

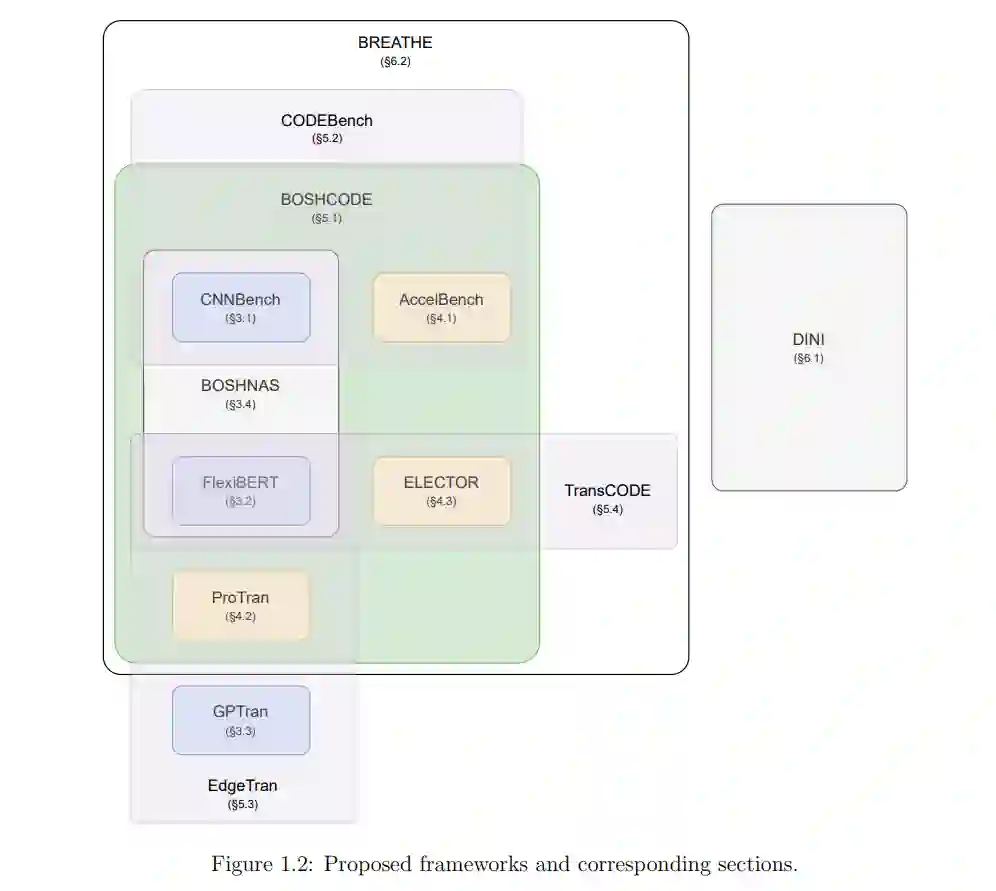
在过去的十年里,人工智能(AI)在工业和学术界获得了显著的关注。深度神经网络(DNN)模型的大小随着时间的推移而急剧增加。对图形处理单元(GPUs)和机器学习(ML)加速器的更广泛访问,以及数据集大小的增加,推动了这种增长。然而,就准确性、峰值功率消耗、能耗和集成电路芯片面积而言,在硬件上有效评估这些模型仍然具有挑战性,需要长时间的设计周期和领域专业知识。模型大小的增加加剧了这个问题。在这篇论文中,我们提出了一套从不同角度针对这一挑战的框架。我们提出了FlexiBERT,第一个针对异构和灵活变换器架构的宽范围设计空间。然后我们提出了AccelTran,一种最先进的变换器加速器。以AccelTran为动力,我们提出了ELECTOR,一个变换器加速器的设计空间,并利用我们的共设计技术,即BOSHCODE,实施了变换器加速器的共设计。我们还提出了EdgeTran,一种共搜索技术,用于找出最佳表现配对,即变换器模型和边缘AI设备。我们将这个框架应用于卷积神经网络(CNNs)同样(CODEBench)。最后,我们讨论了BOSHCODE的两个扩展:DINI用于数据插补和BREATHE用于在向量和图形搜索空间中进行通用的多目标优化。这些工作将所提出方法的应用范围扩展到了更多样化的应用集合。





成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日