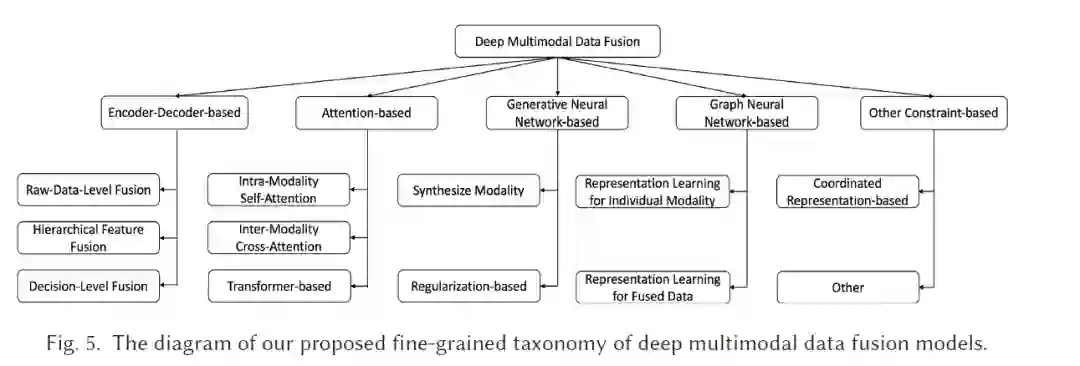
多模态人工智能(Multimodal AI)通常涉及多种类型的数据(例如图像、文本或来自不同传感器的数据)、特征工程(例如特征提取、组合/融合)以及决策过程(例如多数投票)。随着架构变得越来越复杂,多模态神经网络可以将特征提取、特征融合和决策过程整合到一个单一的模型中。这些过程之间的界限日益模糊。基于融合在何处发生的传统多模态数据融合分类(例如早期/后期融合)已经不再适用于现代深度学习时代。因此,基于当前主流技术,我们提出了一种新的细粒度分类,将当前的前沿(SOTA)模型分为五类:编码器-解码器方法、注意力机制方法、图神经网络方法、生成式神经网络方法,以及其他基于约束的方法。现有的大多数多模态数据融合综述仅关注特定任务和特定模态组合,而不同于这些综述的是,本综述涵盖了更广泛的模态组合,包括视觉+语言(例如视频、文本)、视觉+传感器(例如图像、LiDAR)等,以及它们对应的任务(例如视频描述、目标检测)。此外,我们还提供了这些方法之间的比较,以及该领域的挑战和未来发展方向。 https://dl.acm.org/doi/10.1145/3649447
毫无疑问,数据在技术发展中是一个极为重要的催化剂,尤其是在人工智能(AI)领域。过去20年内生成的数据量约占全球所有数据的90%,并且数据增长的速度仍在加快。数据的爆炸式增长为AI的发展提供了前所未有的机会。随着传感器技术的进步,不仅数据的数量和质量得到了提升,数据的多样性也在迅速增长。来自不同传感器的数据为人们提供了同一对象、活动或现象的不同“视角”或“角度”。换句话说,人们可以通过使用不同的传感器来从不同的“维度”或“领域”观察同一对象、活动或现象。这些新的“视角”帮助人们更好地理解世界。例如,在100年前,医学领域由于观测器官方式的局限性,医生很难诊断患者是否患有肺部肿瘤。而在基于X射线技术的首台计算机断层扫描(CT)扫描仪发明后,从机器获取的数据为肺部提供了更丰富的信息,使医生能够仅基于CT图像做出诊断。随着技术的发展,磁共振成像(MRI),一种利用强磁场和射频波的医学成像技术,也被用于检测肿瘤。如今,医生可以访问包括CT、MRI和血液检测数据等多模态数据。这些数据的结合相比单一模态(如仅CT或仅MRI)能够显著提高诊断的准确性。这是因为CT、MRI和血液检测数据之间的互补和冗余信息能够帮助医生构建对观测对象、活动或现象的更全面的理解。AI的发展轨迹也类似。在早期,AI仅专注于使用单一模态解决问题。如今,AI工具已经变得越来越有能力通过多模态来解决实际问题。 什么是多模态?在现实中,当我们体验世界时,我们会看到物体,听到声音,感受到质感,闻到气味,尝到味道[^11]。世界通过不同媒介(如视觉、声音和质感)传达信息。图1显示了一个可视化示例。我们的感知器官如眼睛和耳朵帮助我们捕获这些信息。然后,我们的大脑能够融合来自不同感官的信息,以形成预测或决策。从每个源/媒介获得的信息可以被视为一种模态。当模态的数量超过一个时,我们称之为多模态。然而,与眼睛和耳朵不同,机器主要依赖于传感器,例如RGB摄像头、麦克风或其他类型的传感器,如图2所示。每个传感器都可以将观测到的对象/活动映射到其自身的维度。换句话说,观测到的对象/活动可以投射到每个传感器的维度中。然后,机器或机器人可以收集来自每个传感器的数据,并基于这些数据做出预测或决策。在工业中,有许多应用利用了多模态。例如,自2020年代以来,自动驾驶汽车成为热门话题,是一个典型的依赖多模态的应用。这样的系统需要来自不同传感器的多种数据,如LiDAR传感器、雷达传感器、摄像头和GPS。模型将融合这些数据以进行实时预测。在医学领域,越来越多的应用依赖于医学成像与电子健康记录的融合,使模型能够在临床背景下分析成像结果,如CT和MRI的融合。 为什么我们需要多模态?一般而言,多模态数据指的是从不同传感器收集的数据,例如癌症诊断中的CT图像、MRI图像和血液检测数据,自动驾驶系统中的RGB数据和LiDAR数据,Kinect中的RGB数据和红外数据用于骨骼检测[^28]。对于同一个观察对象或活动,不同模态的数据可以有不同的表达方式和视角。尽管这些数据的特性可能独立且不同,它们在语义上往往重叠。这种现象称为信息冗余。此外,不同模态的信息可以具有互补性。人类可以无意识地融合多模态数据,获取知识并做出预测。从多模态中提取的互补和冗余信息可以帮助人类形成对世界的全面理解。如图3所示的示例中,当一个孩子在打鼓时,即使我们看不到鼓,仍然能够通过声音识别出正在敲击的鼓。在这个过程中,我们无意识地融合了视觉和听觉数据,并提取了它们的互补信息,以做出正确的预测。如果只有一种模态可用,例如鼓对象不在视线范围内的视觉模态,我们只能看出一个孩子正在挥动两根鼓棒。仅有声音时,我们只能判断出有鼓被敲击,而无法知道是谁在敲鼓。因此,基于单一模态的独立解释仅呈现观察活动的部分信息,而基于多模态的解释可以传达更完整的“全貌”,比单模态模型更稳健和可靠。例如,自动驾驶汽车包含多种传感器,如RGB摄像头和LiDAR传感器,在能见度接近零的极端天气条件下(如浓雾或暴雨)需要检测路上的物体。多模态模型在这种情况下仍然能够检测到物体,而仅依赖视觉的模型则可能无法做到。然而,机器要理解并利用多模态数据的互补特性来提高预测/分类准确性仍然是非常困难的。

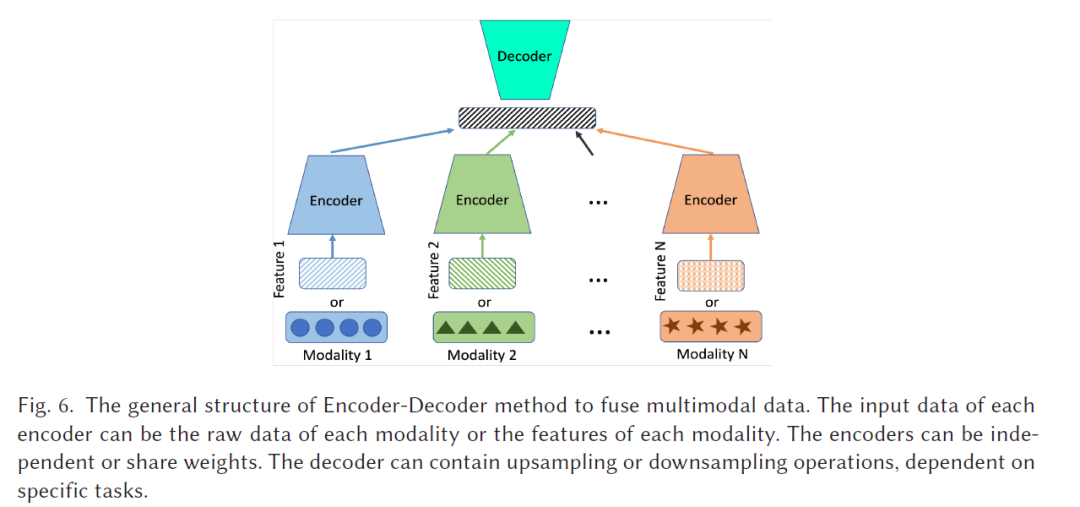
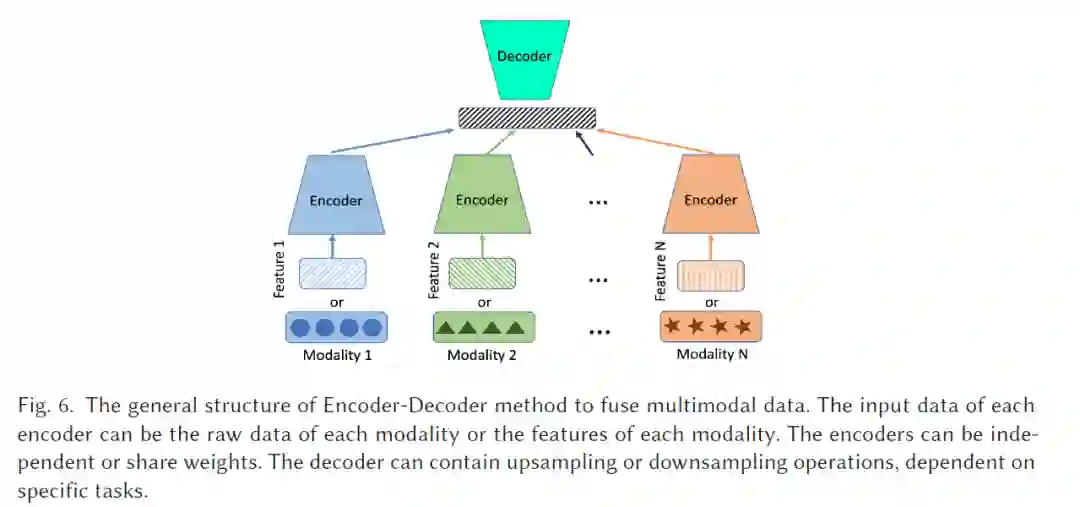
如何融合多模态数据?
20世纪90年代,随着传统机器学习(ML,人工智能的一个子类)的蓬勃发展,基于ML的多模态问题解决模型也逐渐兴起。机器从多模态数据中提取知识并进行决策变得越来越普遍。然而,当时的大多数研究集中在特征工程上,例如如何为每种模态获得更好的表示。那时,提出了许多模态特定的手工设计的特征提取器,这些提取器高度依赖于特定任务和对应数据的先验知识。由于这些特征提取器独立工作,难以捕捉到多模态数据的互补性和冗余性。因此,在特征传递给ML模型之前,这种特征工程过程不可避免地会导致信息的丢失,从而对传统ML模型的性能产生负面影响。尽管传统的ML模型能够分析多模态信息,但实现AI的最终目标(即模拟人类甚至超越人类表现)还有很长的路要走。因此,如何以一种能够自动学习互补性和冗余信息并最大限度减少人工干预的方式融合数据,仍然是传统ML领域的一个难题。

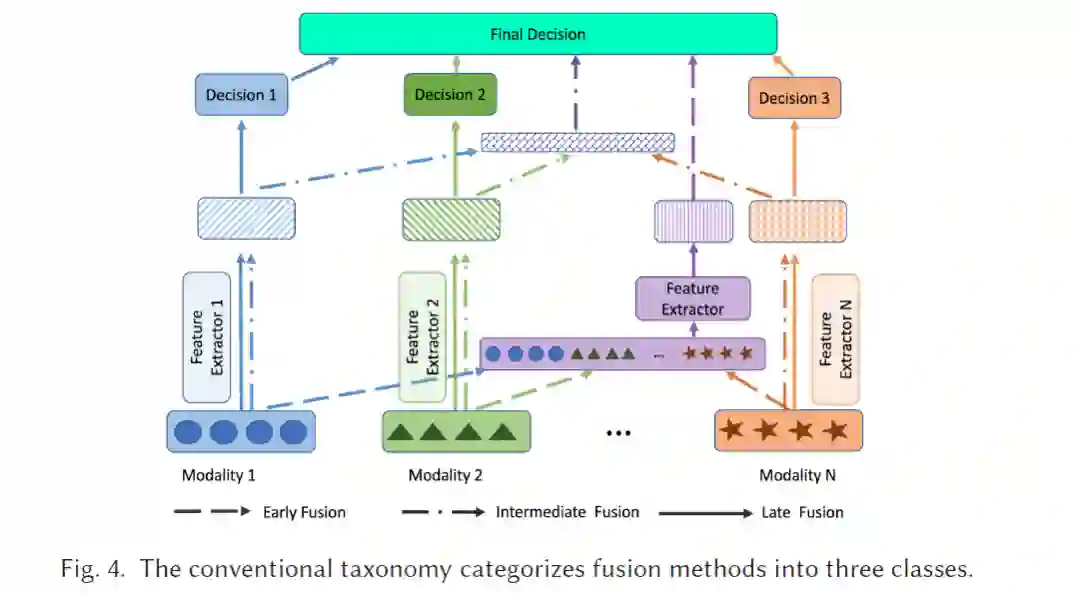
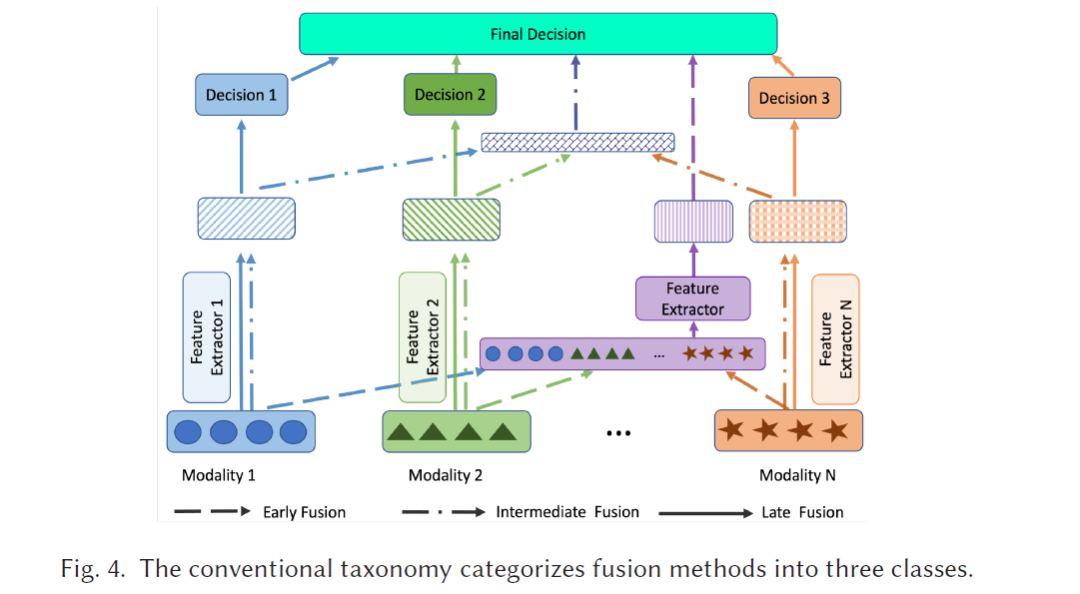
自2010年以来,多模态数据融合全面进入了深度学习阶段。基于深度学习的多模态数据融合方法在各类应用中展现出卓越的成果。对于基于视频-音频的多模态数据融合,文献[35, 37, 51, 163]通过深度学习技术(如卷积神经网络、长短期记忆网络(LSTM)、注意力机制等)解决情感识别问题。此外,在视频-文本多模态数据融合方面,文献[41, 56, 68, 107, 123, 124, 195]利用Transformer、BERT、注意力机制、对抗学习及其组合来解决文本到视频的检索任务。其他多模态任务还有许多,例如视觉问答(VQA)(文本-图像:[154, 220],文本-视频:[82, 223])、RGB-深度对象分割[31, 39]、医学数据分析[181, 185]和图像描述生成[216, 237]。相比传统的ML方法,如果训练数据量足够大,基于深度神经网络(DNN)的方法在表示学习和模态融合方面表现出色。此外,DNN能够自动执行特征工程,这意味着可以从数据中自动学习分层表示,而无需手工设计或手工制作模态特定的特征。传统上,多模态数据融合的方法依据传统融合分类法分为四类,如图4所示,包括早期融合、中期融合、后期融合和混合融合:(1) 早期融合:来自每个模态的原始数据或预处理数据在送入模型之前融合;(2) 中期融合:从不同模态提取的特征融合后送入模型进行决策;(3) 后期融合(也称为“决策融合”):将从每个模态获得的独立决策融合成最终预测,例如多数投票或加权平均,或在独立决策之上引入一个元ML模型;(4) 混合融合:结合早期、中期和后期融合。随着可用的多模态数据量的大幅增加,对更先进的融合方法(与手工挑选的融合方式相对)的需求也空前增长。然而,这种传统的融合分类法仅能为多模态数据融合提供基本指导。为了从多模态数据中提取更丰富的表示,DNN的架构变得越来越复杂,不再单独、独立地从每种模态中提取特征。相反,表示学习、模态融合和决策过程在大多数情况下是交织在一起的。因此,不再需要在网络的哪个部分具体指定多模态数据融合的发生位置。多模态数据的融合方式已从传统的显式方式(如早期融合、中期融合、后期融合)转变为更隐式的方式。为了迫使DNN学习如何提取多模态数据的互补性和冗余性,研究人员在DNN上设计了各种约束,包括特定的网络架构设计和损失函数的正则化等。因此,深度学习的发展显著重塑了多模态数据融合的格局,揭示了传统融合方法分类的不充分性。深度学习架构的固有复杂性往往将表示学习、模态融合和决策过程交织在一起,打破了过去的简化分类。此外,以注意力机制为代表的从显式到更隐式的融合方式挑战了传统融合策略的静态特性。图神经网络(GNN)和生成神经网络(GenNN)等技术引入了处理和融合数据的新方法,这些方法并不符合早期到后期融合的框架。此外,深度模型的动态和自适应融合能力,以及大规模数据带来的挑战,要求比传统类别更为复杂的融合方法。鉴于这些复杂性和快速演变,迫切需要引入一种更深入的分类法,以捕捉当代融合方法的细微差别。 关于多模态数据融合,目前科学界有几篇最新的综述。Gao等[46]提供了一篇关于多模态神经网络和前沿架构的综述,但该综述仅关注于一个狭窄的研究领域:用于RGB-深度图像的对象识别任务。此外,该综述仅限于卷积神经网络。Zhang等[235]提出了一篇关于深度多模态融合的综述,作者使用传统分类法对模型进行分类:早期融合、后期融合和混合融合。此外,该综述仅关注于图像分割任务。Abdu等[2]提供了一篇关于使用深度学习方法进行多模态情感分析的文献综述,将深度学习方法分为三类:早期融合、后期融合和基于时间的融合。然而,和上述综述类似,这篇综述也仅聚焦于情感分析。Gao等[45]提供了一篇关于多模态数据融合的综述,介绍了深度学习的基本概念及多模态深度模型的几种架构,包括基于堆叠自编码器的方法、基于循环神经网络的方法、基于卷积神经网络的方法等。然而,该综述未涵盖前沿的大型预训练模型和基于GNN的方法,例如BERT模型。Meng等[121]提出了一篇关于ML用于数据融合的综述,重点介绍了传统ML技术而非深度学习技术。此外,作者将方法分为信号级融合、特征级融合和决策级融合三类,这种分类方式与传统的早期融合、中期融合和后期融合分类相似,对社区来说并不新鲜。还有其他几篇综述[4, 128, 227]在多模态领域,但大多数都聚焦于特定的模态组合,例如RGB-深度图像。
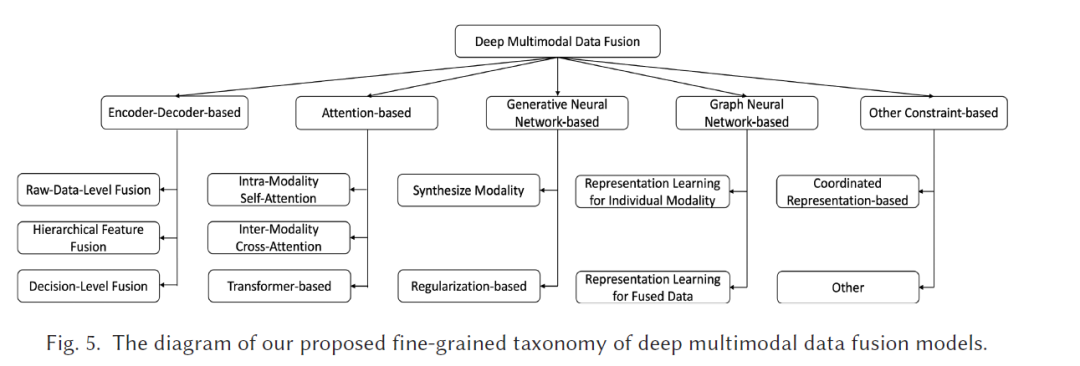
因此,本文对深度多模态数据融合进行了全面的综述和分类。本综述的贡献主要有以下三点:
- 我们提出了一种新的细粒度深度多模态数据融合模型分类方法,不同于现有综述按照传统分类法(如早期、中期、后期和混合融合)进行的分类。在本综述中,我们探讨了最新进展,并将最先进的融合方法分为五类:编码器-解码器方法、注意力机制方法、GNN方法、GenNN方法以及其他基于约束的方法,如图5所示。
- 我们对包括各种模态在内的深度多模态数据融合进行了全面的回顾,如视觉+语言、视觉+其他传感器等。与现有综述[2, 4, 45, 46, 121, 128, 227, 235, 243]通常仅关注单一任务(如多模态对象识别)及两种特定模态组合(如RGB+深度数据)不同,本综述范围更广,涵盖了多种模态及其对应任务,包括多模态对象分割、多模态情感分析、视觉问答(VQA)和视频描述生成等。
- 我们探讨了深度多模态数据融合的新趋势,并对最先进的模型进行了比较。一些过时的方法,如深度信念网络,被排除在本综述之外。然而,本文纳入了大型预训练模型,这些模型是深度学习的新兴之星,例如基于Transformer的预训练模型。
本文的其余部分组织如下:第二部分介绍基于编码器-解码器的融合方法,其中将方法分为三个子类。第三部分展示多模态数据融合中使用的最先进注意力机制,并在本节介绍大型预训练模型。第四部分介绍基于GNN的方法。第五部分介绍基于GenNN的方法,并展示了GenNN在多模态任务中的两个主要作用。第六部分展示在最先进的深度多模态模型中采用的其他约束方法,例如基于张量的融合。第七部分将介绍多模态数据融合中的主要任务、应用和数据集。第八部分和第九部分讨论了多模态数据融合的未来方向和本综述的结论。