

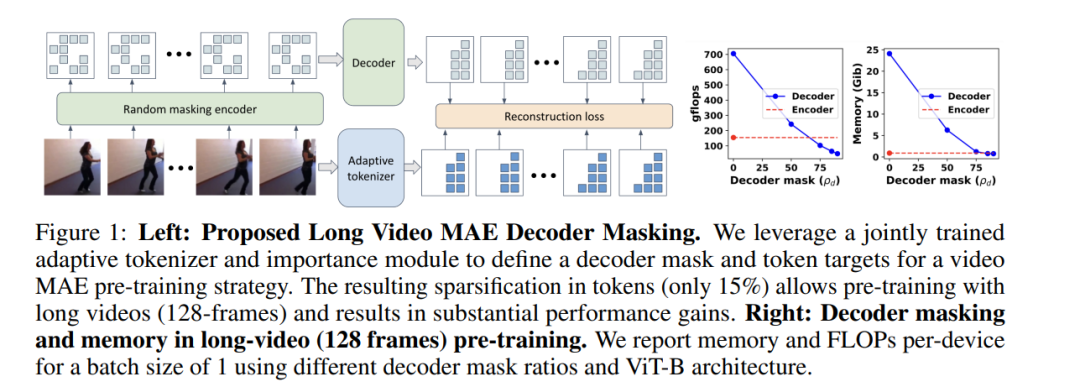
视频理解在最近取得了显著进展,得益于视频基础模型在自监督预训练目标下的强大表现,其中掩蔽自编码器(MAE)成为首选设计。然而,之前的大多数基于MAE预训练的工作主要集中在较短的视频表示(16/32帧),这主要是由于硬件内存和计算能力的限制,随着视频长度的增加,密集的内存密集型自注意力解码过程的计算和内存开销会急剧增加。为了解决这些挑战,一个自然的策略是对解码过程中的令牌进行子采样重构(或解码器掩蔽)。在本研究中,我们提出了一种有效的策略,通过优先考虑令牌来训练更长的视频序列(128帧),并且比典型的随机和均匀掩蔽策略表现更好。我们方法的核心是一种自适应解码器掩蔽策略,它优先考虑最重要的令牌,并使用量化令牌作为重构目标。我们的自适应策略利用了一个强大的基于MAGVIT的标记器,该标记器共同学习令牌及其优先级。我们通过全面的消融实验验证了设计选择,并观察到长视频(128帧)编码器在性能上超过了短视频(32帧)版本。通过我们提出的长视频掩蔽自编码器(LVMAE)策略,我们在Diving48数据集上超越了最先进的技术3.9个百分点,并在EPIC-Kitchens-100动词分类任务上超越了2.5个百分点,同时我们仅依赖一个简单的核心架构和视频预训练(与一些先前的工作不同,后者需要数百万个带标签的视频-文本对或专用编码器)。 https://arxiv.org/abs/2411.13683
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日