
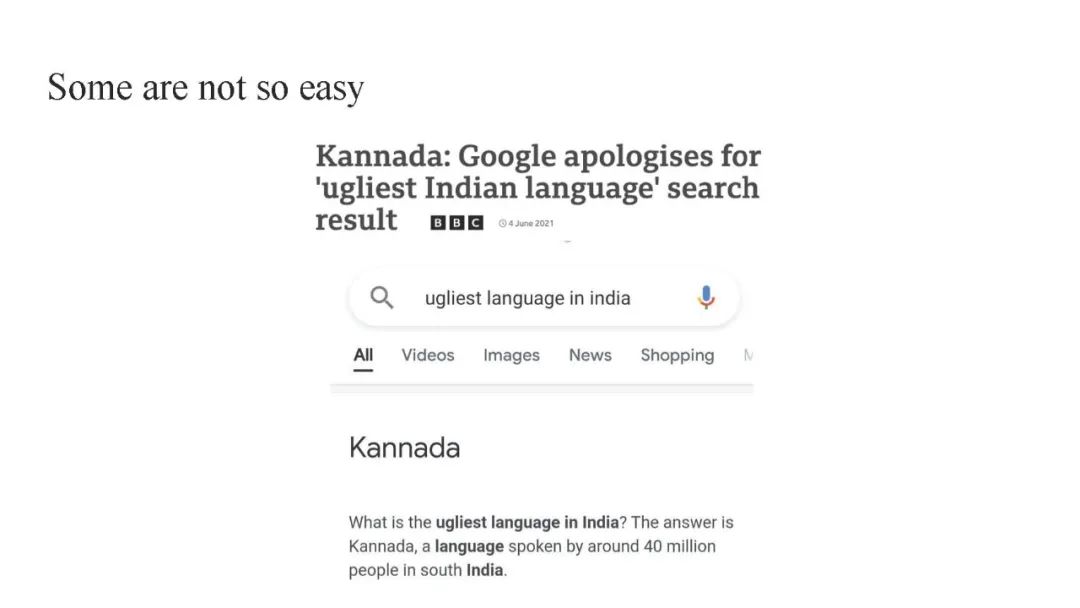
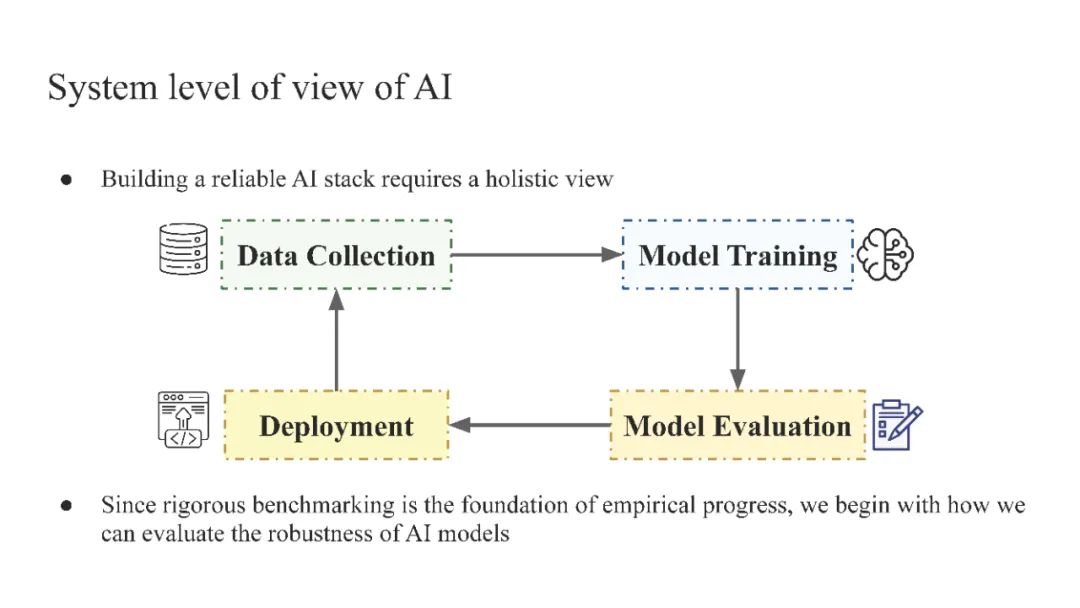
数据异质性是决定机器学习系统性能的关键因素。标准算法优化平均情况性能时,并未考虑数据内部的多样性。因此,数据来源、数据生成机制和子群体的变化导致了不可靠的决策、较差的泛化能力、不公平和错误的科学发现。仔细建模数据异质性是构建可靠数据驱动系统的必要步骤。其严谨的研究是一个新兴研究领域,涵盖了多个学科,包括统计学、因果推断、机器学习、经济学和运筹学。 在这个教程中,我们发展了一个统一视角来理解不同社区发展的不同知识脉络。我们旨在通过提供基于共享语言的统一视角来促进跨学科研究。汲取多个独立文献的精华,我们建立了异质性的分类,并介绍了考虑异质性数据的定量度量和学习算法。为了推动实证进展,我们最后讨论了验证协议和基准测试实践。 教程:









成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日