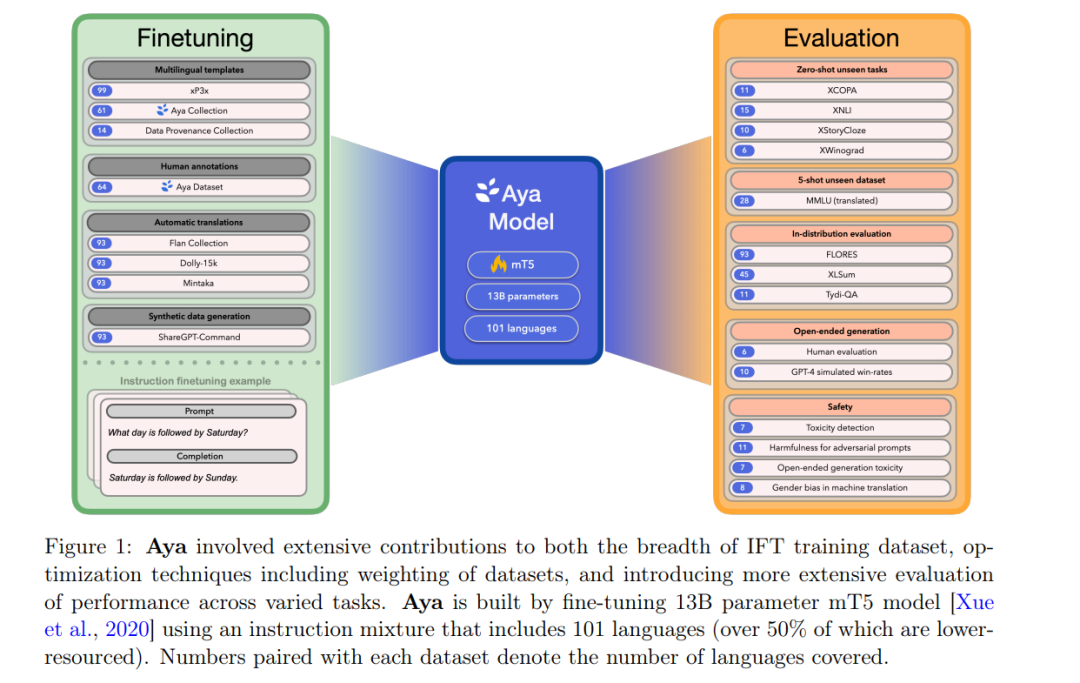
近年来,大型语言模型(LLMs)的突破主要集中在少数数据丰富的语言上。那么,如何才能将这些突破扩展到那些非主流语言上呢?我们的工作介绍了Aya,这是一种大规模多语言生成语言模型,能够在101种语言中遵循指令,其中超过50%的语言被认为是资源较少的语言。Aya在大多数任务中优于mT0和BLOOMZ,同时覆盖的语言数量是它们的两倍。我们引入了广泛的新评估套件,扩展了多语言评估的最先进水平,覆盖了99种语言——包括判别性和生成性任务、人类评估,以及涵盖持出任务和分布内性能的模拟胜率。此外,我们还对最佳微调混合组成、数据剪枝,以及我们模型的毒性、偏见和安全性进行了详细调查。我们在 https://hf.co/CohereForAI/aya-101 开源了我们的指令数据集和模型。

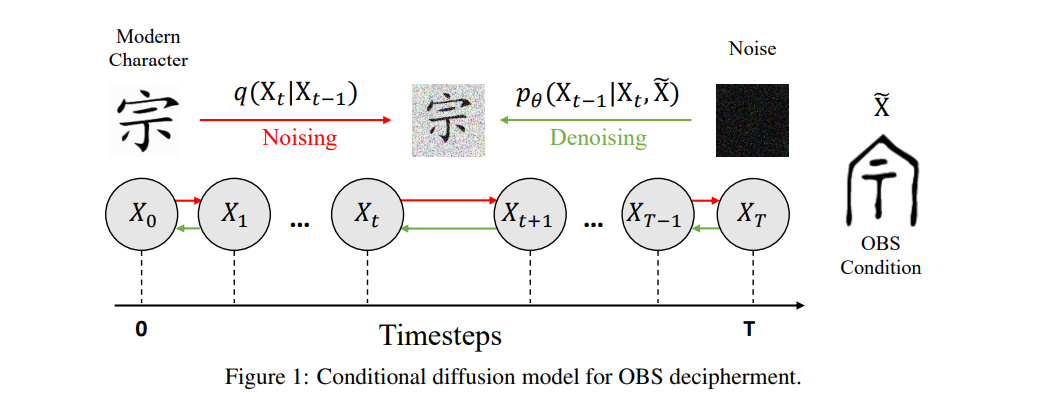
甲骨文起源于大约3000年前的中国商朝,是语言史上的一个重要基石,早于许多已建立的书写系统。尽管已经发现了数千条铭文,但大量的甲骨文仍未被解读,为这一古老语言蒙上了神秘的面纱。现代AI技术的兴起为甲骨文的解读开辟了一个新的前沿,挑战了传统的自然语言处理方法,这些方法通常依赖于大量的文本语料库,而历史语言往往不具备这种条件。本文介绍了一种新颖的方法,通过采用图像生成技术,特别是开发了甲骨文解读器(OBSD),利用条件扩散策略,OBSD生成了解读的重要线索,为AI辅助分析古代语言开辟了一条新途径。为了验证其有效性,我们在甲骨文数据集上进行了广泛的实验,定量结果显示了OBSD的有效性。代码和解读结果将在 https://github.com/guanhaisu/OBSD 上提供。

乔姆斯基等人非常明确地声称,大型语言模型(LLMs)同样能够学习人类可能和不可能学习的语言。然而,目前几乎没有发表的实验证据支持这一说法。在本文中,我们开发了一组具有不同复杂性的合成不可能语言,每种语言都是通过系统地改变英语数据中的不自然词序和语法规则设计的。这些语言位于一个“不可能性”连续体上:一端是本质上不可能的语言,例如英语单词的随机且不可逆的打乱,而另一端则是那些可能直觉上并非不可能但在语言学中通常被认为是这样,特别是那些基于计数单词位置规则的语言。我们报告了一系列广泛的评估,以评估GPT-2小模型学习这些无可争议的不可能语言的能力,关键是,我们在训练的各个阶段进行这些评估,以比较每种语言的学习过程。我们的核心发现是,与作为对照的英语相比,GPT-2在学习不可能语言时表现出困难,这对核心主张提出了挑战。更重要的是,我们希望我们的方法能够开辟一条富有成效的研究路径,在这条路径上,通过测试不同的LLM架构在各种不可能语言上的表现,可以进一步了解如何将LLMs用作认知和类型学研究的工具。


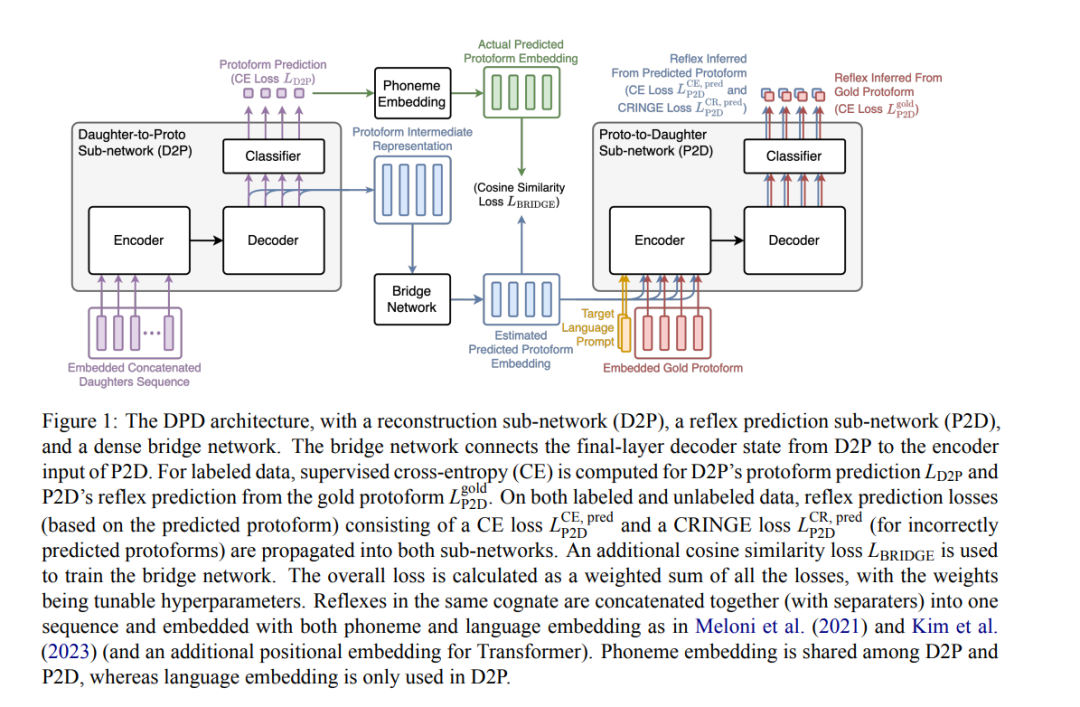
现有的祖先语言(原始语言)比较重建工作通常需要完全监督。然而,历史重建模型只有在可以用有限的标注数据进行训练时才具有实际价值。我们提出了一种半监督的历史重建任务,其中模型仅在少量标注数据(具有原始形式的同源词集合)和大量未标注数据(不具有原始形式的同源词集合)上进行训练。我们提出了一种用于比较重建的神经架构(DPDBiReconstructor),它结合了语言学家比较法的一个重要见解:重建的词汇不仅应当能够从其子语言词汇中重建出来,而且还应该可以确定性地转化回其子语言词汇。我们展示了这一架构能够利用未标注的同源词集合,在这个新任务中优于强大的半监督基线方法。

实证研究发现了Transformer模型在可学习性方面的一系列偏差和局限性,例如在学习计算简单形式语言(如PARITY)时存在持续的困难,以及对低度函数的偏好。然而,理论理解仍然有限,现有的表现能力理论要么过高预测,要么过低预测了现实中的学习能力。我们证明,在Transformer架构下,损失景观受输入空间敏感性的约束:输出对输入字符串的许多部分敏感的Transformer在参数空间中处于孤立点,导致在泛化时表现出低敏感性偏差。我们从理论上和实证上展示了这一理论统一了关于Transformer学习能力和偏差的广泛实证观察,例如它们在泛化时的低敏感性和低度偏差,以及在PARITY任务中的长度泛化困难。这表明,要理解Transformer的归纳偏差,不仅需要研究它们的理论表现能力,还需要研究它们的损失景观。
ACL最佳社会影响力论文奖


ACL最佳资源论文奖