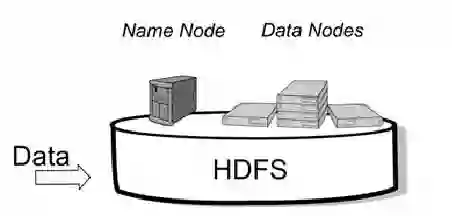
Large organizations are seeking to create new architectures and scalable platforms to effectively handle data management challenges due to the explosive nature of data rarely seen in the past. These data management challenges are largely posed by the availability of streaming data at high velocity from various sources in multiple formats. The changes in data paradigm have led to the emergence of new data analytics and management architecture. This paper focuses on storing high volume, velocity and variety data in the raw formats in a data storage architecture called a data lake. First, we present our study on the limitations of traditional data warehouses in handling recent changes in data paradigms. We discuss and compare different open source and commercial platforms that can be used to develop a data lake. We then describe our end-to-end data lake design and implementation approach using the Hadoop Distributed File System (HDFS) on the Hadoop Data Platform (HDP). Finally, we present a real-world data lake development use case for data stream ingestion, staging, and multilevel streaming analytics which combines structured and unstructured data. This study can serve as a guide for individuals or organizations planning to implement a data lake solution for their use cases.
翻译:大型组织正在寻求建立新的结构和可扩展平台,以便有效地处理由于过去很少看到的数据爆炸性造成的数据管理挑战。这些数据管理挑战主要来自各种来源以多种格式提供的高速流数据。数据范式的变化导致了新的数据分析和管理结构的出现。本文侧重于在数据储存结构中以原始格式储存大量、速度和种类的数据。首先,我们介绍了关于传统数据仓库在处理数据模式最近变化时的局限性的研究。我们讨论并比较了可用于开发数据湖的不同开放源和商业平台。然后,我们描述了我们利用Hadoop分配文件系统(HDFS)在Hadoop数据平台上进行的端对端数据湖设计和实施方法。最后,我们介绍了数据流摄入、中位和多层流分析案例,这些案例将结构化和无结构化数据组合在一起。本研究可以指导计划使用数据湖解决方案使用案例的个人或组织。