作为现代信息获取的基石,搜索引擎在日常生活中已变得不可或缺。随着人工智能(AI)和自然语言处理(NLP)技术,特别是大型语言模型(LLM)的快速进展,搜索引擎已进化为支持用户与系统之间更直观和智能的交互。会话式搜索作为下一代搜索引擎的新兴范式,利用自然语言对话来促进复杂且精确的信息检索,因而受到广泛关注。与传统的基于关键词的搜索引擎不同,会话式搜索系统通过支持复杂查询、在多轮交互中保持上下文,并提供强大的信息集成和处理能力来提升用户体验。关键组件如查询重构、搜索澄清、会话式检索和响应生成协同工作,以实现这些复杂的交互。在本综述中,我们探讨了会话式搜索的最新进展及未来可能的发展方向,分析了构成会话式搜索系统的关键模块。我们重点讨论了LLM在增强这些系统中的作用,并探讨了这一动态领域中面临的挑战和机遇。此外,我们还提供了对实际应用的见解以及当前会话式搜索系统的稳健评估,旨在为会话式搜索领域的未来研究和开发提供指导。
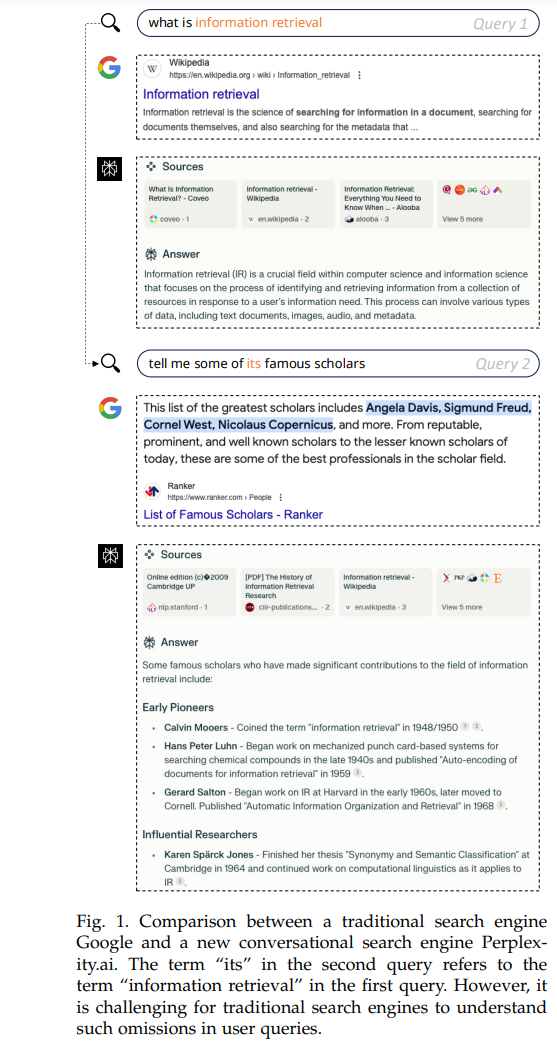
搜索引擎已经成为现代社会不可或缺的一部分,是满足用户信息需求的重要工具。它们的发展在很大程度上得益于人工智能(AI)的进步[1]。近年来,随着自然语言处理(NLP)技术的快速发展,特别是大型语言模型(LLM)的出现[2],搜索引擎逐步演变为提供更智能和互动的用户体验。会话式搜索是该领域中的一个显著进展,这一新兴范式通过自然语言交互为复杂和精确的信息获取提供支持。目前,商用会话式AI搜索引擎,如Perplexity.ai和SearchGPT,已经被广泛部署,迅速吸引了大量用户并保持显著增长。 与依赖关键词或短语的传统搜索引擎相比,会话式搜索利用自然语言对话进行交互[3–7],大大提高了信息交换的效率,并优化了用户体验。这种方法支持更加复杂的用户查询,管理更长、更复杂的历史上下文,并提供综合的信息集成和处理能力。此外,会话式搜索支持多样化的信息交付方式,能够与用户进行主动的交互[8–10]。例如,这些系统可以主动提出澄清性问题[11–13]、进行推荐[14],并通过对话引导用户更好地表达需求。图1展示了传统搜索与会话式搜索的区别。在一个真实的示例中,像Google这样的传统搜索引擎无法在查询之间保持上下文。在用户查询“什么是信息检索”之后,紧接着询问“告诉我一些著名学者”,搜索引擎会给出不相关的结果,因为它没有识别出用户仍然指的是“信息检索学者”。相比之下,Perplexity.ai作为会话式搜索引擎,能够通过保留上下文,正确解读后续问题,并提供关于信息检索领域著名学者的准确信息。
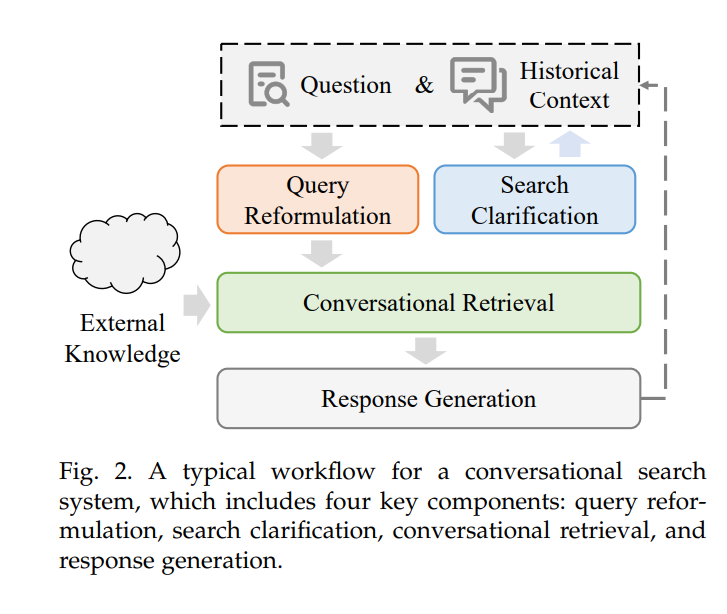
一个典型的会话式搜索系统由多个关键模块组成,每个模块涉及多种先进技术。随着该领域的不断演进,它既带来了重要的机遇,也面临诸多挑战。在本综述中,我们将探索和分析构建会话式搜索系统的最关键组件,按照整个信息流的顺序进行研究。我们重点包括查询重构、搜索澄清、会话式检索和响应生成。这些组件协同工作,支持更加自然和直观的用户与系统交互,从而最终提升整体搜索体验。
查询重构:查询重构是会话式搜索系统和传统搜索引擎中的一个关键初始步骤。它涉及诸如查询扩展[15, 16]、重写[7, 17]和查询分解[18]等技术,以重构查询,从而提升后续系统模块的性能。在会话式搜索中,准确解读用户当前的信息需求尤为重要,因为这需要基于对话上下文的不断变化。随着对话的进行,这种上下文会变得越来越复杂和冗长,传统搜索引擎往往难以处理多轮输入。因此,查询重构在将整个对话上下文和当前查询精炼为简洁且全面的用户需求表达中起着至关重要的作用。这个过程确保了后续组件能够更有效地处理和响应用户的查询。
搜索澄清:搜索澄清是会话式搜索系统中的另一个关键组件。它通过互动对话让用户完善其搜索查询,适用于寻求信息、执行任务或导航网站等场景[19–21]。用户往往以模糊或多方面的方式表达其搜索意图。为提高理解,系统可以提出澄清性问题,如“您指的是[具体术语]吗?”或“您能提供更多关于[主题]的细节吗?”,而不是直接回答查询。当系统检测到需要澄清时,它会主动提出这些问题,以更好地理解用户的意图。这种方式确保了系统提供更加准确和相关的搜索结果,通过使搜索过程更加个性化和有效来提升整体用户体验。搜索澄清的主要挑战在于准确且高效地识别何时需要澄清,以及生成适当的澄清性问题。
会话式检索:在查询和上下文经过重构并完成必要的澄清后,系统将从外部知识库中检索相关信息,以满足用户的信息需求。与传统的即时检索不同,会话式检索面临着从广泛的知识库中提取有用知识片段的独特挑战,尤其是在复杂对话的上下文中。该过程要求系统有效管理多轮交互和扩展的上下文长度,以确保检索到最相关的信息,从而为用户提供准确和有帮助的响应[22]。一种直接的方法是利用先前重构的会话查询进行检索[5, 7]。然而,由于上游查询重写器往往难以根据下游检索信号进行优化,这种方法可能会失败。此外,随着上下文变得更长且用户的信息需求愈加复杂,生成简洁而有效的查询重写变得越来越具有挑战性。一个新兴且前景广阔的解决方案是会话密集检索,它通过训练会话编码器直接对整个上下文进行编码[23–27]。这种方法避免了显式的查询重写,能够利用排序信号进行直接优化,可能带来更优的性能。然而,由于编码整个上下文的复杂性,训练一个高效的会话密集检索器仍然具有挑战性。此外,与传统搜索引擎类似,会话式搜索系统还需要在复杂的上下文中更精确地重新排序检索到的内容[28]。这一重新排序过程至关重要,因为它确保后续的响应生成模块能够访问最相关的内容,从而生成更加准确和有用的响应。
响应生成:下一代会话式搜索系统与传统搜索引擎的一个重要区别在于它们不仅仅提供链接列表。会话式搜索系统能够根据用户的需求定制响应,提供多种输出格式,如直接且简洁的答案、摘要内容[29],甚至是表格等结构化数据[30]。在会话式检索和重新排序阶段完成后,系统会尝试综合检索到的信息以及上下文对话,生成精确且相关的响应。然而,这一生成过程仍面临诸多挑战,包括确定适当的内容呈现格式、优化模型的准确性以有效利用检索到的知识、管理内部和外部知识源之间的冲突、处理极其长的上下文信息生成[31],以及提供准确的引用标注以便于源验证[32]。应对这些挑战对于提升会话式搜索系统的有效性和可靠性同样重要。
这四个关键组件——查询重构、搜索澄清、会话式检索和响应生成,构成了通用会话式搜索系统的基础框架。除了这些核心元素,这类系统已经成功适用于特定领域,包括医疗[33–42]、金融[43–48]和法律领域[49–52],并针对特定用户需求和上下文要求进行了定制化。这些应用涵盖了广泛的领域,从利用先进语言模型的个性化医疗咨询[33],到帮助投资者导航复杂市场数据的直观金融咨询服务[46]。在法律领域,会话式搜索系统促进了高效的案件检索,并支持复杂的法律推理[49]。此外,除了这些特定领域之外,会话式搜索系统还通过提供个性化产品推荐和响应客户服务互动,提升了电商平台的用户体验[53]。这些广泛的应用展示了会话式搜索在应对当代信息检索挑战中的适应性和日益重要的作用。
总之,本综述旨在回顾构建会话式搜索系统的关键技术组件,并探讨其在现实世界中的应用。我们将分析查询重构、澄清、会话式检索、响应生成和特定领域的应用,了解这些模块如何协同工作,以实现更加自然和智能的用户交互。此外,我们还将总结现有的资源和评估协议,以推动该领域的进一步研究。我们的目标是为研究人员和工程师提供会话式搜索领域挑战与机遇的全面概述。本文将展示每个阶段的技术挑战,探索当前的解决方案,并概述未来的方向,以鼓励在这一新兴领域的进一步创新和发展。
我们的论文与先前关于会话式搜索的综述[54–57]有两个显著的区别。首先,早期的综述是在ChatGPT出现之前进行的,主要关注没有LLM的传统方法。LLM的出现彻底改变了这一领域的技术和应用场景,推动了真正商用会话式搜索引擎的发展。我们的综述结合了会话式搜索中的最新LLM技术,并讨论了相关的新挑战和机遇。其次,我们的综述采用了更系统的方法。我们从会话式搜索引擎中的信息流角度对现有研究进行了结构化的回顾,特别关注四个关键模块(即查询重构、澄清、会话式检索和响应生成)。图3展示了会话式搜索的整体概述,使用结构化的分类对现有研究进行了分类。
本综述的剩余部分组织如下:第2、3、4、5节分别从查询重构、澄清、会话式检索和会话响应生成四个关键模块的角度回顾了进展和关键问题。接着,第6节介绍了在特定领域和以用户为中心的场景下进行的开创性会话式搜索研究。第7节总结了现有的基准并讨论了改进会话式搜索系统的评估协议。最后,第8节我们总结了本文,并讨论了未来可能的几个发展方向。