导读 Akulaku 作为一个海外互联网金融平台,运用大模型优化金融风控、客服及电商推荐等场景,通过集成图像(如 KYC 人脸识别)、文本(如智能客服)与设备数据,增强风控系统效能与用户体验。大模型的引入旨在提升效率,通过优化小模型构建与工作流程自动化,减轻业务人员负担。智能体在金融领域的应用包括欺诈调查与数据分析助手,预示着通过大模型辅助构建类 AGI 系统的可能性,能够进一步提升金融风控的效率与效果,在金融领域拥有广泛的应用前景。本文将分享 Akulaku 在金融风控领域的大模型落地实践。 ****今天的介绍会围绕下面五点展开:****1. 公司业务背景2. 大模型落地整体思路3. 大模型优化案例4. 总结与展望 5. 引用分享嘉宾|黄泓 Akulaku AI算法总监编辑整理|潘志明内容校对|李瑶 出品社区|DataFun
01
公司业务背景介绍首先介绍一下公司的业务背景。Akulaku 是一家主打海外市场的互联网金融服务提供者,服务内容包括网上购物和分期付款、现金贷、保险等等,主要应用于金融风控、电商智能客服以及电商推荐等场景中。无论是在用户审核、信用评估,还是在反欺诈识别等环节,单纯手工操作和业务规则判断无法高效准确地处理大量的用户请求,拦截各种黑产攻击。所以我们的总体目标是构建基于各种技术手段的敏捷高效的智能风控系统,以应对各种威胁,不断提升用户体验。具体应用场景包括授信申请、登录校验、下单校验、催收、客服回访等多个业务环节,其中会涉及到不同模态的数据: * 图像:最典型的应用场景是 KYC 人脸核身。一般金融机构都会有 KYC 的审核来确定,第一你是真人,第二你是你自己。
文本:典型应用场景是智能客服,包括文本客服、语音客服。 * 语音:典型场景包括智能客服,以及质检和电话催收。 * 设备:设备数据是风控的一个重要参考维度,包括设备环境的校验,唯一 ID 的构建等等。 02
大模型落地整体思路
![]() 在大模型兴起以前,我们就在持续为业务部门提供各种 AI 模型,涵盖之前介绍的各种模态数据。在大模型兴起之后,我们希望进一步提高智能风控系统在各个业务环节以及各种数据形态上的效能。总的愿景就是要构建一个智能体系统。大模型使我们离 AGI 通用人工智能又更进了一步,而我们也试图去构建一个金融领域的 AGI。一个智能体系统主要包含以下三个重要模块[1]:**(1)规划模块(Planning)**包括各种业务决策的知识,通常固定在智能体的链的定义中,也就是LangChain里面的一个chain,系统整体上是各种智能体的结合。(2)存储模块(Memory)业务系统中的各种数据和元数据,可能存储在一种或者多种外部数据库中。(3)工具模块(Tools)各种专有领域的业务模型和业务逻辑,包括各种图像模型、NLP 模型、风控的判别模型,以及风控系统的一些具体的业务逻辑等等。
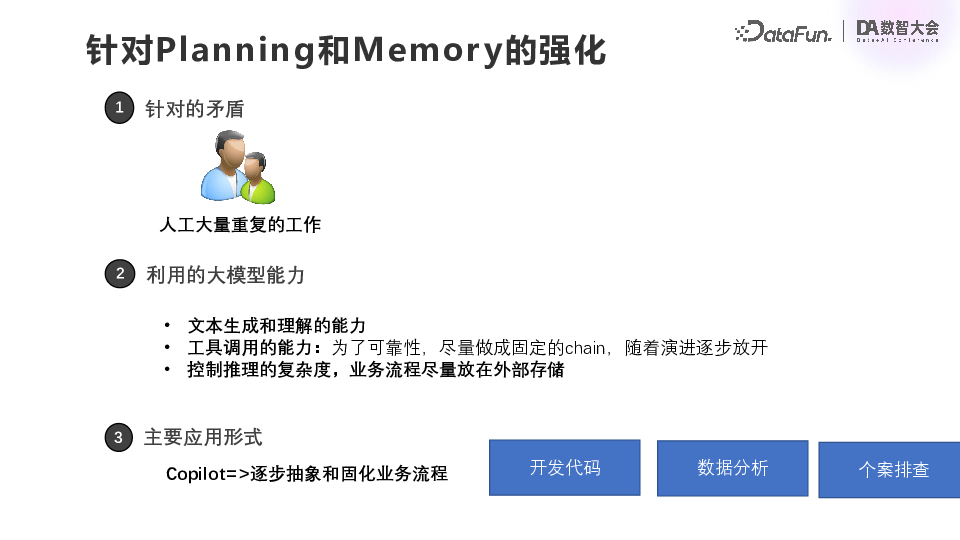
在大模型兴起以前,我们就在持续为业务部门提供各种 AI 模型,涵盖之前介绍的各种模态数据。在大模型兴起之后,我们希望进一步提高智能风控系统在各个业务环节以及各种数据形态上的效能。总的愿景就是要构建一个智能体系统。大模型使我们离 AGI 通用人工智能又更进了一步,而我们也试图去构建一个金融领域的 AGI。一个智能体系统主要包含以下三个重要模块[1]:**(1)规划模块(Planning)**包括各种业务决策的知识,通常固定在智能体的链的定义中,也就是LangChain里面的一个chain,系统整体上是各种智能体的结合。(2)存储模块(Memory)业务系统中的各种数据和元数据,可能存储在一种或者多种外部数据库中。(3)工具模块(Tools)各种专有领域的业务模型和业务逻辑,包括各种图像模型、NLP 模型、风控的判别模型,以及风控系统的一些具体的业务逻辑等等。 ![]() 智能体系统与我们的现有系统,包括风控系统、模型系统并不是割裂开的一个新生成的体系,而是从原有体系演进而来的。具体落地分为两大类:(1)针对 Tools 的强化第一类是针对 tools 的强化。比如针对 KYC 模块里面的某个具体的图像模型,优化其效能。可以利用大模型理解指令的能力,和它承载的对应语言的通识和泛化能力,来做数据增强和引导,来增强特定环节的专有模型。这就是针对 tools 的强化。(2)针对 Planning 和 Memory 的强化第二个角度是针对 planning 和 memory 的强化。第二个方向的对象是人,我们希望从业务同学现有的繁琐的重复性工作中涉及的业务知识和决策抽取出来,固定在一个智能体的链中,构建相应的智能体角色。在智能体以及大模型的概念提出之后,我们在做需求的时候,虽然具体落地仍是逐一实现,但是在落地之前,我们会思考这些需求之间的相互关系,并不是以单个场景或者是单个模型的角度去思考,而是以一个角色的角度去思考。比如现在要做的是数据分析师角色的优化,或者是欺诈调查员角色的优化。03
智能体系统与我们的现有系统,包括风控系统、模型系统并不是割裂开的一个新生成的体系,而是从原有体系演进而来的。具体落地分为两大类:(1)针对 Tools 的强化第一类是针对 tools 的强化。比如针对 KYC 模块里面的某个具体的图像模型,优化其效能。可以利用大模型理解指令的能力,和它承载的对应语言的通识和泛化能力,来做数据增强和引导,来增强特定环节的专有模型。这就是针对 tools 的强化。(2)针对 Planning 和 Memory 的强化第二个角度是针对 planning 和 memory 的强化。第二个方向的对象是人,我们希望从业务同学现有的繁琐的重复性工作中涉及的业务知识和决策抽取出来,固定在一个智能体的链中,构建相应的智能体角色。在智能体以及大模型的概念提出之后,我们在做需求的时候,虽然具体落地仍是逐一实现,但是在落地之前,我们会思考这些需求之间的相互关系,并不是以单个场景或者是单个模型的角度去思考,而是以一个角色的角度去思考。比如现在要做的是数据分析师角色的优化,或者是欺诈调查员角色的优化。03
大模型优化案例****下面将通过一些具体案例来说明我们是如何实现大模型落地的。
1. 针对 Tools 的强化(1)NLP 模型优化
![]()
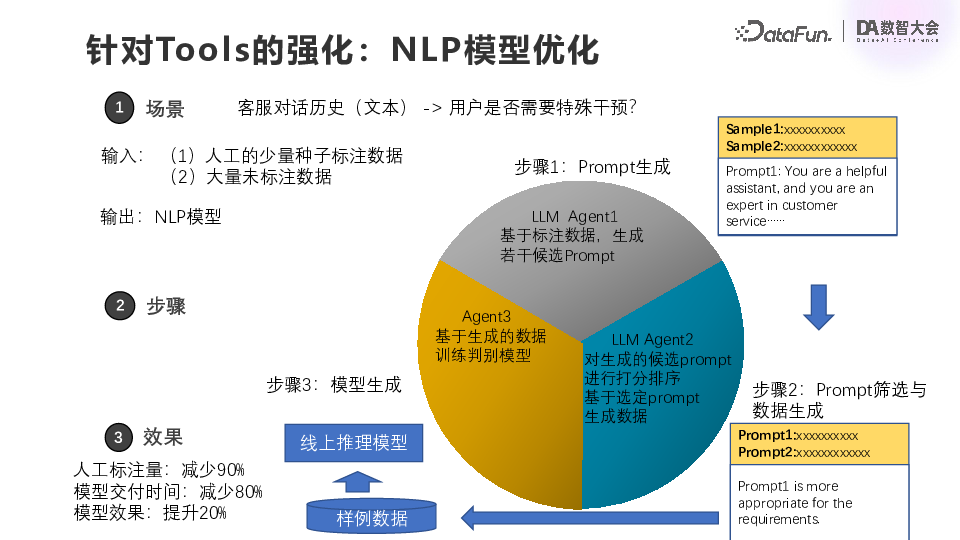
首先,针对 tools 的强化,第一个案例是来自一个数字金融系统中的场景,根据客服对话历史判别用户是否需要特殊干预。按照以前的做法,面对这个问题,模型团队首先需要积累数据或者标注数据,所以整个交付流程和迭代流程会非常冗长和低效。引入大模型之后,不再需要十万级的样本,只需要少量人工标注的数据,大概几百到 1000 左右就可以了。首先通过一个大模型 Agent 基于标注的数据生成候选提示词,就是我希望这个样本数据应该是怎么样的。然后第二个 Agent 会对前面提到的这个 Agent 进行排序打分,选出一个比较好的 prompt 交给大模型去生成数据。大模型的特点就是它能泛化,但是比较慢,而慢在这里不是太大的问题,因为它需要的训练数据量只有十万条级别,也不是特别多,基于这样的样例数据就可以做一个线上的推理模型。可能有的同学问为什么不直接把这个大模型上线?主要的原因是现在这个系统每天的吞吐量要求很高,如果要让大模型实现非常快速的响应,就难以避免延时。因此比较好的一个办法就是直接让它去生成数据,蒸馏数据,然后生成小模型来迭代业务系统相应的模块。最终这个需求的人工标注量大幅减少,减少了 90%,模型交付时间显著缩短,而模型效果比原来提高 20%。最令业务方最满意的是标注量和交付时间的减少,这意味着整个系统更加敏捷,应对变化的效率更高。(2)图像反欺诈模型优化
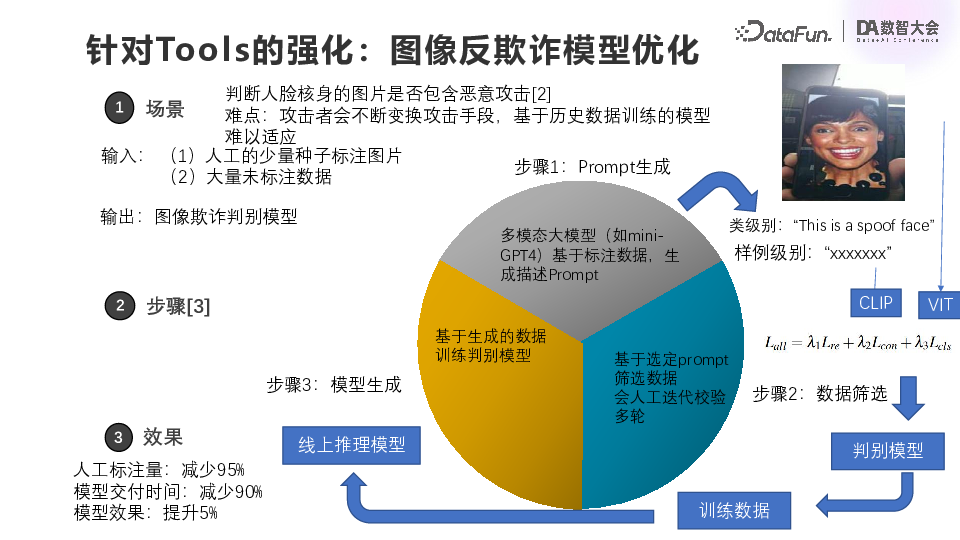
![]() 第二个案例更为典型,即图像反欺诈模型优化,针对的场景是 KYC 人脸核身。大家都用过刷脸,背后其实不是一个单一的模型,而是由很多个模型联合实现的。其中会判别是否存在欺诈行为,比如拍屏或者用高清面具伪装成某一个特定的人。这看起来是一个简单的图像分类,而其中有两个问题。第一个问题是领域适配。用户的人脸属于敏感数据,我们实际不能接触到用户的人脸数据,只能通过公开数据去训练适配,比如上图中右上角展示的图片是来自公开数据的一张图。但是用大量的公开数据去训练的模型,可能跟实际的业务场景相去甚远,比如光照条件、人脸的肤色,可能跟实际的用户差比较远。因此模型的泛化会是很大的问题第二个问题是欺诈者会不断变换攻击手段,所以模型必须要敏捷且泛化。而以往的训练流程缺乏标注人手,难以提高模型性能。有了大模型之后,我们通过人工少量的标注的图片和提示词。比如让大模型描述图片中的脸,模型就会返回这张脸在一个手机中而手机是由人拿着,这与业务人员的理解是非常接近的。即使我们使用公开的数据进行训练,多模态的大模型通过图像模态和文本模态的对齐,也能抽取出实际泛化的语义特征,确保模型在真实场景的泛化性能。具体实现方法是通过 CLIP 去抽取大模型生成的描述的文本特征,然后用视觉的 Transformer 可以抽取图像本身的特征,然后可以专门去做对齐。这里是三个代价函数的加总,中间是 CLIP 的对比学习的代价函数,实际上就是文本特征跟图像特征做对比学习;头尾就是视觉 Transformer 的损失函数,一个是 Reconstruction Loss,另一个是分类的 Loss,三者加权。当你直接去看 attention 的 mask 的时候,就会发现经过这样的对齐,它相应的图的注意力的 mask 会聚焦到人对这个图的理解上。即使肤色改变或光照条件改变,模型也还是会有一定的泛化能力。后面是一个判别模型,这个判别模型还是要以 mini GPT 4 的描述作为其中一个输入,所以会有点慢,但是已经能够满足需求,我们就用它来理解和标记训练数据,然后就可以得到线上的一个更快的推理模型。这一方案除了效果和泛化能力出色之外,更特别的一点就是它与人本身的思维通过自然语言这一载体自然对接起来了,即使我们的训练数据和真实场景看起来比较远,也能高效抽取出真正泛化的特征,这使得整个模型的交付效率大幅提升[2][3]。(3)总结
第二个案例更为典型,即图像反欺诈模型优化,针对的场景是 KYC 人脸核身。大家都用过刷脸,背后其实不是一个单一的模型,而是由很多个模型联合实现的。其中会判别是否存在欺诈行为,比如拍屏或者用高清面具伪装成某一个特定的人。这看起来是一个简单的图像分类,而其中有两个问题。第一个问题是领域适配。用户的人脸属于敏感数据,我们实际不能接触到用户的人脸数据,只能通过公开数据去训练适配,比如上图中右上角展示的图片是来自公开数据的一张图。但是用大量的公开数据去训练的模型,可能跟实际的业务场景相去甚远,比如光照条件、人脸的肤色,可能跟实际的用户差比较远。因此模型的泛化会是很大的问题第二个问题是欺诈者会不断变换攻击手段,所以模型必须要敏捷且泛化。而以往的训练流程缺乏标注人手,难以提高模型性能。有了大模型之后,我们通过人工少量的标注的图片和提示词。比如让大模型描述图片中的脸,模型就会返回这张脸在一个手机中而手机是由人拿着,这与业务人员的理解是非常接近的。即使我们使用公开的数据进行训练,多模态的大模型通过图像模态和文本模态的对齐,也能抽取出实际泛化的语义特征,确保模型在真实场景的泛化性能。具体实现方法是通过 CLIP 去抽取大模型生成的描述的文本特征,然后用视觉的 Transformer 可以抽取图像本身的特征,然后可以专门去做对齐。这里是三个代价函数的加总,中间是 CLIP 的对比学习的代价函数,实际上就是文本特征跟图像特征做对比学习;头尾就是视觉 Transformer 的损失函数,一个是 Reconstruction Loss,另一个是分类的 Loss,三者加权。当你直接去看 attention 的 mask 的时候,就会发现经过这样的对齐,它相应的图的注意力的 mask 会聚焦到人对这个图的理解上。即使肤色改变或光照条件改变,模型也还是会有一定的泛化能力。后面是一个判别模型,这个判别模型还是要以 mini GPT 4 的描述作为其中一个输入,所以会有点慢,但是已经能够满足需求,我们就用它来理解和标记训练数据,然后就可以得到线上的一个更快的推理模型。这一方案除了效果和泛化能力出色之外,更特别的一点就是它与人本身的思维通过自然语言这一载体自然对接起来了,即使我们的训练数据和真实场景看起来比较远,也能高效抽取出真正泛化的特征,这使得整个模型的交付效率大幅提升[2][3]。(3)总结
![]() 原始流程中,业务提一个需求,要做 AI 模型,就需要大量的标注工作量,而且往往我们对于这个领域的理解没有办法注入到数据中。但现在基于大模型,图像的特征与语言描述得以对齐,然后通过语言这个载体,就可以与业务方的期望进行对齐。这里利用了大模型承载的通识,用来生成训练数据;还利用了大模型的指令理解能力,领域专家直接将他对这个 case 的理解,通过自然语言来引导大模型来注入领域理解。2. 针对 Planning 和 Memory 的强化**(1)欺诈调查助手**
原始流程中,业务提一个需求,要做 AI 模型,就需要大量的标注工作量,而且往往我们对于这个领域的理解没有办法注入到数据中。但现在基于大模型,图像的特征与语言描述得以对齐,然后通过语言这个载体,就可以与业务方的期望进行对齐。这里利用了大模型承载的通识,用来生成训练数据;还利用了大模型的指令理解能力,领域专家直接将他对这个 case 的理解,通过自然语言来引导大模型来注入领域理解。2. 针对 Planning 和 Memory 的强化**(1)欺诈调查助手**
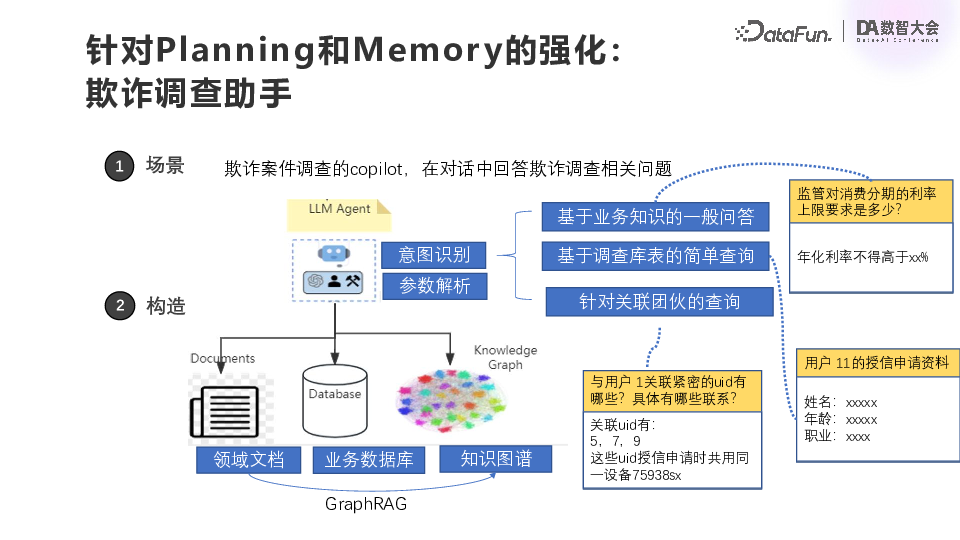
![]() 第二类是针对 Planning 和 Memory 的强化,实际上就是给我们的业务人员减负、提效。第一个场景是反欺诈调查的 copilot,通过与欺诈调查员的对话来解决相关问题。利用 GraphRAG 技术,首先进行意图识别,这里的意图基本上都是固定好的,可枚举的,第一个就是基于业务知识的一般问答,第二个是基于调查库表的简单查询,第三个是基于关联团伙的查询。意图识别完成之后,针对意图来做参数解析,然后进行查询。这里的业务知识一般都是以自由文档的方式存储在 RAG 的向量库里面,业务库表在数仓中。目前公司没有一个特别完备的数据血缘,所以很多数据血缘的信息实际上是放在领域文档里面的。所以第一步可能会做一个简单的图关系的抽取,一般都是一个预置好的 prompt,比如一些表的信息和关联的信息,如果有的话就把它抽出来做一个简单的支撑。以上就是欺诈调查助手场景的实现。(2)数据分析助手****
第二类是针对 Planning 和 Memory 的强化,实际上就是给我们的业务人员减负、提效。第一个场景是反欺诈调查的 copilot,通过与欺诈调查员的对话来解决相关问题。利用 GraphRAG 技术,首先进行意图识别,这里的意图基本上都是固定好的,可枚举的,第一个就是基于业务知识的一般问答,第二个是基于调查库表的简单查询,第三个是基于关联团伙的查询。意图识别完成之后,针对意图来做参数解析,然后进行查询。这里的业务知识一般都是以自由文档的方式存储在 RAG 的向量库里面,业务库表在数仓中。目前公司没有一个特别完备的数据血缘,所以很多数据血缘的信息实际上是放在领域文档里面的。所以第一步可能会做一个简单的图关系的抽取,一般都是一个预置好的 prompt,比如一些表的信息和关联的信息,如果有的话就把它抽出来做一个简单的支撑。以上就是欺诈调查助手场景的实现。(2)数据分析助手****
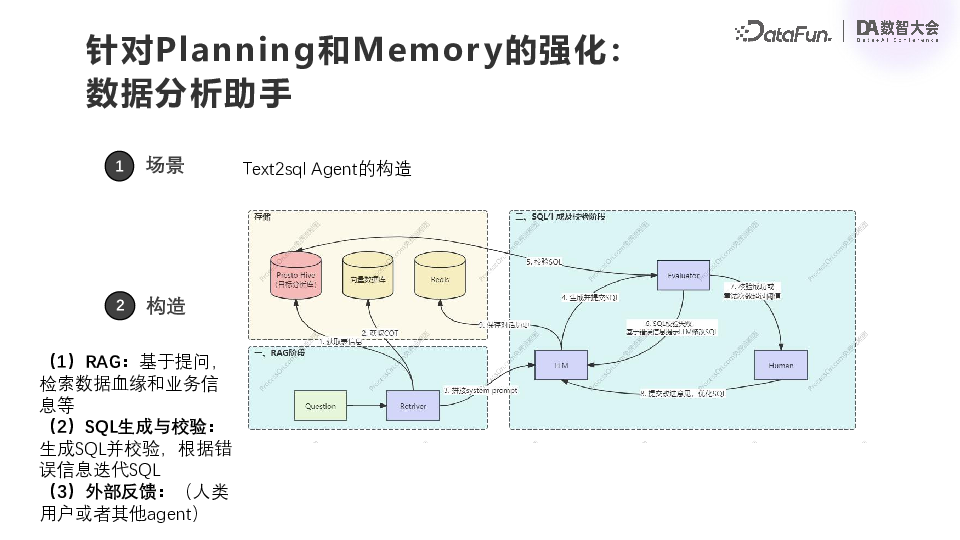
![]() 第二个场景也是一个非常通用的场景,即 ChatBI,是基于 Text2SQL 实现的。当有数据分析需求时,可以直接提问。首先根据用户提问去做拆解,确定需要调用哪些工具。我们目前有两个工具,一个是 Text2SQL,另一个就是基于 Pandas 的一个简单的可视化分析工具。选定工具之后,就依赖工具执行对应的动作,会去调用向量数据库召回文档和领域相关的一些描述文本片。根据每一个 Agent 的返回结果来决定这个问题是否已经解决。
第二个场景也是一个非常通用的场景,即 ChatBI,是基于 Text2SQL 实现的。当有数据分析需求时,可以直接提问。首先根据用户提问去做拆解,确定需要调用哪些工具。我们目前有两个工具,一个是 Text2SQL,另一个就是基于 Pandas 的一个简单的可视化分析工具。选定工具之后,就依赖工具执行对应的动作,会去调用向量数据库召回文档和领域相关的一些描述文本片。根据每一个 Agent 的返回结果来决定这个问题是否已经解决。 ![]() 在这个 Text2SQL 的 Agent 里面,还会有一个与上面类似的小循环。我们的数据分析是基于 Presto。用户会把他自有的文档放到向量数据库里面,Redis 里面存对话历史。首先基于用户提的问题,获取表的元数据信息和它自有的文档里面获取相应的文本片和思维链的一些线索,拼成一个总的 prompt,输入到大模型的 Agent 里面,然后生成 SQL、检验 SQL、执行 SQL、修改 SQL,这样循环几次之后把最终的结果返回。在落地过程中我们发现一个难点,这一做法对新写 SQL 效果还行,但是对于已有的一些比较复杂的 SQL,我们需要把文档整理好,然后做相应的召回,这个 Agent 才能有比较好的效果。****(3)总结
在这个 Text2SQL 的 Agent 里面,还会有一个与上面类似的小循环。我们的数据分析是基于 Presto。用户会把他自有的文档放到向量数据库里面,Redis 里面存对话历史。首先基于用户提的问题,获取表的元数据信息和它自有的文档里面获取相应的文本片和思维链的一些线索,拼成一个总的 prompt,输入到大模型的 Agent 里面,然后生成 SQL、检验 SQL、执行 SQL、修改 SQL,这样循环几次之后把最终的结果返回。在落地过程中我们发现一个难点,这一做法对新写 SQL 效果还行,但是对于已有的一些比较复杂的 SQL,我们需要把文档整理好,然后做相应的召回,这个 Agent 才能有比较好的效果。****(3)总结
![]() 针对 Planning 和 Memory 的强化与前面针对 Tools 的强化不同,它不是对一个具体模型的优化,而是去做一个角色,比如代码开发、数据分析、个案排查或是客服。针对 Planning 和 Memory 的强化以 Copilot 的形式来提供,先构造一个助手,利用大模型文本生成和理解的能力,工具调用的能力,以及已有的文档,尽可能好地构造一些结构化的知识,使大模型的结果尽可能靠近用户预期。这样以 Copilot 的形式来协助相应角色完成开发、分析或调查等工作。最终基于这些 SQL 或是调查中抽象出固定的流程。04
针对 Planning 和 Memory 的强化与前面针对 Tools 的强化不同,它不是对一个具体模型的优化,而是去做一个角色,比如代码开发、数据分析、个案排查或是客服。针对 Planning 和 Memory 的强化以 Copilot 的形式来提供,先构造一个助手,利用大模型文本生成和理解的能力,工具调用的能力,以及已有的文档,尽可能好地构造一些结构化的知识,使大模型的结果尽可能靠近用户预期。这样以 Copilot 的形式来协助相应角色完成开发、分析或调查等工作。最终基于这些 SQL 或是调查中抽象出固定的流程。04
总结与展望
![]() 我们的智能体落地步骤可以总结为: * 第一步,针对具体模型的进行提效,通过大模型的通识和泛化能力,对小模型的构建实现提效。 * 第二步,逐步将业务知识提炼、固化。原来可能是主管对员工,然后员工去找 Copilot,后面在员工和 Copilot 协作的过程中,不断抽象业务和模式,并固定在链路定义中。最终实现主管和主要员工通过操作一个具有决策能力的类 AGI 系统,来完成日常的模型构造、案件调查、个案分析、团伙排查等各种任务。
我们的智能体落地步骤可以总结为: * 第一步,针对具体模型的进行提效,通过大模型的通识和泛化能力,对小模型的构建实现提效。 * 第二步,逐步将业务知识提炼、固化。原来可能是主管对员工,然后员工去找 Copilot,后面在员工和 Copilot 协作的过程中,不断抽象业务和模式,并固定在链路定义中。最终实现主管和主要员工通过操作一个具有决策能力的类 AGI 系统,来完成日常的模型构造、案件调查、个案分析、团伙排查等各种任务。
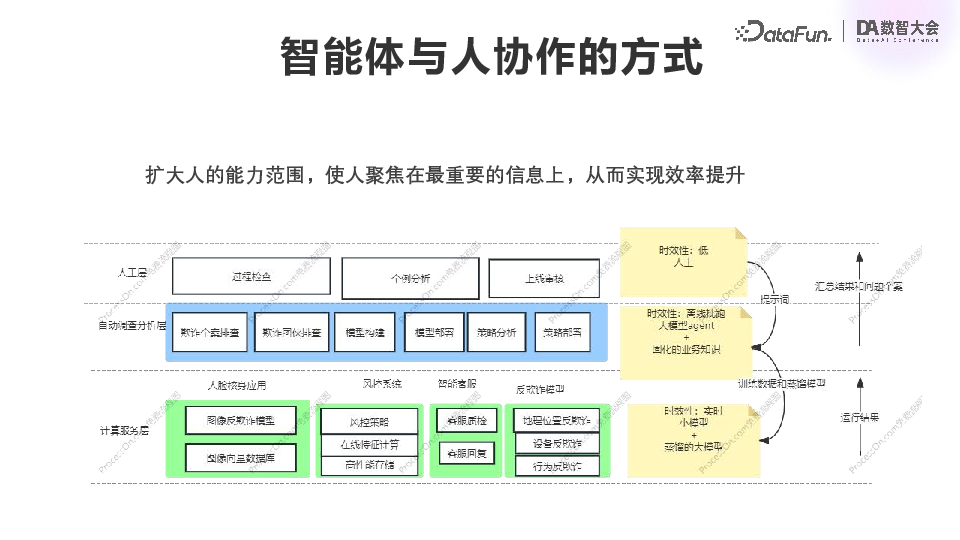
![]() 落地过程中的一个重要问题是,人应该扮演怎样的角色,智能体系统是否会完全取代人工?从我们的经验以及对未来的判断来说,大模型 Agent 并不可以完全替代人,而只是扩大人的能力范围,由大模型来一定程度上替代繁琐的重复工作,而使人更加聚焦于业务情况的核心问题。我们有一个核心的风控和智能系统,包括各种风控、营销、电商和金融系统,都是固定的模型和固定的业务逻辑。中间是各部门对应的欺诈调查、模型构造、策略分析等业务,我们期望通过逐步引入智能体,将这些工作中标准化的部分固化下来,最终由 Agent 去实现。人就可以聚集于整个业务的全局,以及一些重要的个案。业务人员在发现了一些业务中新的现象之后,会去尝试总结成提示词,然后去引导中间的 Agent 去挖掘数据、生成数据,以及做一些对应的分析汇总。通过这个分析汇总生成新的训练数据和蒸馏更加有效的模型,然后部署到我们线上的实时系统中去。过程中会对运行结果进行实时的统计和监控,然后把结果和一些异常的个案汇总到人工层。这就是我们希望实现的智能体系统的结构。以上就是本次分享的内容,谢谢大家。05
落地过程中的一个重要问题是,人应该扮演怎样的角色,智能体系统是否会完全取代人工?从我们的经验以及对未来的判断来说,大模型 Agent 并不可以完全替代人,而只是扩大人的能力范围,由大模型来一定程度上替代繁琐的重复工作,而使人更加聚焦于业务情况的核心问题。我们有一个核心的风控和智能系统,包括各种风控、营销、电商和金融系统,都是固定的模型和固定的业务逻辑。中间是各部门对应的欺诈调查、模型构造、策略分析等业务,我们期望通过逐步引入智能体,将这些工作中标准化的部分固化下来,最终由 Agent 去实现。人就可以聚集于整个业务的全局,以及一些重要的个案。业务人员在发现了一些业务中新的现象之后,会去尝试总结成提示词,然后去引导中间的 Agent 去挖掘数据、生成数据,以及做一些对应的分析汇总。通过这个分析汇总生成新的训练数据和蒸馏更加有效的模型,然后部署到我们线上的实时系统中去。过程中会对运行结果进行实时的统计和监控,然后把结果和一些异常的个案汇总到人工层。这就是我们希望实现的智能体系统的结构。以上就是本次分享的内容,谢谢大家。05
引用[1] Lilian Weng (2023, June 23). LLM Powered Autonomous Agents https://lilianweng.github.io/posts/2023-06-23-agent/[2]Zhang Y, Yin Z F, Li Y, et al. Celeba-spoof: Large-scale face anti-spoofing dataset with rich annotations[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16. Springer International Publishing, 2020: 70-85.[3]Fang, H., Liu, A., Jiang, N., Lu, Q., Zhao, G., & Wan, J. (2024, April). VL-FAS: Domain Generalization via Vision-Language Model For Face Anti-Spoofing. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 4770-4774). IEEE.以上就是本次分享的内容,谢谢大家。![]()
分享嘉宾
INTRODUCTION ![]()
黄泓![]()
Akulaku![]()
AI算法总监![]()
负责 AI 技术在 Akulaku 风控等领域的落地应用,主导集团基于图像,语音,知识图谱,自然语言,设备数据等多模态数据的认知智能系统的搭建和风控能力建设。