
知识库可以有不同的种类。除了像维基百科这样受欢迎的通用知识库,另一端非常有用的种类可能是领域和应用特定的,例如针对单一主题(如俄罗斯-乌克兰战争、电动汽车电池或LLM)。依赖劳动密集型的人工注释来构建这样的知识库是不切实际的。LLM为我们带来了自动构建此类KB的巨大希望,因为它们是从大量文本中自我训练的,可以作为“隐式”的通用知识库,加上维基百科和本体论可能为我们提供一个良好的起点。我们提出了使用LLM开发此类主题特定知识库的愿景,包括查找主题特定文档、主题发现、分类结构构建、分类指导信息和知识库构建。希望这次演讲可以激发更多关于这一工作方向的讨论。

韩家炜是伊利诺伊大学厄巴纳-香槟分校计算机科学系的Michael Aiken讲席教授。他获得了ACM SIGKDD创新奖(2004年)、IEEE计算机学会技术成就奖(2005年)、IEEE计算机学会W. Wallace McDowell奖(2009年)、日本Funai成就奖(2018年),并在2022年被提升为加拿大皇家学会Fellow。他是ACM和IEEE的Fellow,并在2009-2016年担任由美国陆军研究实验室的网络科学-协作技术联盟(NS-CTA)项目支持的信息网络学术研究中心(INARC)的主任,以及在2014-2019年由NIH大数据至知识(BD2K)倡议资助的KnowEnG,大数据计算卓越中心的联席主任。目前,他正在为两个由NSF资助的研究中心的执行委员会服务:MMLI (分子制造研究所)——自2020年起是NSF资助的全国AI中心之一,以及I-Guide——自2021年起的国家科学基金会(NSF)地理空间理解通过综合发现环境研究所(I-GUIDE)。



成为VIP会员查看完整内容




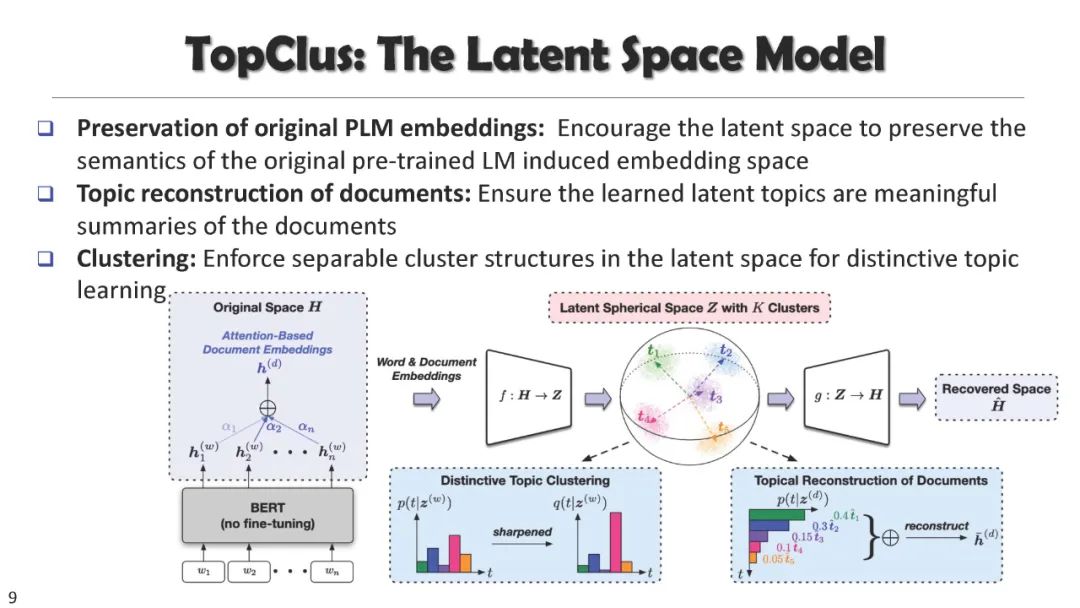
相关内容

伊利诺伊大学香槟分校(UIUC)工程学院是美国顶尖工程学院之一。其中,计算机系近年来排名稳居全美前五(US News)。根据学术排名权威网站 CSRankings.org,在软件工程方向(根据软件工程四大顶级会议发表情况), UIUC 目前位列全美第一。
Arxiv
0+阅读 · 2023年10月2日
Arxiv
224+阅读 · 2023年4月7日
相关主题



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月2日
Arxiv
224+阅读 · 2023年4月7日