编译 | 许俊林 审稿 | 姜晶
本文介绍由德国神经退行疾病研究中心、波恩大学Joachim L. Schultze教授团队发表在Nature Reviews Immunology的研究成果。人类免疫学可能很快就会从人工智能和区块链技术的使用中受益。在这里,作者讨论了群体学习如何通过分享见解而非数据,来促进全球免疫学合作研究,充分尊重当地数据隐私法规。

几十年来,免疫学研究得益于高度标准化的动物模型。然而,随着知识的增加,从模型系统到人类疾病的转换问题越来越难,而且失败率较高。与此同时,从基因组学到单细胞水平的技术进步,将人工智能(AI)引入生物医学研究领域,以及模拟人类疾病的新方法(包括类器官或芯片实验室方法)正在彻底改变医学,包括人类免疫学。单细胞RNA测序(RNA-seq)和质谱流式细胞技术等方法提供了重要的见解,但同时需要新的分析方法,特别是在大型临床中心研究中。在这里,机器学习(即使用数据自动改进模型的AI分支)是自动缩放和揭示单细胞数据中的分子模式的先决条件。发挥机器学习算法的全部潜力,例如,从高通量数据中进行疾病分类或分层,需要包括数百名患者,以适应由于当地实验批次、年龄、性别、遗传背景或种族等因素造成的潜在偏差。收集数据本身就是一项艰巨的任务,世界上很少有研究中心能够自行开展此类研究。尽管每年采集的血液和生物组织样本有数百万份,但由于个人数据保护法,共享这些样本数据受到很大限制。立法在保护个人的健康数据方面设置了很高的门槛,这是合理的;然而,这些法律同时阻碍了科学进步。
为了克服这些限制,作者最近开发了群体学习 (Swarm Learning, SL)作为一种完全分散的机器学习原则,在充分考虑数据隐私法规的情况下,促进多个站点数据的整合。从概念上讲,SL是一种分散的方法,通过参数共享来训练机器学习模型的联合的同时,在本地保持私人数据的安全(图1a)。每个参与站点都是Swarm网络中的一个节点,这些站点使用本地数据参与模型训练。通过私有许可的区块链技术确保数据的安全性、机密性和主权。新节点可以通过区块链智能合约进入Swarm网络,以全自动电子方式调节Swarm网络成员的条件。新的Swarm成员同意合作条款,获取模型并进行本地训练,直到达到联合训练目标。这种方法为克服科学合作的局限性提供了机会,因为多个研究站点可以很容易地联合起来解决相同的研究问题,但可以使用更大的数据进行分析,无需在站点之间共享原始数据。
学习不同站点数据的联合模型需要就数据集及其预处理以及共同商定的模型达成一致。为了实现高质量的输入,数据集需要在样本处理、测量特征的选择和数据预处理方面达到最低水平的标准化。在基因组学研究中,具有准确基因注释的人类参考基因组是通用的参考基因组,然后可以将RNA-seq数据与参考进行比对。对于人类来说,所有数据都跨越相同的特征空间,这些特征空间通常包含超过30,000个基因。相比之下,在流式细胞术和质谱流式细胞术以及CITE-seq和Ab-seq中,抗体观察到的测量特征的数量级在10到100之间(图1b),但可能的表面分子数量超过1,000。需要注意的是,并非所有表面分子都有可用的抗体对应物。因此,细胞表面蛋白标记技术的实验局限性,要求进行彻底的标记物选择。面板设计通常针对研究问题和感兴趣的细胞类型,也就是说,T细胞面板包含与B细胞面板不同的标记物,几乎没有重叠。当不同站点提供的数据在所选标记物中差异很大时,即使测量相同的疾病,使用这些数据进行联合建模也变得具有挑战性。在这里,SL能更广泛应用,其关键是面板和抗体浓度的标准化。例如,白血病的临床诊断已被EuroFlow联盟成功标准化,而后商业化。因此,由于更高的标准化水平,诊断社区已经可以从SL中受益,通过使用创新的AI应用程序访问和分析大型数据集来进一步优化测试开发。此外,使用整合模型对来自相同样本的多个面板进行分类,允许在标记物选择方面具有更大的灵活性。机器学习在流式细胞术中的应用都将受益于数据预处理的标准化(图1c)。例如,由于荧光染料中的光谱重叠,流式细胞术数据预处理涉及微调补偿,通过手动处理归一化可以达到数据处理的标准化要求。尤其是想要结合来自流式细胞仪和质谱流式细胞术以及来自CITE-seq和Ab-seq等不同模式的数据时,输入数据需要遵守可转移的标准。细胞表面标记物分析的原理同样适用于人类免疫学中的其他典型数据类型,例如,基于血浆的蛋白质标记物或体外免疫激活面板。
SL支持不同类型的模型,而且具有广泛的应用。深度学习模型,尤其是变分自编码器,在处理高通量、高维单细胞数据时,表现出卓越的性能,例如整合数据任务。此外,它们可用于在一个站点构建参考图集、共享数据模型以及在不同站点整合新数据。虽然这种方法依赖于创建参考的单个实体,但它表明了在完全分散的设置中使用SL的分布式深度学习模型具有较大的潜力。这些模型的优点是对学习的潜在空间具有直观的可解释性,这能够对细胞而不仅仅是对整个样本进行分类。作者相信,这种粒度级别对于基于免疫的生物标志物的开发至关重要,并且只能通过整合来自许多不同机构和医院的足够大的数据集来实现,而无需在SL设置共享原始数据。
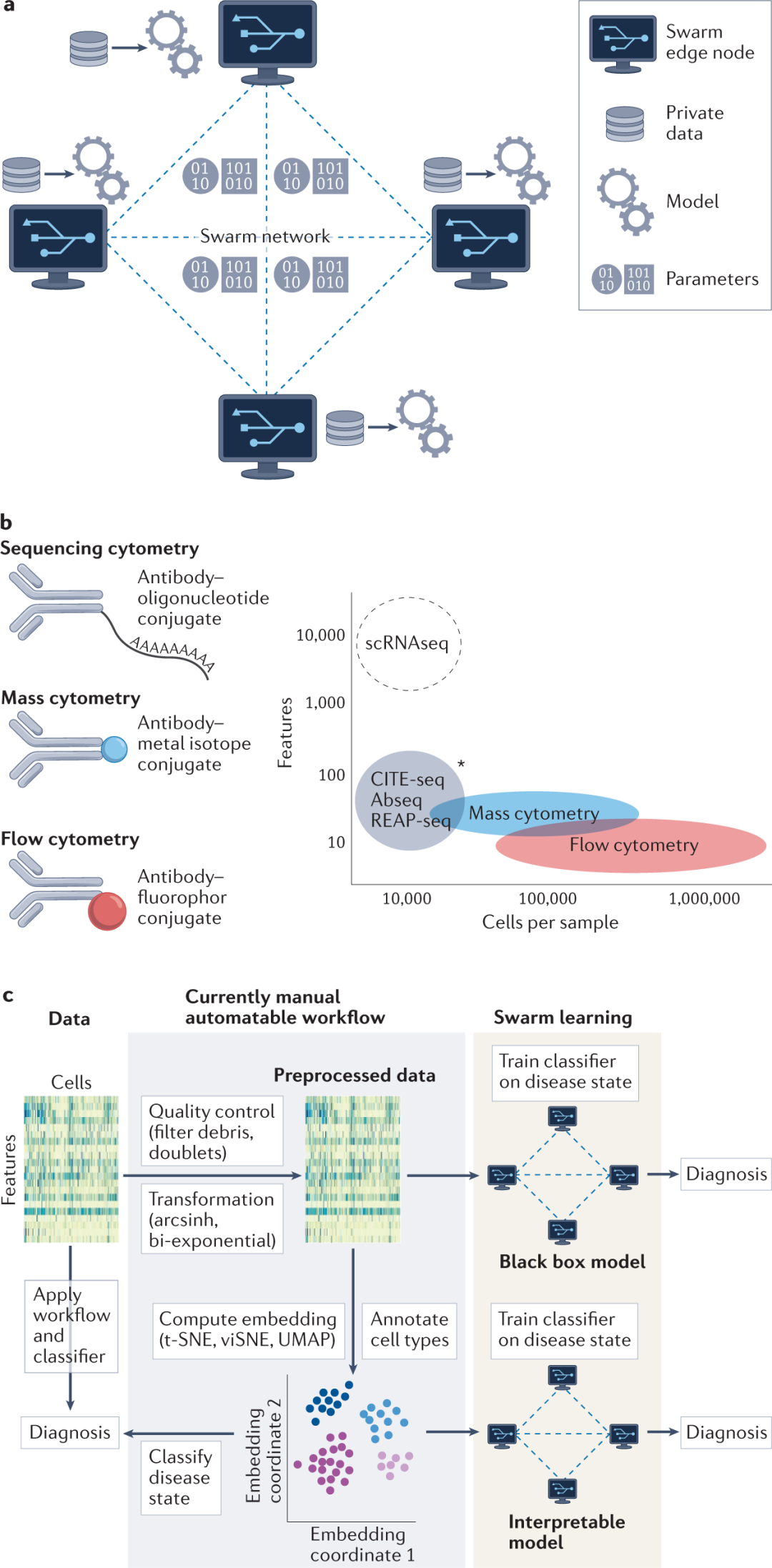
图1 群体学习
总之,SL为临床背景下的科学研究开辟了新的视角。在一个足够大的Swarm网络中,人们将能够利用观察到的人类所有类型的扰动,例如对疫苗接种或传染病的反应,从大量数据中推断出人类免疫系统的因果原理。一个协调一致的系统免疫学计划可以轻松地在全球范围内收集人类样本,并创建大型人类群体,为研究人类疾病的分子机制提供足够的数据。从使用机器学习进行疾病分类到无偏生物标记物发现,这些扩大的群体是成功临床应用的关键。例如,COVID-19大流行病加速了德国COVID-19组学计划(DeCOI)中的合作,并可能成为未来大流行病的蓝图。
在下一步,作者需证明异构免疫数据确实适用于SL原则。此外,这种SL支持的国际活动将极大地受益于人类免疫学数据标准化的改进。开发能够方便访问SL项目的平台将促进该领域的发展。最后,如果成功,免疫生物标志物和基于AI的疾病分类和分层需要在成为护理标准之前获得当局的批准,这本身就需要进一步的努力和发展。尽管如此,人类免疫学研究真正一体化时代即将开始。
参考资料 Schultze, J.L., Büttner, M. & Becker, M. Swarm immunology: harnessing blockchain technology and artificial intelligence in human immunology. Nat Rev Immunol (2022). https://doi.org/10.1038/s41577-022-00740-1