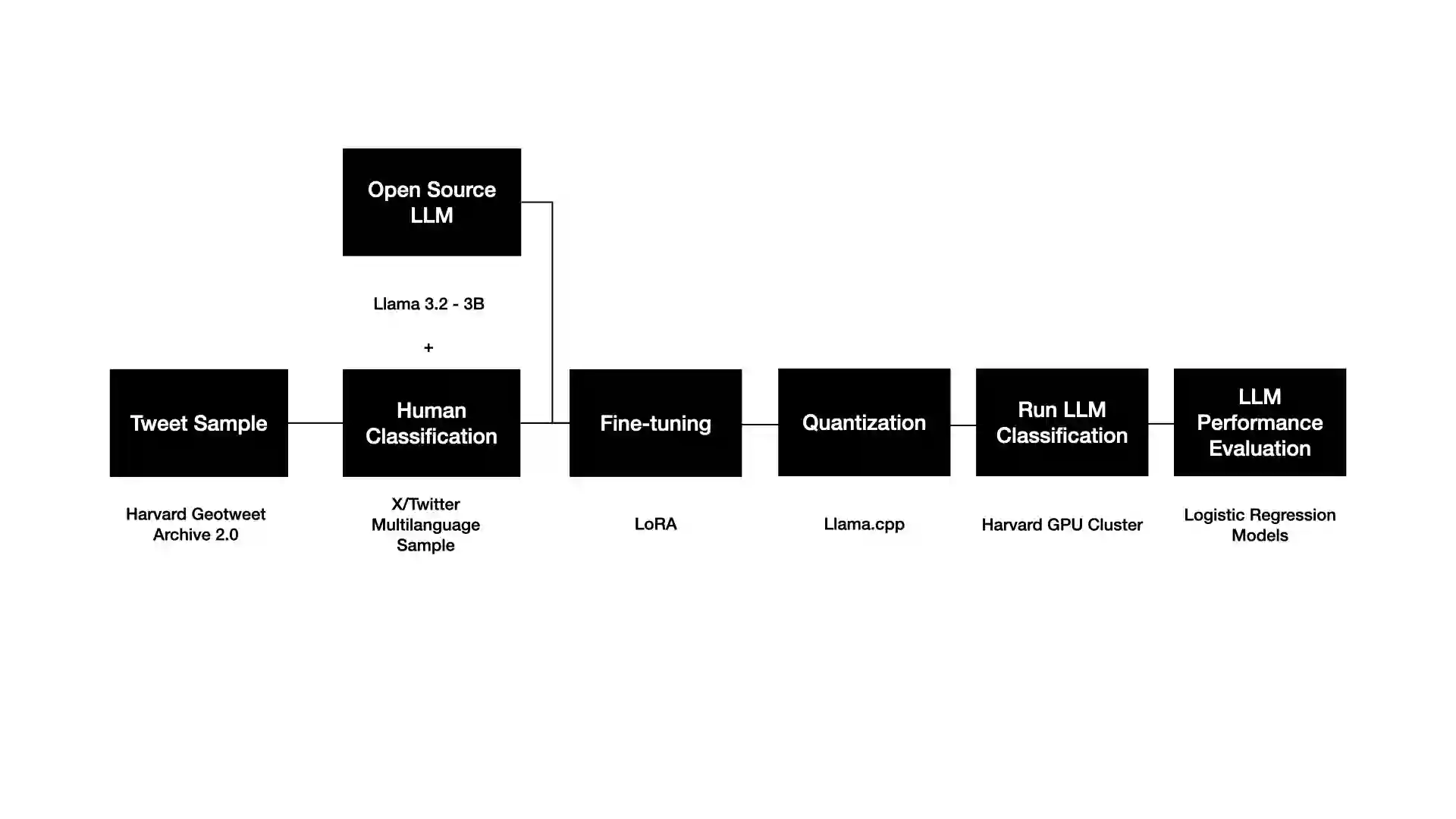
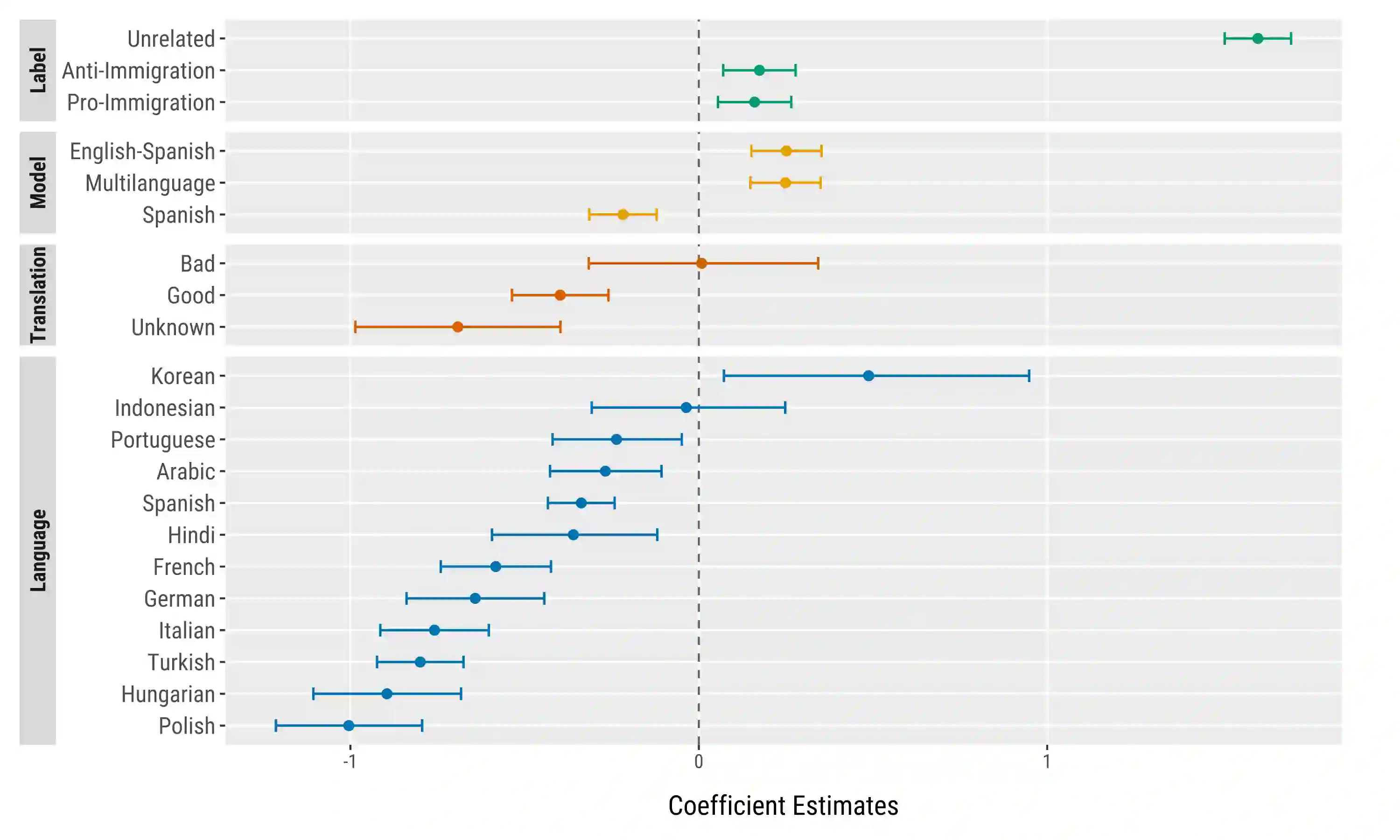
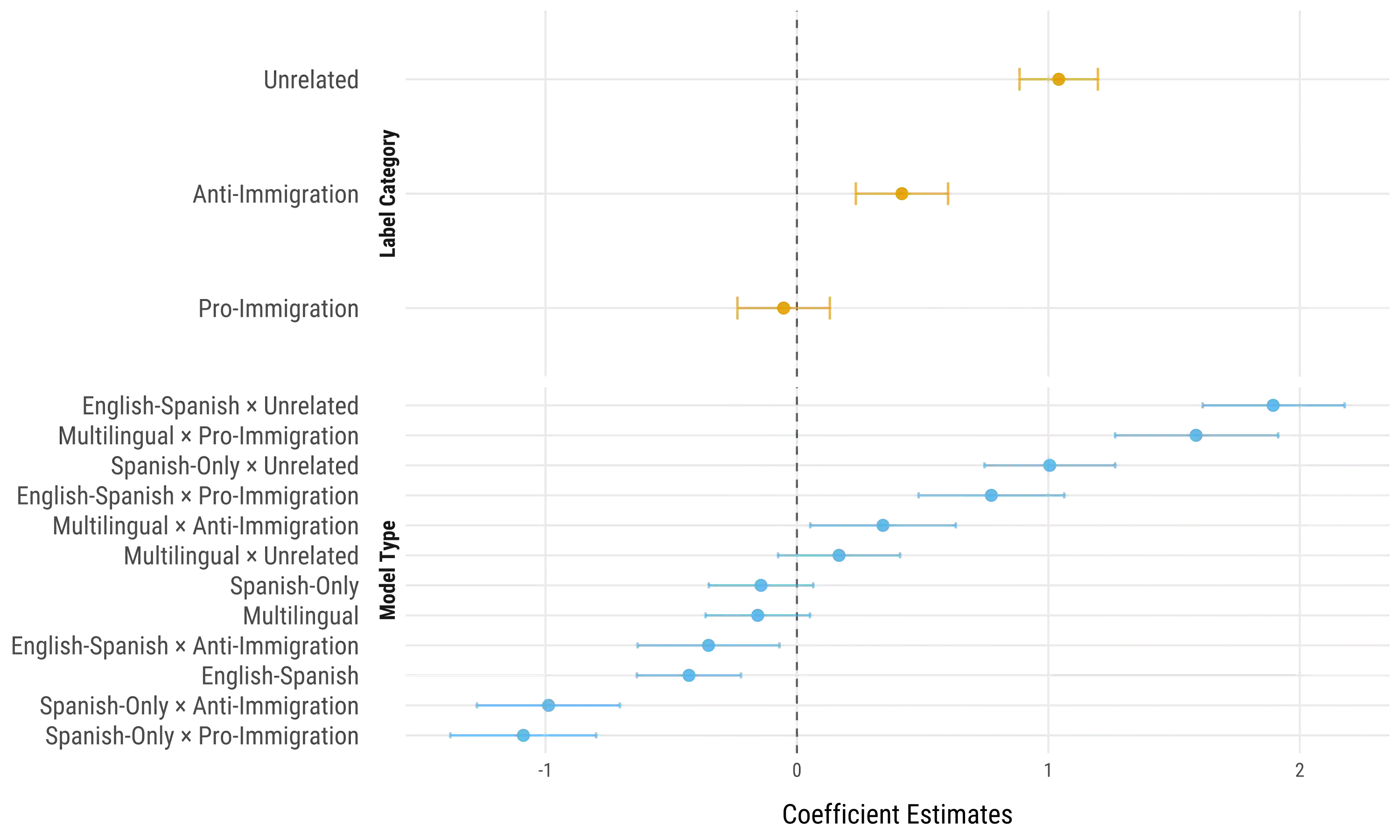
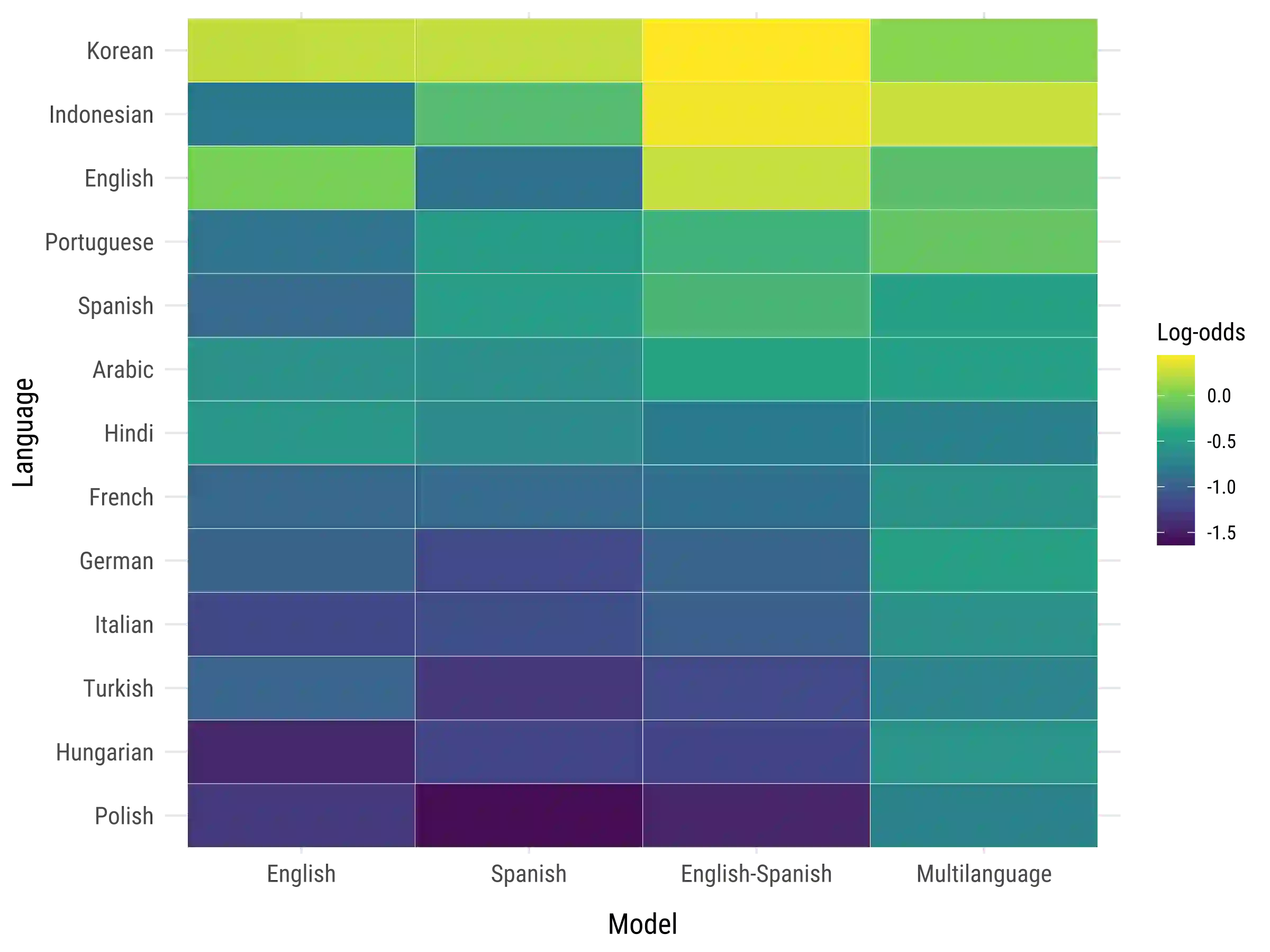
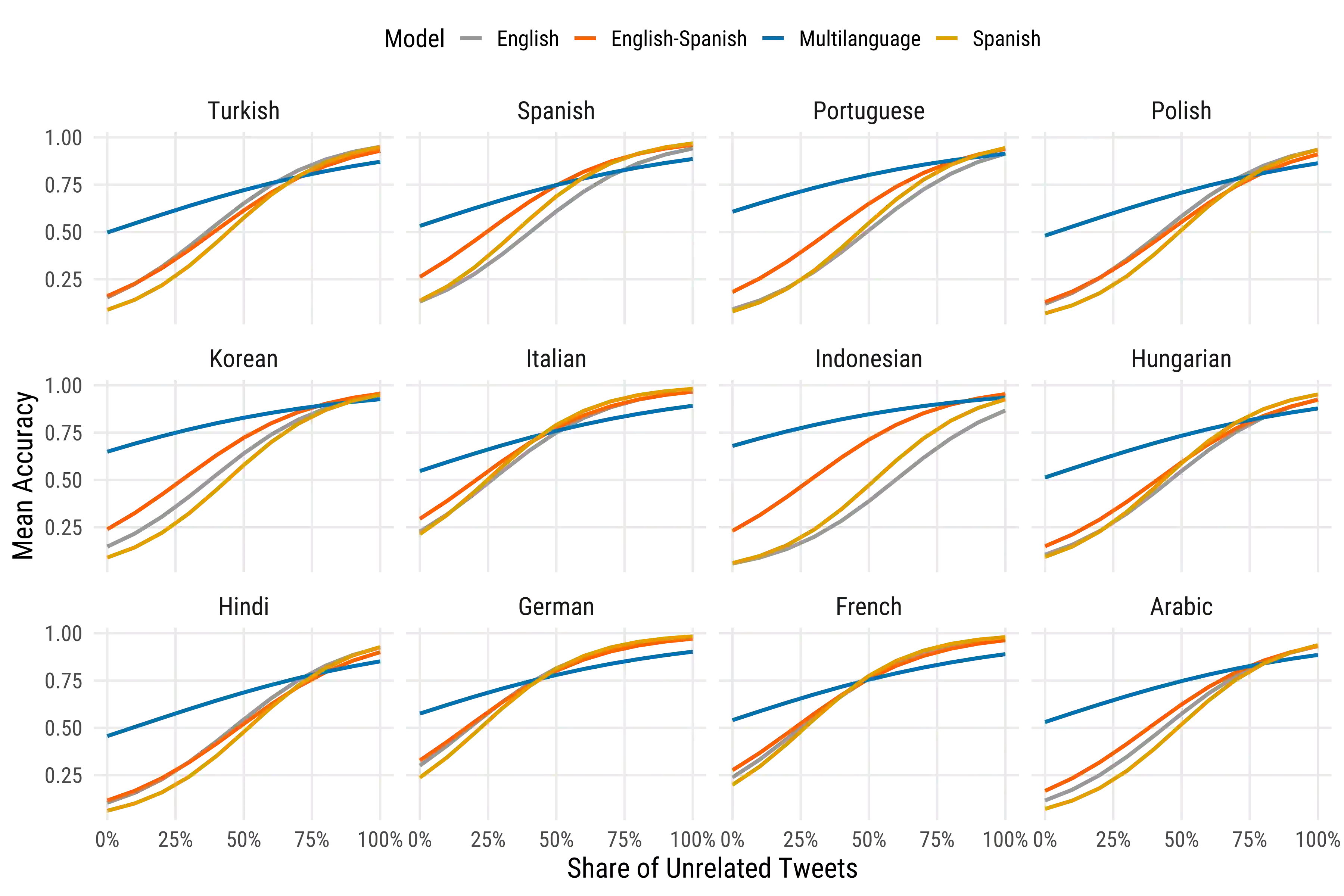
Large language models (LLMs) offer new opportunities for scalable analysis of online discourse. Yet their use in multilingual social science research remains constrained by model size, cost and linguistic bias. We develop a lightweight, open-source LLM framework using fine-tuned LLaMA 3.2-3B models to classify immigration-related tweets across 13 languages. Unlike prior work relying on BERT style models or translation pipelines, we combine topic classification with stance detection and demonstrate that LLMs fine-tuned in just one or two languages can generalize topic understanding to unseen languages. Capturing ideological nuance, however, benefits from multilingual fine-tuning. Our approach corrects pretraining biases with minimal data from under-represented languages and avoids reliance on proprietary systems. With 26-168x faster inference and over 1000x cost savings compared to commercial LLMs, our method supports real-time analysis of billions of tweets. This scale-first framework enables inclusive, reproducible research on public attitudes across linguistic and cultural contexts.
翻译:大语言模型为在线话语的可扩展分析提供了新的机遇。然而,其在多语言社会科学研究中的应用仍受限于模型规模、成本及语言偏见。本研究开发了一个轻量级、开源的大语言模型框架,使用微调的LLaMA 3.2-3B模型对13种语言的移民相关推文进行分类。与以往依赖BERT类模型或翻译流水线的研究不同,我们将主题分类与立场检测相结合,并证明仅在一两种语言上微调的大语言模型能够将主题理解泛化至未见语言。然而,捕捉意识形态的细微差别仍需多语言微调。我们的方法通过使用少量代表性不足语言的数据来校正预训练偏差,并避免依赖专有系统。相较于商用大语言模型,本方法实现了26-168倍的推理速度提升和超过1000倍的成本节约,支持对数十亿推文进行实时分析。这一以规模优先的框架为跨语言和文化背景的公众态度研究提供了包容且可复现的途径。