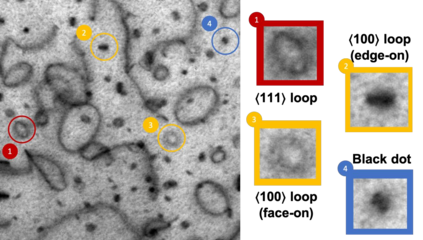
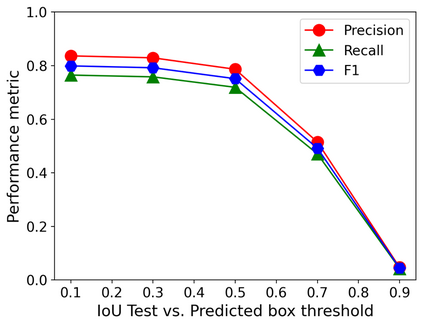
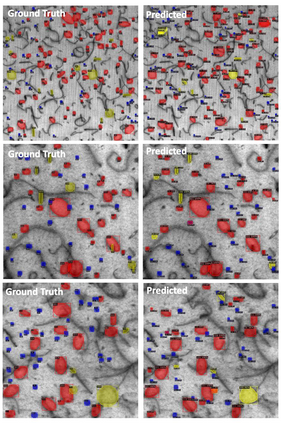
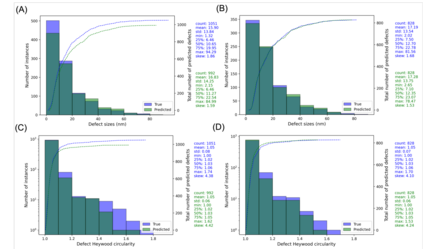
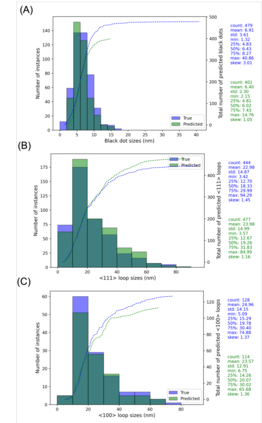
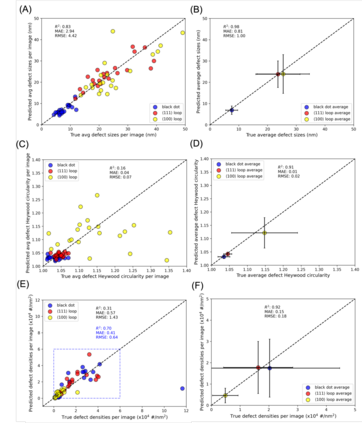
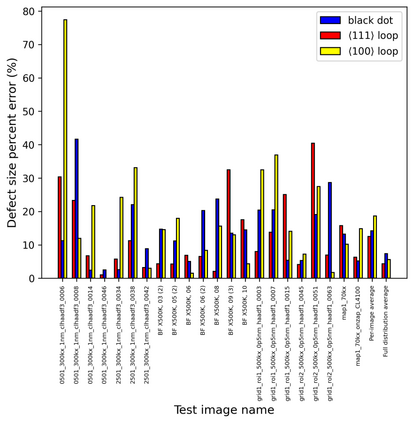
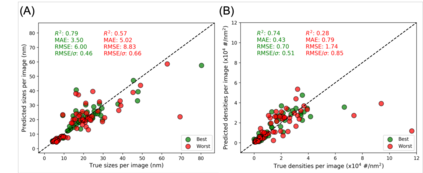
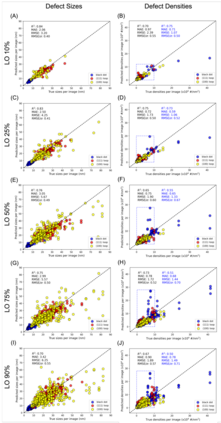
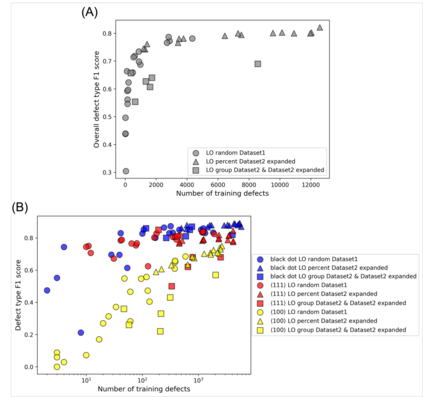
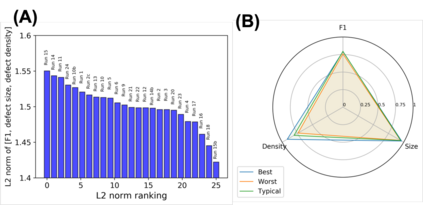
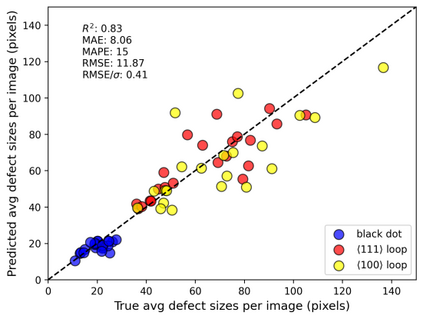
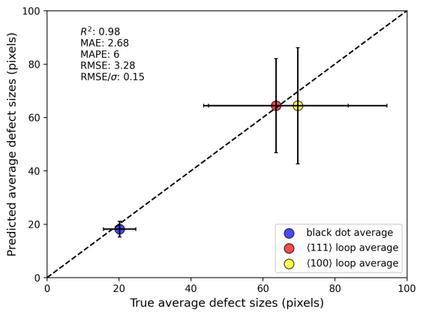
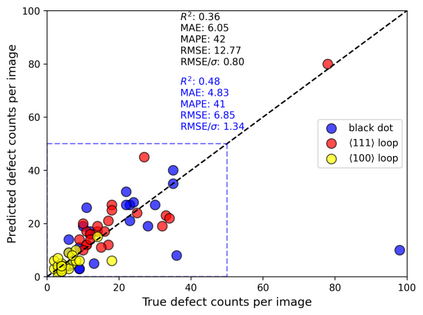
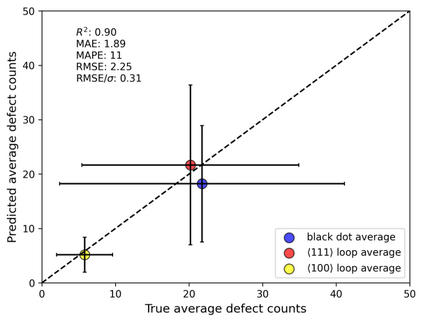
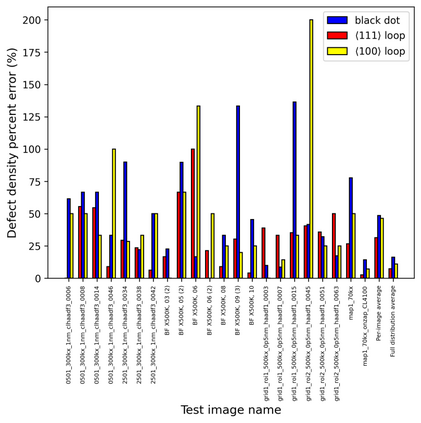
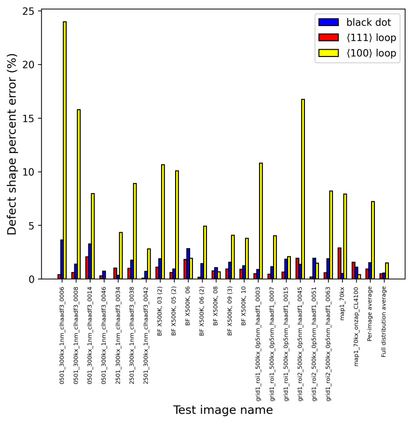
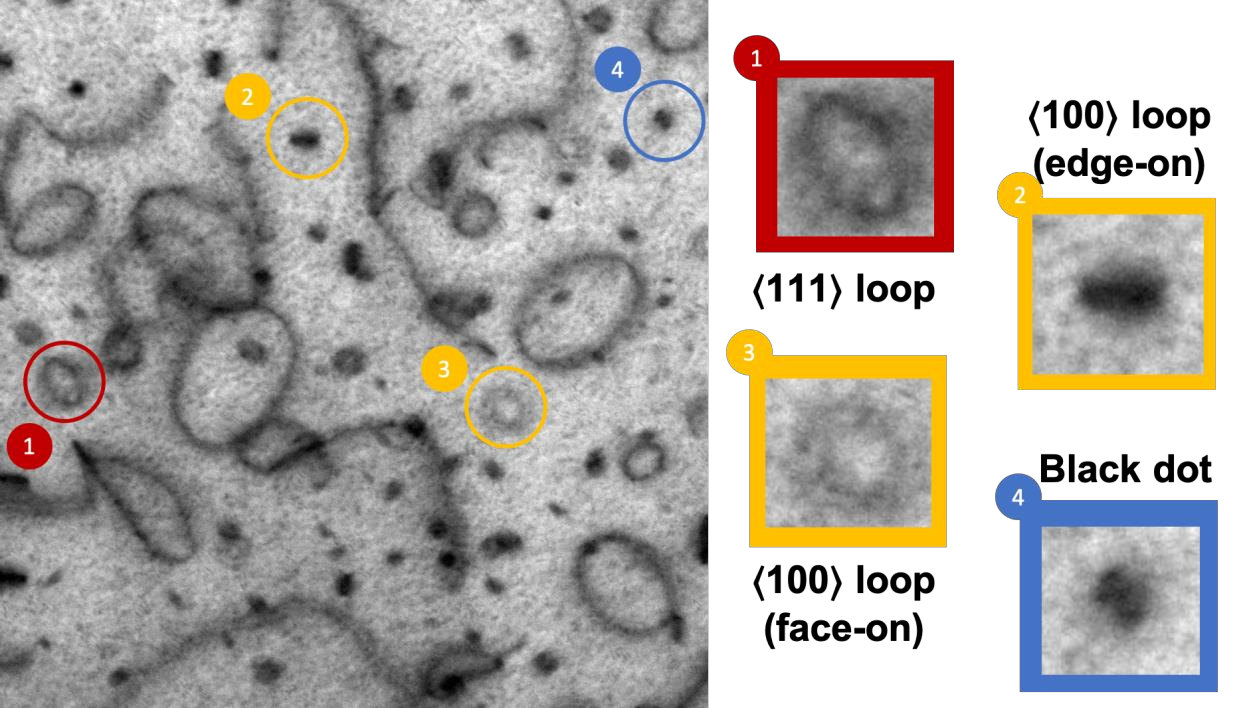
In this work, we perform semantic segmentation of multiple defect types in electron microscopy images of irradiated FeCrAl alloys using a deep learning Mask Regional Convolutional Neural Network (Mask R-CNN) model. We conduct an in-depth analysis of key model performance statistics, with a focus on quantities such as predicted distributions of defect shapes, defect sizes, and defect areal densities relevant to informing modeling and understanding of irradiated Fe-based materials properties. To better understand the performance and present limitations of the model, we provide examples of useful evaluation tests which include a suite of random splits, and dataset size-dependent and domain-targeted cross validation tests. Overall, we find that the current model is a fast, effective tool for automatically characterizing and quantifying multiple defect types in microscopy images, with a level of accuracy on par with human domain expert labelers. More specifically, the model can achieve average defect identification F1 scores as high as 0.8, and, based on random cross validation, have low overall average (+/- standard deviation) defect size and density percentage errors of 7.3 (+/- 3.8)% and 12.7 (+/- 5.3)%, respectively. Further, our model predicts the expected material hardening to within 10-20 MPa (about 10% of total hardening), which is about the same error level as experiments. Our targeted evaluation tests also suggest the best path toward improving future models is not expanding existing databases with more labeled images but instead data additions that target weak points of the model domain, such as images from different microscopes, imaging conditions, irradiation environments, and alloy types. Finally, we discuss the first phase of an effort to provide an easy-to-use, open-source object detection tool to the broader community for identifying defects in new images.
翻译:在这项工作中,我们使用深深学习的Mask 区域革命神经网络(Mask R-CNN) 模型,在电子显微显微镜中,对经过辐照的FeCrAl Alonoy 的图像中的多种缺陷类型进行语解分解。我们利用深深学习的Mask 区域革命神经网络(Mask R-CNN)模型,对关键模型性效统计进行深入分析,重点是诸如缺陷形状的预测分布、缺陷大小和缺陷等数量,与提供辐照的Fe-Fa-基于材料属性属性的建模和理解信息相关的信息。为了更好地了解模型的性能和当前目标的弱点,我们提供了一些有用的评价测试实例,其中包括一套随机拆分的图像,以及一套基于数据系统的随机交叉验证,包括一套基于数据偏差的、基于数据偏差的、基于数据偏差的图像,包括一组随机分解的、基于数据偏差的、基于数据偏差的图像,以及基于具体目标的(+-20标准偏差的) 面向目标的图像,以及基于目标的图像、基于目标值大小和直径解的图像的图像,一个预估值,以及(+/3.8) 7-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx