来自 《控制与决策》**


本文引用信息罗俊仁, 张万鹏, 苏炯铭, 等. 计算机博弈中序贯不完美信息博弈求解研究进展[J]. 控制与决策, DOI: 10.13195/j.kzyjc.2022.0698.********
计算机博弈中序贯不完美信息博弈求解研究进展罗俊仁, 张万鹏, 苏炯铭, 魏婷婷, 陈璟
** 研究背景**
01
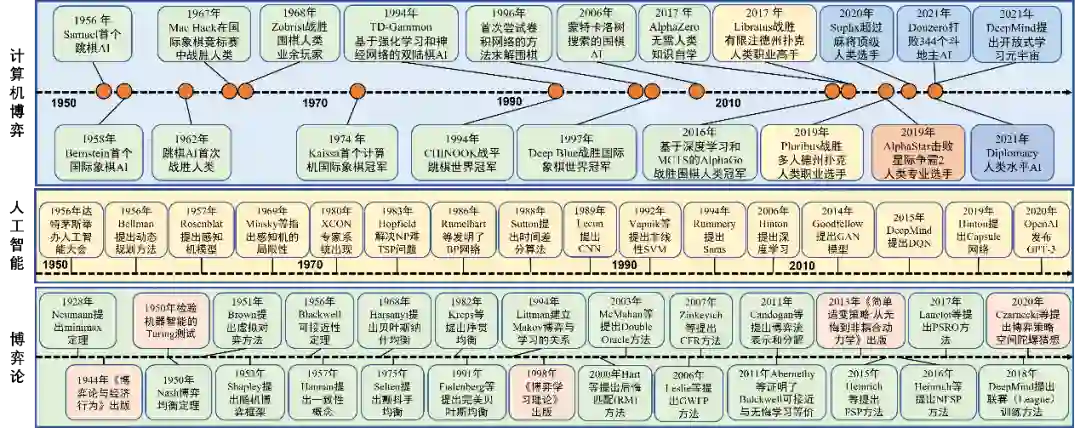
计算机博弈(Computer Games)也称机器博弈,英语直译为计算机游戏,覆盖类型十分广泛。传统的计算机博弈主要包括完美信息博弈(如跳棋、国际象棋、围棋等)和不完美信息博弈(如德州扑克、桥牌等)。早前,研究人员将国际象棋被视为“人工智能的果蝇(Drosophila)”,将扑克作为人工智能领域的“测试平台(Testbed)”。近年来,一些更加复杂的计算机博弈已然成为人工智能的新果蝇和通用测试基准,特别2019年以来,以Alphastar(星际争霸II AI)、Pluribus(德州扑克AI)等为代表的人工智能程序在多类典型人机对抗比赛中战胜人类职业高手,人工智能技术在不完美信息博弈领域取得了显著突破。当前以算法博弈论、深度强化学习和在线凸优化为基础的智能博弈对抗技术的发展,已经完全能够解决围棋等两人零和完全信息博弈,而星际争霸与德州扑克等不完美信息博弈所面临的难题正牵引着人工智能领域的前沿研究。不完美信息博弈常被用于描述多方序贯策略交互过程。博弈对抗过程中,局中人无法获得全部或准确的信息,博弈状态与下步动作通常是不可知的,掌握的信息往往也是不对称和不完美的。相关技术不仅可应用于量化投资、拍卖机制设计等社会经济生产领域,而且可广泛应用于冲突分析、国土安全防卫和智能指控等国防军事应用领域。特别是美国国防部高级研究计划局(DARPA)先后启动了“打破游戏规则”(Gamebreaker)人工智能探索项目,旨在开发开放世界视频游戏的国防战争模拟游戏的人工智能程序,用于作战人员的实战训练;“面向复杂军事决策的非完美信息博弈序贯交互”(SI3-CMD)项目,旨在探索自动化地利用呈指数增长的数据信息,将复杂系统的建模与推理相结合,从而辅助国防部快速认识、理解甚至是预测复杂国际和军事环境中的重要事件。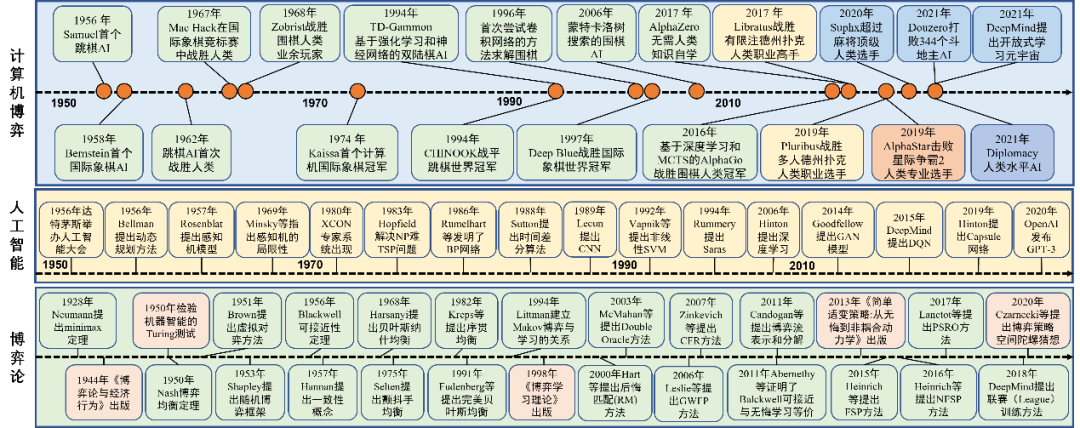
** 研究框架****
**
0****2
通过回顾标志性突破及新评估基准,基于梳理的典型研究范式,提出序贯不完美信息博弈求解研究框架。

图2 序贯不完美信息博弈求解研究框架****2.1博弈模型构建
一个博弈模型通常包含五要素:局中人(智能体)也称博弈方,即博弈中独自参与决策并承担结果的决策者;行动,即局中人在某个决策点的决策变量;信息,即局中人掌握的博弈知识,包括博弈环境、局中人的理性程度、行动和策略等;策略,即局中人相继决策的行动组织;收益,即根据特定的局中人策略组合(Strategy Profile)得出博弈结果后各局中人所获得的收益或支付。2.2子博弈与元博弈
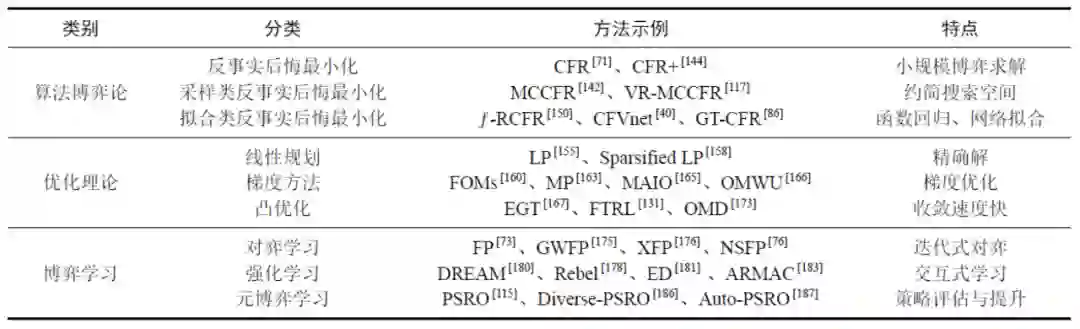
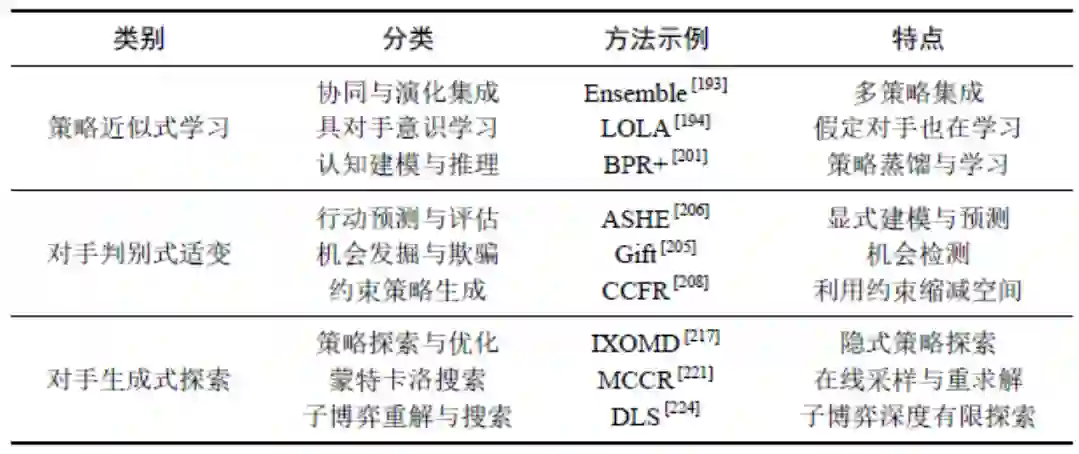
完美信息博弈的子博弈(Subgame)是一棵子树,对于不完美信息博弈,子博弈的概念是建立在增强的信息集基础上的。 元博弈(Meta Game)即博弈的博弈,是研究经验博弈理论分析(Empirical Game Theoretic Analysis,EGTA)的模型基础,可用于辅助分析博弈策略的空间形态。2.3离线策略求解当前关于序贯非完美信息博弈离线策略求解的研究主要可分为“算法博弈论、优化理论和博弈学习”共三大类。表1 离线策略求解方法分类及示例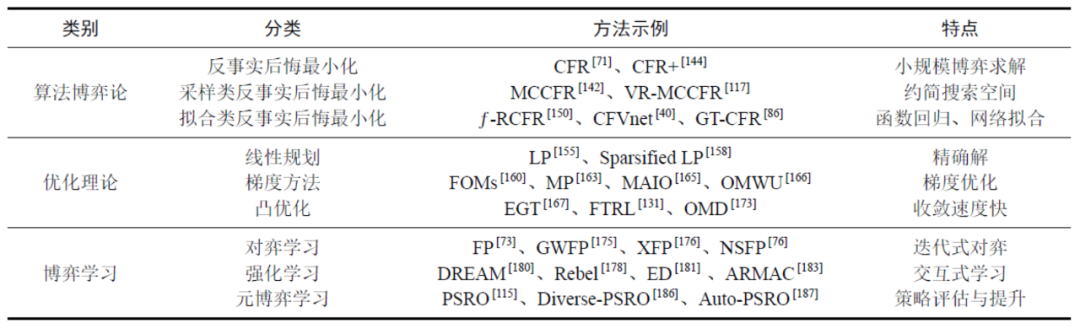
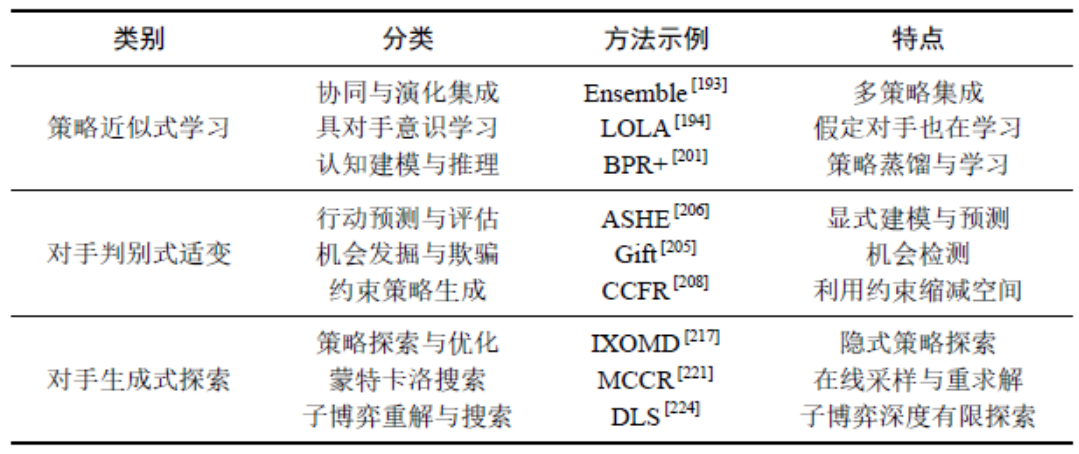
** 复杂性挑战与前沿展望**
03
3.1复杂性挑战
从国际象棋、围棋到德州扑克、星际争霸等,理论与技术的发展呈现交叉融合,面对“巨复杂、强对抗、高动态与多威胁”的现实应用场景、高度仿真模拟现实世界的新型计算机博弈研究环境(如博弈元宇宙)、多人博弈缺乏理论和原理支撑(如多人德州扑克)等为当前开展”环境认知”、“策略求解”和“智能体(对手)建模”等相关研究提出了新挑战。当前,智能体的能力主要依赖云原生平台、数字孪生环境和协同演化方法生成。环境、对手(机器或人类)及AI智能体是计算机博弈研究的主要对象,三者之间博弈对抗与交互学习是机器智能协同演化生成的重要途径。三者之间共有三对关系:智能体与环境的互生关系,即不同的环境需要不同的智能体策略去适配;智能体与人的共生关系,即人机对抗研究利用智能体打败人类对手,人机融合中研究智能体如何理解人类从而与人协作;智能体与对手之间的孪生关系,即在博弈策略空间中,智能体与对手策略之间的压制关系是孪生共存的。
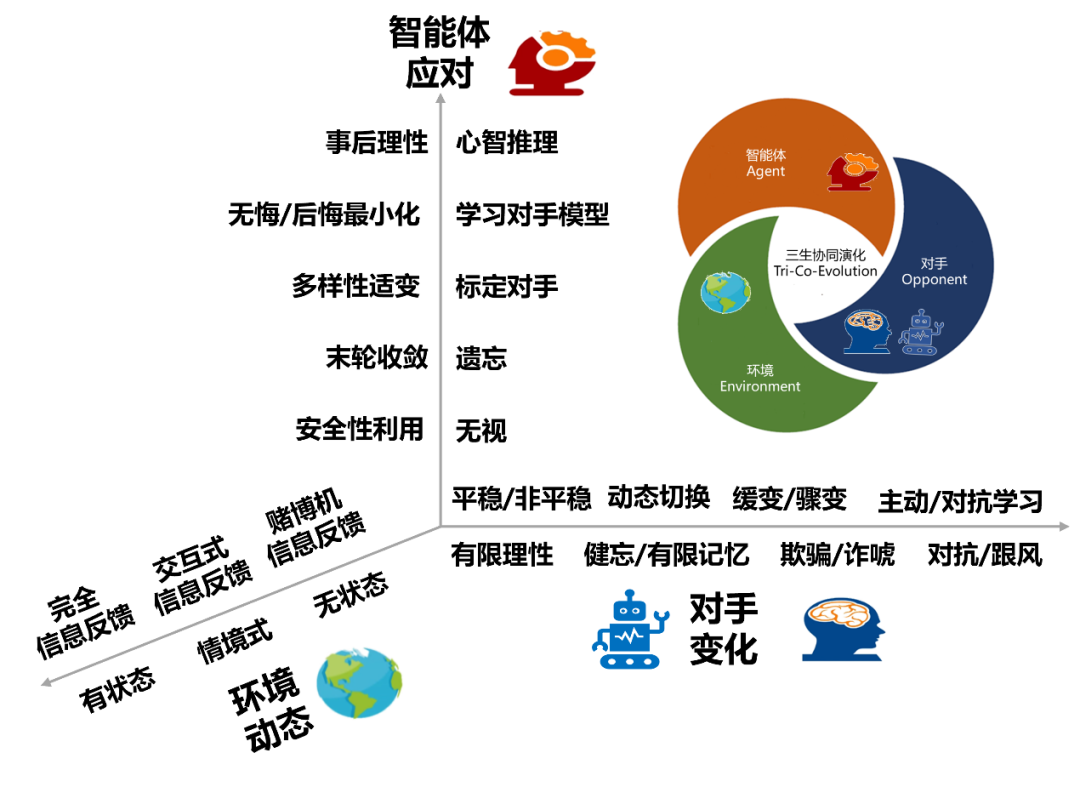
图11“环境-对手-智能体”的多维复杂性描述****3.2前沿展望
博弈动力学与策略空间理论:博弈动力学一直是研究博弈对抗过程中策略收敛至均衡解,早前是演化博弈的主要研究内容,近年来实证博弈理论分析方法为研究博弈动力学与策略空间形态探索提供了有效工具。 多模态对抗博弈及序贯建模:如何为多人德州扑克、桥牌、斗地主、麻将、连续状态空间对抗(如格斗、乒乓球)等构建实用的博弈模型是当前面临的现实挑战。围绕对抗团队博弈的相关模型以及一类更为泛化的一般和博弈模型已然成为当前研究的焦点。 通用策略学习及离线预训练:博弈策略学习一直是学术研究的前沿课题,当前无领域知识的学习、多样性学习、自主课程学习、元学习、在线无悔学习、分布式策略学习框架、融合规划的学习等均已成为当前的研究前沿重点。 对手建模(剥削)与反剥削:对手建模是人工智能领域一个长期存在的研究课题。常用的对手建模方法根据模型表示分为显式建模与隐式建模。非平稳对手如何建模,剥削对手时如何确保己方策略的安全性、削减被对手设计与剥削,构建有限理性模型、防止被欺骗均十分重要。 临机组队与零样本协调:在组队协同方面,智能体需要利用同伴信息来提升己方决策。此外,在行为选择方面,智能体需要根据组队知识与队友行为,围绕最大团队回报的目标确定己方行动。在适应当前队友方面,智能体在交互过程中,可能接收到队友、环境、任务目标等新信息,需采用适变行动来提升协调性。
** 结束语**
04
本文从博弈论的视角梳理了近年来计算机博弈中不完美信息博弈求解相关研究进展。首先结合计算机博弈、人工智能与博弈论发展历史概述了具标志性突破的里程碑事件及新的评估基准,分析归纳了3大研究范式,提出了序贯不完美信息博弈求解研究框架,围绕序贯不完美信息博弈介绍了3种博弈模型构建方法,子博弈与元博弈、以及相关解概念与评估方法。其次,主体部分对当前离线策略求解与在线策略求解各3大类9小类方法进行了全面介绍和分析。最后,分析了当前面临的3类挑战,展望了5个方面的前沿研究重点。当前,算法博弈论、优化理论和博弈学习理论的相互融合发展,为智能博弈对抗策略求解的研究提供了土壤,博弈策略通用求解方法已然成为序贯非完美信息博弈研究的核心,可为当前开展计算机博弈智能AI设计及通用人工智能技术提供新技术、新思路与新途径。
作者介绍
罗俊仁,国防科技大学博士研究生,从事不完美信息博弈、多智能体学习等研究。张万鹏,国防科技大学研究员,博士,从事大数据智能、智能演进等研究。苏炯铭,国防科技大学副研究员,博士,从事智能博弈、可解释性学习等研究。魏婷婷,国防科技大学硕士研究生,从事深度学习、对手建模等研究。 陈璟,国防科技大学教授,博士,从事认知决策博弈、分布式智能等研究。