
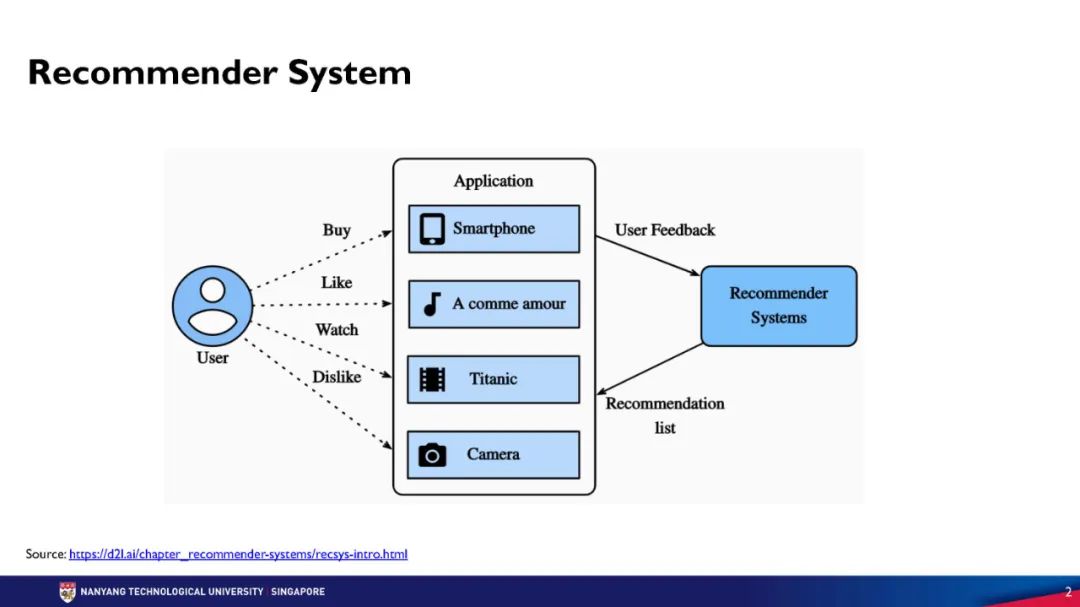
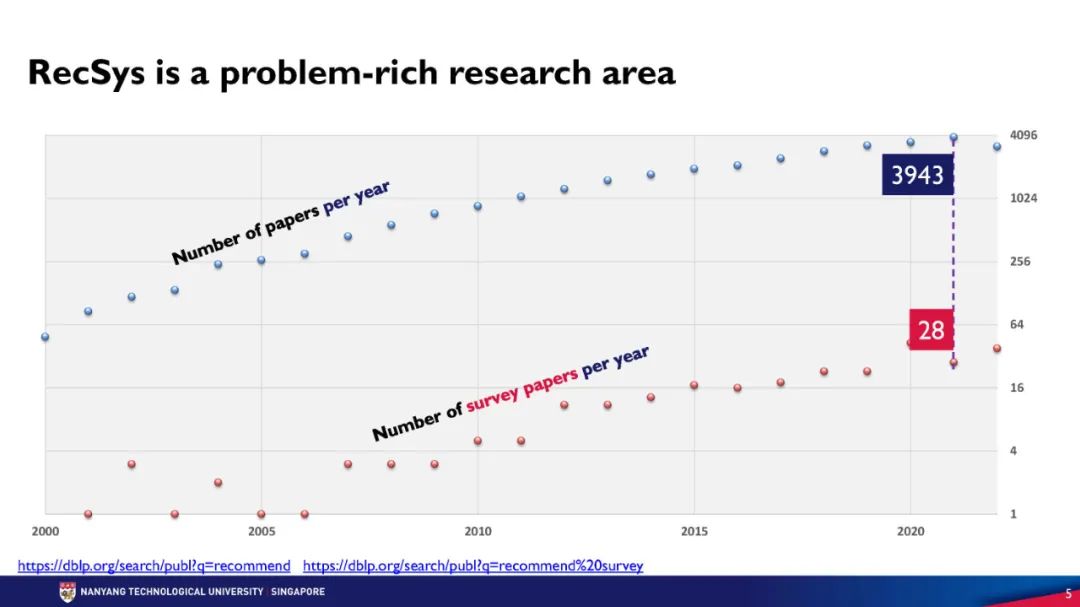
在过去的20年里,推荐系统(RecSys)领域在学术界和工业界都得到了极大的关注。我们并不缺乏关于各种RecSys模型或来自工业界在线系统的研究论文。然而,在离线环境下的模型评估方面,许多研究者简单地遵循常用的实验设置,并没有深入探讨RecSys问题的独特特点。在这个教程中,我将简要回顾RecSys中常用的评估方式,然后讨论在离线环境下评估推荐系统的挑战。主要的强调是在评估中考虑全局时间线,特别是当数据集涵盖从长时间段收集的用户-项目交互时。
大纲 本教程以RecSys评估的新视角结束,探讨如何在考虑全球时间线的情况下进行更有意义的评估。以下是按项目视图列出的主题: 第一部分 介绍 (10分钟) – 推荐系统基础 – 由RecSys驱动的应用 常用的RecSys评估指标 (20分钟) – 学术研究中常用的指标 – 在线环境中用于不同应用的指标,例如电商、广告、视频、音乐和新闻推荐。 第二部分 计算离线指标的挑战 (40分钟) – 以流行度为例,介绍RecSys在实践中的工作原理 – 使用离线数据集的RecSys实验中的数据划分方案 – 由于未维护全局时间线而导致的数据泄漏 – 对理解RecSys研究问题的影响 第三部分 从评估角度对RecSys的批评 (10分钟) – 反直觉的观察 – 评估RecSys时的常见陷阱 更实际的评估 (10分钟) – 公平比较的意义 – 全球时间线的观察 网站https://personal.ntu.edu.sg/axsun/recsyseva.html








成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日