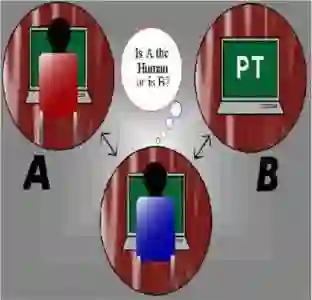
This paper critically examines the recent publication "ChatGPT-4 in the Turing Test" by Restrepo Echavarría (2025), challenging its central claims regarding the absence of minimally serious test implementations and the conclusion that ChatGPT-4 fails the Turing Test. The analysis reveals that the criticisms based on rigid criteria and limited experimental data are not fully justified. More importantly, the paper makes several constructive contributions that enrich our understanding of Turing Test implementations. It demonstrates that two distinct formats, the three-player and two-player tests, are both valid, each with unique methodological implications. The work distinguishes between absolute criteria for passing the test--the machine's probability of incorrect identification equals or exceeds the human's probability of correct identification--and relative criteria--which measure how closely a machine's performance approximates that of a human--, offering a more nuanced evaluation framework. Furthermore, the paper clarifies the probabilistic underpinnings of both test types by modeling them as Bernoulli experiments--correlated in the three-player version and uncorrelated in the two-player version. This formalization allows for a rigorous separation between the theoretical criteria for passing the test, defined in probabilistic terms, and the experimental data that require robust statistical methods for proper interpretation. In doing so, the paper not only refutes key aspects of the criticized study but also lays a solid foundation for future research on objective measures of how closely an AI's behavior aligns with, or deviates from, that of a human being.
翻译:本文对Restrepo Echavarría(2025)近期发表的《ChatGPT-4在图灵测试中的表现》进行了批判性审视,对其关于缺乏最低限度严谨测试实施方案的核心主张以及ChatGPT-4未通过图灵测试的结论提出质疑。分析表明,基于僵化标准和有限实验数据的批评并不完全合理。更重要的是,本文通过多项建设性贡献深化了我们对图灵测试实施的理解:论证了三参与者与双参与者两种测试形式均具有效性,各自具有独特的方法论意义;区分了通过测试的绝对标准(机器被错误识别的概率≥人类被正确识别的概率)与相对标准(衡量机器表现接近人类表现的程度),提供了更精细的评估框架。此外,通过将两类测试建模为伯努利实验(三参与者版本存在相关性,双参与者版本无相关性),本文阐明了两种测试类型的概率基础。这种形式化方法实现了以概率术语定义的测试通过理论标准与需要稳健统计方法进行合理解读的实验数据之间的严格分离。由此,本文不仅驳斥了被批评研究的关键观点,更为未来研究人工智能行为与人类行为的趋同度或偏离度的客观测量奠定了坚实基础。