
转载机器之心
本篇综述工作已被《IEEE 模式分析与机器智能汇刊》(IEEE TPAMI)接收,作者来自三个团队:香港大学俞益洲教授与博士生陈超奇、周洪宇,香港中文大学(深圳)韩晓光教授与博士生吴毓双、许牧天,上海科技大学杨思蓓教授与硕士生戴启元。
近年来,由于在图表示学习(graph representation learning)和非网格数据(non-grid data)上的性能优势,基于图神经网络(Graph Neural Networks,GNN)的方法被广泛应用于不同问题并且显著推动了相关领域的进步,包括但不限于数据挖掘(例如,社交网络分析、推荐系统开发)、计算机视觉(例如,目标检测、点云处理)和自然语言处理(例如,关系提取、序列学习)。考虑到图神经网络已经取得了丰硕的成果,一篇全面且详细的综述可以帮助相关研究人员掌握近年来计算机视觉中基于图神经网络的方法的进展,以及从现有论文中总结经验和产生新的想法。可惜的是,我们发现由于图神经网络在计算机视觉中应用非常广泛,**现有的综述文章往往在全面性或者时效性上存在不足,因此无法很好的帮助科研人员入门和熟悉相关领域的经典方法和最新进展。**同时,如何合理地组织和呈现相关的方法和应用是一个不小的挑战。

-
论文标题:A Survey on Graph Neural Networks and Graph Transformers in Computer Vision: A Task-Oriented Perspective
https://ieeexplore.ieee.org/document/10638815(IEEE 版)
尽管基于卷积神经网络(CNN)的方法在处理图像等规则网格上定义的输入数据方面表现出色,研究人员逐渐意识到,具有不规则拓扑的视觉信息对于表示学习至关重要,但尚未得到彻底研究。与具有内在连接和节点概念的自然图数据(如社交网络)相比,从规则网格数据构建图缺乏统一的原则且严重依赖于特定的领域知识。另一方面,某些视觉数据格式(例如点云和网格)并非在笛卡尔网格上定义的,并且涉及复杂的关系信息。因此,规则和不规则的视觉数据格式都将受益于拓扑结构和关系的探索,特别是对于具有挑战性的任务,例如理解复杂场景、从有限的经验中学习以及跨领域进行知识传递。
在计算机视觉领域,目前许多与 GNN 相关的研究都有以下两个目标之一:(1) GNN 和 CNN 主干的混合,以及 (2) 用于表示学习的纯 GNN 架构。前者通常旨在提高基于 CNN 的特征的远程建模能力,并适用于以前使用纯 CNN 架构解决的视觉任务,例如图像分类和语义分割。后者用作某些视觉数据格式(例如点云)的特征提取器。尽管取得了丰硕的进展,但仍然没有一篇综述能够系统、及时地回顾基于 GNN 的计算机视觉的发展情况。
在本文中,我们首先介绍了图神经网络的发展史和最新进展,包括最常用、最经典的图神经网络和图 Transformers。然后,我们以任务为导向对计算机视觉中基于图神经网络(包括图 Transformers)的方法和最新进展进行了全面且详细的调研。具体来说,我们根据输入数据的模态将图神经网络在计算机视觉中的应用大致划分为五类:**自然图像(二维)、视频、视觉 + 语言、三维数据(例如,点云)以及医学影像。**在每个类别中,我们再根据视觉任务的不同对方法和应用进一步分类。这种以任务为导向的分类法使我们能够研究不同的基于图神经网络的方法是如何处理每个任务的,以及较为公平地比较这些方法在不同数据集上的性能,在内容上我们同时还涵盖了基于 Transformers 的图神经网络方法。对于不同的任务,我们系统性地总结了其统一的数学表达,阐明了我们组织这些文章的逻辑关系,突出了该领域的关键挑战,展示了图神经网络在应对这些挑战的独特优势,并讨论了它的局限和未来发展路线。

图神经网络发展史
GNN 最初以循环 GNN 的形式发展,用于从有向无环图中提取节点表示。随着研究的发展,GNN 逐渐扩展到更多类型的图结构,如循环图和无向图。受到深度学习中 CNN 的启发,研究人员开发了将卷积概念推广到图域的方法,主要包括基于频域的方法和基于空域的方法。频域方法依赖于图的拉普拉斯谱来定义图卷积,而空域方法则通过聚合节点邻居的信息来实现图卷积。这些方法为处理复杂的图结构和不规则拓扑提供了有效的工具,极大地推动了 GNN 在多个领域,尤其是计算机视觉中的应用和发展。
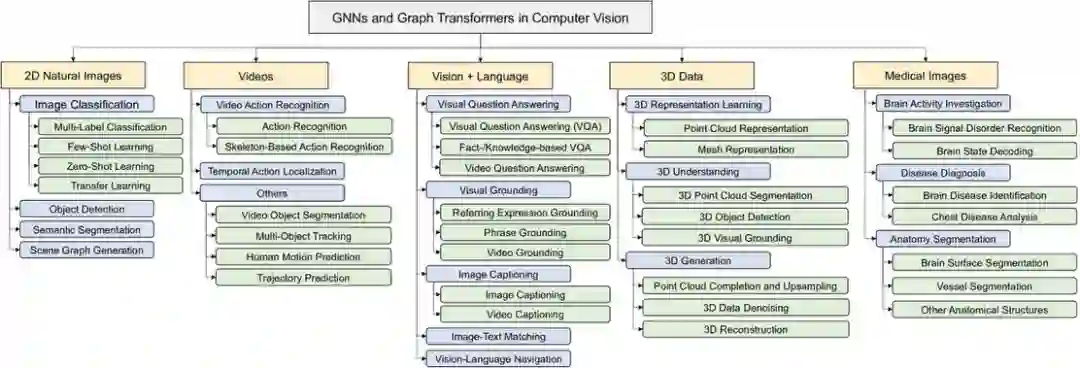
具体来说,我们详尽地调查了如下这些任务:
- 建立在自然图像(二维)上的视觉任务包括 Image Classification (multi-label、few-shot、zero-shot、transfer learning),Object Detection,Semantic Segmentation,和 Scene Graph Generation。
- 建立在视频上的视觉任务包括 Video Action Recognition,Temporal Action Localization,Multi-Object Tracking,Human Motion Prediction,和 Trajectory Prediction。
- 视觉 + 语言方向的任务包括 Visual Question Answering,Visual Grounding,Image Captioning,Image-Text Matching,和 Vision-Language Navigation。
- 建立在三维数据上的视觉任务包括 3D Representation Learning (Point Clouds、Meshes),3D Understanding (Point Cloud Segmentation、3D Object Detection、3D Visual Grounding),和 3D Generation (Point Cloud Completion、3D Data Denoising、3D Reconstruction)。
- 建立在医学影像上的任务包括 Brain Activity Investigation,Disease Diagnosis (Brain Diseases、Chest Diseases),Anatomy Segmentation (Brain Surfaces、Vessels、etc)。
总结来说,尽管在感知领域取得了突破性的进展,如何赋予深度学习模型推理能力仍然是现代计算机视觉系统面临的巨大挑战。在这方面,图神经网络和图 Transformers 在处理 “关系” 任务方面表现出了显著的灵活性和优越性。为此,我们从面向任务的角度首次对计算机视觉中的图神经网络和图 Transformers 进行了全面的综述。各种经典和最新的算法根据输入数据的模态(如图像、视频和点云)分为五类。通过系统地整理每个任务的方法,我们希望本综述能够为未来的更多进展提供启示。通过讨论关键的创新、局限性和潜在的研究方向,我们希望读者能够获得新的见解,并朝着类似人类的视觉理解迈进一步。
4 将通用LLM适应生物医学领域
当通用大型语言模型(LLM)以零样本方式应用于生物医学领域时,往往会遇到各种挑战,主要原因在于该领域的高度专业化。生物医学领域使用独特的词汇、命名法和概念框架,通用LLM可能无法理解这些内容[113]。这种特异性不仅限于术语,还包括生物实体之间的复杂关系、复杂的疾病机制以及细微的临床背景。此外,生物医学领域涵盖了多样化的任务,从文献分析和临床笔记解读到支持诊断决策和药物发现过程。这种多样性要求LLM能够执行广泛的专业功能,每项任务都需要领域特定的知识和推理能力[114, 115]。此外,生物医学研究越来越依赖多模态数据的整合,这些数据类型包括文本、图像(如放射学扫描、组织学切片)和分子序列(如DNA、蛋白质结构)[116, 117]。有效处理和综合这些不同来源的信息对LLM提出了额外的挑战。为了应对这些挑战并提高通用LLM在生物医学应用中的适用性,已经开发了几种适应策略。这些策略包括领域特定的微调、架构修改以及从头开始创建专门的生物医学LLM。图4展示了适应或创建LLM用于生物医学应用的过程,概述了从数据预处理和整理到模型训练、微调和评估的关键阶段。适应过程涉及整理高质量的、领域特定的数据集,以捕捉生物医学语言和知识的细微差别。然后,使用这些数据集对现有LLM进行微调或训练新模型,结合在生物医学语料库上继续预训练、任务特定微调和多任务学习等技术,以提高在各种生物医学任务中的表现[12, 88]。通过这些努力,出现了多种专门针对生物医学研究和临床实践的LLM模型。表2提供了这些微调和定制模型的概述,展示了它们在生物医学领域内的多样性和专业性。
**4.1 单模态适应策略
为了将通用LLM适应生物医学领域,微调可以使模型深入理解该领域的专业术语、复杂概念和语言习惯。这增强了它们在处理生物医学文本等专业数据时提供更准确和深入分析与生成的能力。微调方法包括全参数微调、指令微调、参数高效微调和混合微调。
全参数微调
全参数微调涉及使用领域特定的数据更新预训练LLM的所有参数。与传统的微调方法(如仅微调顶层)不同,全参数微调允许模型的每一层都学习任务特定的知识。例如,GatorTron[81]是一种在临床数据上微调的模型,在医学问答中达到了93.01%的F1分数,超过了之前的基准7.77%。尽管全参数微调通常可以带来最佳表现,但它也伴随着高昂的计算成本。例如,微调GatorTronGPT-20M[17]耗费了超过268,800 GPU小时(使用A100 GPU),这使得资源受限的环境难以承担。
指令微调
指令微调(IFT)是一种通过修改预训练模型的基础指令来优化其在生物医学领域特定任务或领域中的适应性的技术[118]。这一方法在提高模型在专门医学任务上的表现方面显示出了良好的效果。例如,MEDITRON[96]是一种在LLaMA-2上使用IFT微调的模型,在多个医学基准测试中平均表现提高了1.8%。同样,AlpaCare[100]利用了精心整理的52,000条医学指令,在HeadQA基准测试中实现了30.4%的性能提升,展示了精心设计的指令集在提升模型能力方面的潜力。IFT的主要优势在于,它能够使用相对较少的数据将模型适应特定的生物医学领域。然而,IFT的有效性在很大程度上依赖于所用指令的质量和多样性。设计不良或有偏见的指令可能导致模型行为不一致或不可靠,从而在关键的医学应用中削弱模型的实用性。
参数高效微调
参数高效微调(PEFT)包括一组旨在通过调整模型的少部分参数来提高LLM性能和训练效率的技术[119]。两个显著的PEFT方法是LoRA(低秩适应)[120]和QLoRA(量化LoRA)[121],通过向模型添加可训练的小矩阵来实现任务特定的适应,而不修改整个模型架构。PEFT方法的效率令人瞩目,通常可以减少99%以上的可训练参数,同时保持与全微调相当的性能。例如,MMedLM 2[68]使用LoRA在多语言医学问答任务中取得了竞争性的表现,同时只微调了模型参数的一小部分。这种方法减少了计算需求,使得在资源有限的环境(如小型医院或研究实验室)中部署定制的医疗AI模型成为可能。然而,当任务需要对基础模型知识进行大量修改时,PEFT方法可能会面临局限,因为它们主要侧重于适应现有知识,而不是引入全新的信息。这一限制可能会影响其在高度专业化或快速发展的生物医学领域中的有效性。
混合微调
混合微调是一种结合多种参数高效调优技术以提高模型性能和训练效率,同时尽量减少额外参数引入的方法。例如,HuatuoGPT[10]通过监督微调和RLAIF[122],在GPT-4评估、人类评估和医学基准数据集上表现出了在开源LLM中执行医疗咨询的最新成果。混合微调策略在性能和效率之间提供了平衡,解决了单一技术的一些局限性。它们允许模型更灵活地适应医疗AI的独特挑战,如既需要广泛的医学知识,又需要专业的医学知识。然而,这些方法通常需要更复杂的实现和多个组件的精细调优。
**4.2 多模态适应策略
多模态LLM可以整合不同的数据类型,从而提供全面的见解。该模型的核心优势在于能够融合来自不同模态的信息,包括文本、图像、基因序列和蛋白质结构。这种融合不仅弥合了跨学科的差距,还反映了医疗诊断和研究的多面性[123]。在临床环境中,患者评估通常涉及多种数据类型,包括文本信息(如医疗报告)、视觉数据(如X光和MRI)以及数值测量(如实验室结果和生命体征)。多模态LLM旨在整合这些不同来源的数据,以提供更准确和全面的生物医学见解。例如,通过将医学影像与临床文本报告和其他相关数据结合,这些模型可以提高诊断的准确性和稳健性[124]。此外,多模态模型还可以促进基因组数据与表型信息的整合,从而更全面地研究疾病机制并发现新药物[112]。
微调策略在生物医学多模态模型的应用中发挥了关键作用,确保这些模型能够充分理解和处理跨模态数据。这些策略包括通过LoRA[120]和层归一化[125]技术优化视觉编码器。此类优化旨在增强模型解读医学图像中关键特征的能力。同时,这些策略整合了视觉和文本输入,利用注意力机制和多层感知器(MLP)层增强模型在生成放射学报告中的能力,例如ClinicalBLIP[110]模型。具体而言,ClinicalBLIP在使用MIMIC-CXR[126]数据集的放射学报告生成任务中表现优异,通过这些微调策略获得了0.534的METEOR评分[127],显著超越了其他模型的表现,突出展示了ClinicalBLIP在处理复杂多模态数据方面的卓越能力。同样,Med-Gemini[111]采用了构建联合嵌入空间的策略,能够在统一的潜在空间内直接比较和整合来自不同模态的数据。这一策略在复杂的医疗任务中表现出色,特别是在癌症诊断方面,整合基因组数据和病理图像显著提高了诊断准确性。这些微调策略通过优化模型在生物医学多模态任务中的表现,展示了多模态模型在医学领域应用的巨大潜力。此外,它们强调了微调在提高模型泛化能力和任务适应性中的关键作用。
**4.3 训练数据与处理策略
将通用LLM适应生物医学领域的关键在于数据的质量、多样性和处理方式。本小节将探讨开发和改进生物医学LLM时使用的关键数据集和有效策略。 4.3.1 数据集概述
用于LLM训练和评估的生物医学数据集主要分为三类:基于文本、基于图像和多模态。表3总结了最近研究中使用的数据集。基于文本的数据集如PubMed,在训练模型如BioGPT[27]中起到了重要作用。同样,包含超过40,000名患者去识别健康记录的MIMIC-III数据集为GatorTron[81]等模型提供了学习真实世界临床数据的机会。多模态数据集整合了各种数据类型,促进了更全面的模型训练。MultiMedBench[66]数据集通过将临床笔记与医学测量和影像数据对齐,体现了这一方法。基于这些数据集训练的模型如Med-PaLM M[66]在需要整合异质数据类型的任务中表现出色,弥合了文本和视觉医学信息之间的差距。
4.3.2 数据处理策略
为了最大限度地利用这些数据集,研究人员采用了多种数据处理技术。
数据增强
数据增强旨在增加数据集的大小和多样性,从而提高模型的稳健性和泛化能力。Chen等人[20]在开发BianQue时结合了自动数据清理和基于ChatGPT的数据优化。这一方法不仅提高了训练数据的质量,还使模型在医疗咨询任务中的表现提高了15%。
数据混合
整合多样化的数据源也能增强模型能力。Bao等人[21]在DISC-MedLLM中展示了这一点,采用了数据融合策略。通过结合来自医学知识图谱的结构化信息与人工筛选的样本,他们在处理医疗查询方面相比于仅在单一数据源上训练的模型提升了20%。
4.3.3 LLM中的联邦学习
在生物医学LLM领域,由于严格的医疗法规,直接的数据共享通常不可行。联邦学习(FL)[128]作为一种变革性解决方案,可能会重新塑造未来的LLM训练方式。与在单一专有数据中心训练的传统LLM不同,生物医学LLM需要通过FL有效访问多样化的数据集。OpenFedLLM框架[129]促进了跨地理分布数据集的联邦学习,同时推动了伦理对齐。对此,Wu等人[130]提出了专门设计用于增强医学语言建模的FedMed框架,以缓解联邦学习环境中的性能下降。Zhang等人[131]进一步推进了这一领域,展示了将联邦学习与基于提示的方法结合用于临床应用的有效性,增强了模型的适应性,同时保护了患者隐私。Nagy等人[132]探讨了用于训练大型语言模型(如BERT和GPT-3)的隐私保护技术,提供了在不影响性能的情况下保持隐私的见解。为应对多语言挑战,Weller等人[133]研究了在多个语言环境中使用预训练语言模型进行联邦学习的方法,重点关注医学领域的各种NLP任务。最后,Kim等人[134]提出通过在预训练的LLM中集成适配器机制来提高联邦学习中的计算效率,展示了使用较小的Transformer模型来降低计算需求的好处。
**4.4 总结
本节探讨了将通用LLM适应生物医学领域的过程,重点介绍了数据质量、处理策略与模型适应技术之间的重要关系。我们回顾了多样化数据集和先进数据处理方法在开发稳健的生物医学LLM中的基础作用,并考察了从全参数微调到更高效的指令微调和参数高效技术的各种适应方法。尽管取得了这些进展,数据隐私、模型可解释性和公平性方面的挑战仍然存在。未来的研究可以着眼于开发更高效、可解释且符合伦理的适应技术。重点领域包括提高模型透明性、解决公平性问题,以及探索高级联邦学习方法,以在保护患者隐私的同时利用分散的医疗数据。多模态方法的整合也为更全面的医疗解决方案提供了有希望的途径。随着生物医学LLM的持续发展,在平衡技术创新与伦理考量方面将变得尤为重要。通过解决当前的挑战并抓住新兴的机遇,这些模型有望彻底改变医疗保健,从提高临床决策支持到加速生物医学研究,最终实现更有效和更公平的医疗服务提供。

