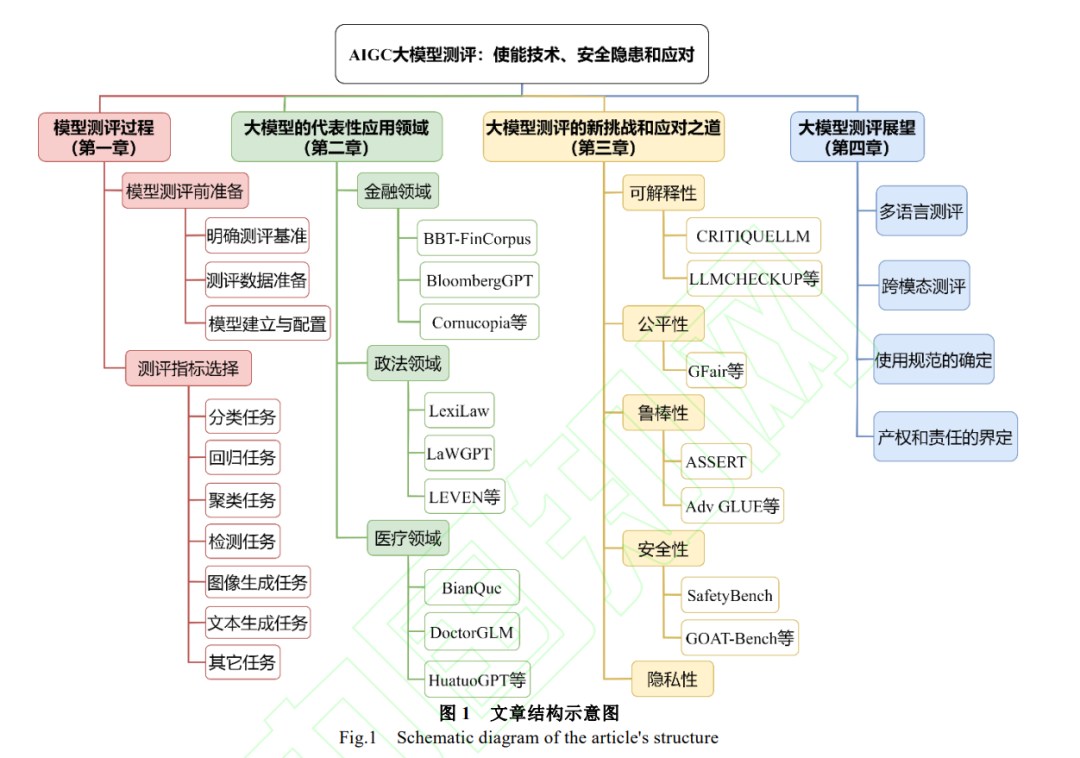
![]() 人工智能生成内容(AIGC)模型因其出色的内容生成能力在全球范围内引起了学术和工业界的广泛关注与应用。特别是以ChatGPT为代表的一批多模态AIGC大模型的出现,为人类社会生产生活带来了前所未有的智能体验和高阶应用。然而,AIGC大模型的快速发展也带来了一系列隐患,例如模型生成结果的可解释性、公平性和安全隐私等问题。在AIGC大模型融入各行各业的过程中,为了降低不可知风险及其危害,需要事先对AIGC大模型进行全面的测评。具体来说,包括以下三个方面:如何根据不同类任务准备数据,选择合适的测评基准/指标,怎样设计测评过程。学术界已经开启了AIGC大模型测评相关的研究,旨在有效应对相关挑战,避免潜在的风险。通过对这些模型测评研究的回顾,按照上述思路进行了综述和分析,涵盖了AIGC大模型测评过程,当前AIGC大模型在不同领域应用过程中面临的新挑战,以及这些挑战对应的应对措施。最后,探讨了AIGC大模型测评未来面临的挑战,并展望了其未来发展方向。人工智能生成内容(Artificial Intelligence Generated Content,AIGC)是人工智能领域发展的最新成果之一, 其主要是通过学习数据模式和规律,生成原创的内容, 包括文本、图像、音频等多媒体内容[1-2]。2017 年 OpenAI 开发了 GPT 系列模型[3],经过多年发展,培育出了全新 的人工智能现象级工具 ChatGPT[4],已经成为人工智能 领域全新的发展标杆,推动了人工智能相关研究向着通 用智能方向走出了关键一步。ChatGPT 一经推出就备受 瞩目,其在人机交互、对话、文档生成等任务中展现出 了接近人类的能力。衍生出的其他 AIGC 大模型应用已 经融入各行各业,吸引了数以亿万的用户,相关研究在 学术界和工业界得到了广泛的关注[5-12]。除了国外其它 组织提出的 BRET[13]、PaLM[14]、OPT[15]、BLOOM[16]、 LLaMA[17]、LLaMA2 [18]、Stable Diffusion[19]、Midjourney[20]和 GPT4[21]等大模型,我国在 AIGC 大模型领域也 取 得 了 显 著 的 进 展 , 提 出 了 包 括 清 华 大 学 的 ChatGLM[22]、ChatGLM2[23]和 WEBCPM[24]、百度的文 心一言[25]、阿里的通义千问[26]、复旦大学的 MOSS[27]、 哈尔滨工业大学赛尔实验室的“活字 1.0”和“活字 2.0”两 个版本的大语言模型、中国科学院的紫东太初[28]和华为 的盘古[29]等大模型。这些模型的不断进步推动了人工智 能技术的前进,为更加智能化的人机交互体验开辟了新 的可能性。 同其它人工智能模型类似,AIGC 生成式大模 型同样面临着数据和模型的限制。首先需要收集和 预处理数据,然后训练模型,并根据实际应用场景 进行模型微调,最后完成模型部署和发布。这一过 程的局限具体表现在以下三个方面:(1)在数据收 集阶段,若使用未经授权数据对模型进行训练,可 能导致数据泄漏的问题。(2)在模型训练过程中, 由于标注策略的局限,可能导致数据特征分布不均 匀。(3)在内容生成阶段,不均匀的数据分布将导 致生成具有偏见的内容。AIGC 在数据安全隐私和 生成内容公平性方面引发了广泛关注,另外生成内 容导致的虚假信息传播和生成内容版权等大量问 题都是急需研究的现实问题。为了防范和杜绝上述 问题及其他潜在隐患,在模型部署应用之前需要对 模型进行测评。AIGC 大模型属于大型深度神经网 络模型。长期以来,由于深度神经网络模型的不可 解释性,我们始终无法完全获知其模型运转机理, 这就造成对深度神经网络模型的测评一直是一个 棘手的问题。同时,考虑到未来 AIGC 大模型的规 模和复杂性将快速增长,如何对其进行安全、隐私 性和公平性等方面的测评是一个亟待解决的现实 问题。 大模型测评领域的大部分工作都集中在针对 新问题创新相应的测评方法方面,快速地、低成本 地测评新模型性能及数据对模型的影响[10,12,30-36]。 例如,Rao 等人[10]设计提示激励客观答案生成,然 后通过替换问题的主语,最后评估模型生成结果的 正确性。Zuccon 等人[12]在模型知识和结合提示知识 情况下对比模型生成答案的差异。Amos Azaria 等人 [30]从大模型内部状态的角度来测评生成内容的真 实性。Gao 等人[32]则采用不同的提示对模型进行测 评。Liu 等人[35]为更好地测评内容生成质量使用形 式填充范式测评模型。Wang 等人[36]将 ChatGPT 模 型视作人类评价者,并给出特定的任务和指令,提 示 ChatGPT 对 AIGC 大模型生成结果进行测评。 相应的测评基准也开始涌现。例如,MMLU[37]、 GAOKAO[38]、C-EVAL[39]、AGIEval[40]、CMMLU[41]、 M3Exam[42]、BIG-bench[43]和 HELM[44]等基准试图 聚合广泛的 NLP 任务,以进行整体测评。以上测评 的工作不仅涉及测评过程的设计,更是引出了大模 型测评的一些新的关注点,包括生成结果的公平性, Prompt 数据的安全隐私问题等。Chang 等人近期公 布了大语言模型测评综述的预印版初稿[45],从大模 型应用着手展开讨论。其当前版本还缺少对大模型 测评过程系统介绍,也没有对大模型应对挑战的解 决方案的综述,只是给出了一些初步的构想。针对 这些不足,本文对最新成果进行更为全面的综述, 同时力争更好地覆盖中文大模型测评问题。
人工智能生成内容(AIGC)模型因其出色的内容生成能力在全球范围内引起了学术和工业界的广泛关注与应用。特别是以ChatGPT为代表的一批多模态AIGC大模型的出现,为人类社会生产生活带来了前所未有的智能体验和高阶应用。然而,AIGC大模型的快速发展也带来了一系列隐患,例如模型生成结果的可解释性、公平性和安全隐私等问题。在AIGC大模型融入各行各业的过程中,为了降低不可知风险及其危害,需要事先对AIGC大模型进行全面的测评。具体来说,包括以下三个方面:如何根据不同类任务准备数据,选择合适的测评基准/指标,怎样设计测评过程。学术界已经开启了AIGC大模型测评相关的研究,旨在有效应对相关挑战,避免潜在的风险。通过对这些模型测评研究的回顾,按照上述思路进行了综述和分析,涵盖了AIGC大模型测评过程,当前AIGC大模型在不同领域应用过程中面临的新挑战,以及这些挑战对应的应对措施。最后,探讨了AIGC大模型测评未来面临的挑战,并展望了其未来发展方向。人工智能生成内容(Artificial Intelligence Generated Content,AIGC)是人工智能领域发展的最新成果之一, 其主要是通过学习数据模式和规律,生成原创的内容, 包括文本、图像、音频等多媒体内容[1-2]。2017 年 OpenAI 开发了 GPT 系列模型[3],经过多年发展,培育出了全新 的人工智能现象级工具 ChatGPT[4],已经成为人工智能 领域全新的发展标杆,推动了人工智能相关研究向着通 用智能方向走出了关键一步。ChatGPT 一经推出就备受 瞩目,其在人机交互、对话、文档生成等任务中展现出 了接近人类的能力。衍生出的其他 AIGC 大模型应用已 经融入各行各业,吸引了数以亿万的用户,相关研究在 学术界和工业界得到了广泛的关注[5-12]。除了国外其它 组织提出的 BRET[13]、PaLM[14]、OPT[15]、BLOOM[16]、 LLaMA[17]、LLaMA2 [18]、Stable Diffusion[19]、Midjourney[20]和 GPT4[21]等大模型,我国在 AIGC 大模型领域也 取 得 了 显 著 的 进 展 , 提 出 了 包 括 清 华 大 学 的 ChatGLM[22]、ChatGLM2[23]和 WEBCPM[24]、百度的文 心一言[25]、阿里的通义千问[26]、复旦大学的 MOSS[27]、 哈尔滨工业大学赛尔实验室的“活字 1.0”和“活字 2.0”两 个版本的大语言模型、中国科学院的紫东太初[28]和华为 的盘古[29]等大模型。这些模型的不断进步推动了人工智 能技术的前进,为更加智能化的人机交互体验开辟了新 的可能性。 同其它人工智能模型类似,AIGC 生成式大模 型同样面临着数据和模型的限制。首先需要收集和 预处理数据,然后训练模型,并根据实际应用场景 进行模型微调,最后完成模型部署和发布。这一过 程的局限具体表现在以下三个方面:(1)在数据收 集阶段,若使用未经授权数据对模型进行训练,可 能导致数据泄漏的问题。(2)在模型训练过程中, 由于标注策略的局限,可能导致数据特征分布不均 匀。(3)在内容生成阶段,不均匀的数据分布将导 致生成具有偏见的内容。AIGC 在数据安全隐私和 生成内容公平性方面引发了广泛关注,另外生成内 容导致的虚假信息传播和生成内容版权等大量问 题都是急需研究的现实问题。为了防范和杜绝上述 问题及其他潜在隐患,在模型部署应用之前需要对 模型进行测评。AIGC 大模型属于大型深度神经网 络模型。长期以来,由于深度神经网络模型的不可 解释性,我们始终无法完全获知其模型运转机理, 这就造成对深度神经网络模型的测评一直是一个 棘手的问题。同时,考虑到未来 AIGC 大模型的规 模和复杂性将快速增长,如何对其进行安全、隐私 性和公平性等方面的测评是一个亟待解决的现实 问题。 大模型测评领域的大部分工作都集中在针对 新问题创新相应的测评方法方面,快速地、低成本 地测评新模型性能及数据对模型的影响[10,12,30-36]。 例如,Rao 等人[10]设计提示激励客观答案生成,然 后通过替换问题的主语,最后评估模型生成结果的 正确性。Zuccon 等人[12]在模型知识和结合提示知识 情况下对比模型生成答案的差异。Amos Azaria 等人 [30]从大模型内部状态的角度来测评生成内容的真 实性。Gao 等人[32]则采用不同的提示对模型进行测 评。Liu 等人[35]为更好地测评内容生成质量使用形 式填充范式测评模型。Wang 等人[36]将 ChatGPT 模 型视作人类评价者,并给出特定的任务和指令,提 示 ChatGPT 对 AIGC 大模型生成结果进行测评。 相应的测评基准也开始涌现。例如,MMLU[37]、 GAOKAO[38]、C-EVAL[39]、AGIEval[40]、CMMLU[41]、 M3Exam[42]、BIG-bench[43]和 HELM[44]等基准试图 聚合广泛的 NLP 任务,以进行整体测评。以上测评 的工作不仅涉及测评过程的设计,更是引出了大模 型测评的一些新的关注点,包括生成结果的公平性, Prompt 数据的安全隐私问题等。Chang 等人近期公 布了大语言模型测评综述的预印版初稿[45],从大模 型应用着手展开讨论。其当前版本还缺少对大模型 测评过程系统介绍,也没有对大模型应对挑战的解 决方案的综述,只是给出了一些初步的构想。针对 这些不足,本文对最新成果进行更为全面的综述, 同时力争更好地覆盖中文大模型测评问题。 ![]()