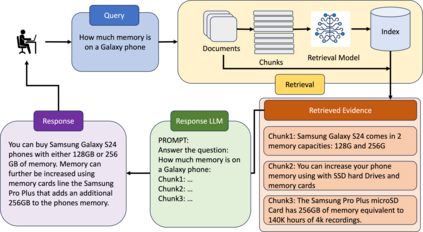
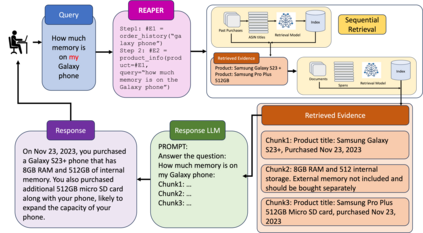
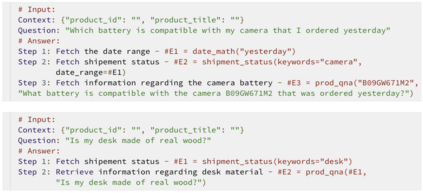
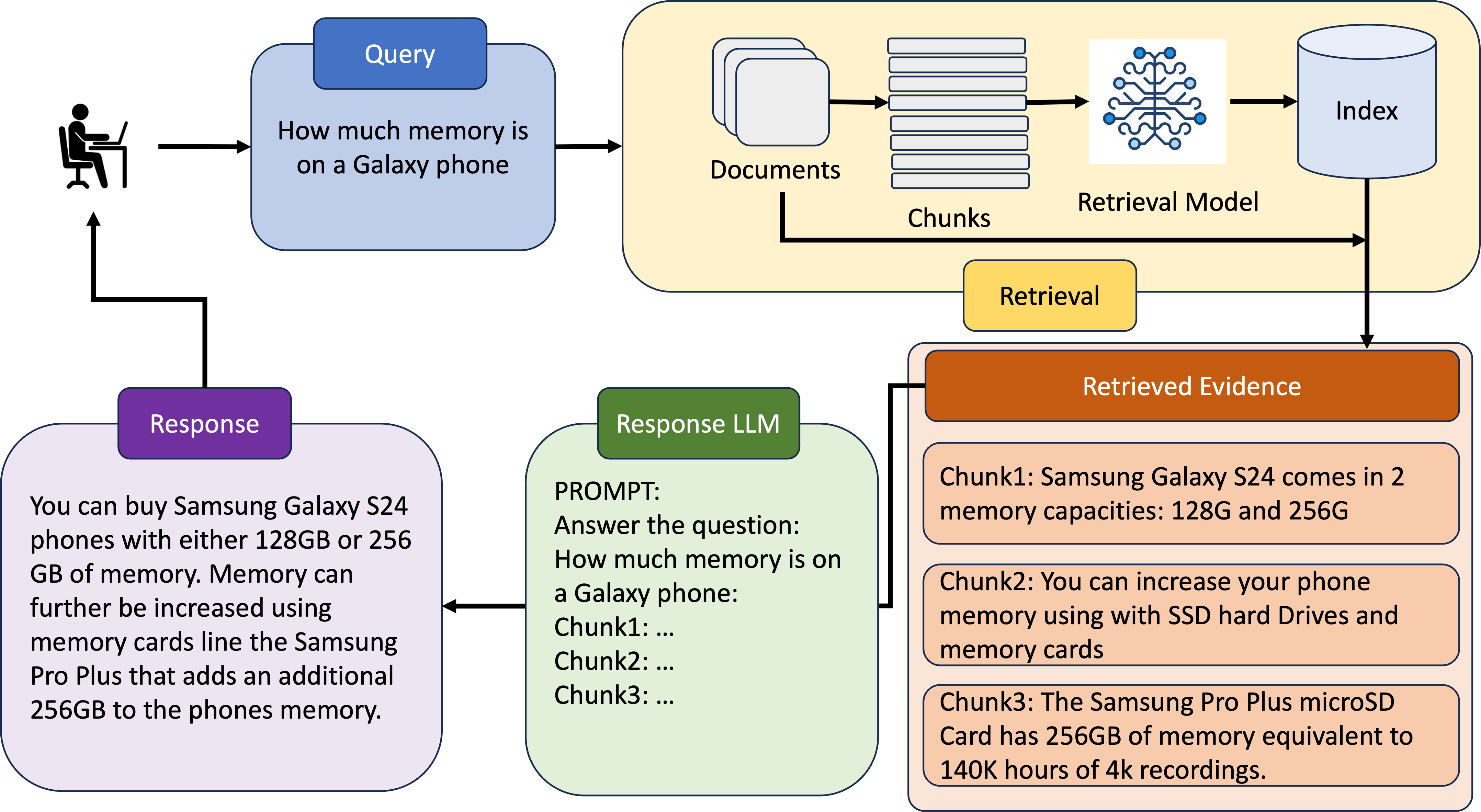
Complex dialog systems often use retrieved evidence to facilitate factual responses. Such RAG (Retrieval Augmented Generation) systems retrieve from massive heterogeneous data stores that are usually architected as multiple indexes or APIs instead of a single monolithic source. For a given query, relevant evidence needs to be retrieved from one or a small subset of possible retrieval sources. Complex queries can even require multi-step retrieval. For example, a conversational agent on a retail site answering customer questions about past orders will need to retrieve the appropriate customer order first and then the evidence relevant to the customer's question in the context of the ordered product. Most RAG Agents handle such Chain-of-Thought (CoT) tasks by interleaving reasoning and retrieval steps. However, each reasoning step directly adds to the latency of the system. For large models this latency cost is significant -- in the order of multiple seconds. Multi-agent systems may classify the query to a single Agent associated with a retrieval source, though this means that a (small) classification model dictates the performance of a large language model. In this work we present REAPER (REAsoning-based PlannER) - an LLM based planner to generate retrieval plans in conversational systems. We show significant gains in latency over Agent-based systems and are able to scale easily to new and unseen use cases as compared to classification-based planning. Though our method can be applied to any RAG system, we show our results in the context of a conversational shopping assistant.
翻译:暂无翻译