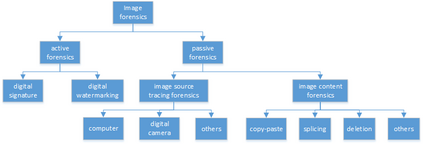
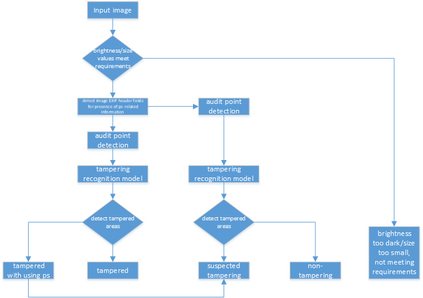
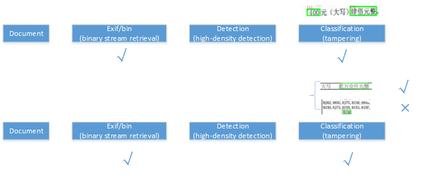
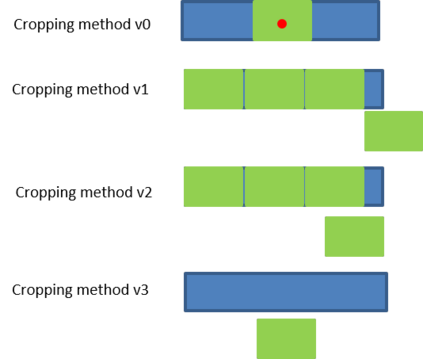
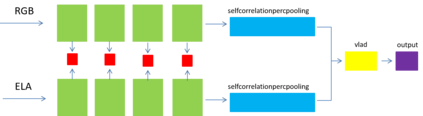
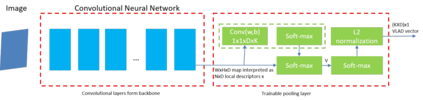
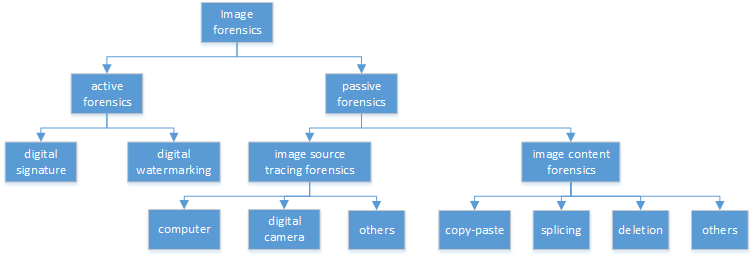
Document tamper detection has always been an important aspect of tamper detection. Before the advent of deep learning, document tamper detection was difficult. We have made some explorations in the field of text tamper detection based on deep learning. Our Ps tamper detection method includes three steps: feature assistance, audit point positioning, and tamper recognition. It involves hierarchical filtering and graded output (tampered/suspected tampered/untampered). By combining artificial tamper data features, we simulate and augment data samples in various scenarios (cropping with noise addition/replacement, single character/space replacement, smearing/splicing, brightness/contrast adjustment, etc.). The auxiliary features include exif/binary stream keyword retrieval/noise, which are used for branch detection based on the results. Audit point positioning uses detection frameworks and controls thresholds for high and low density detection. Tamper recognition employs a dual-path dual-stream recognition network, with RGB and ELA stream feature extraction. After dimensionality reduction through self-correlation percentile pooling, the fused output is processed through vlad, yielding an accuracy of 0.804, recall of 0.659, and precision of 0.913.
翻译:暂无翻译