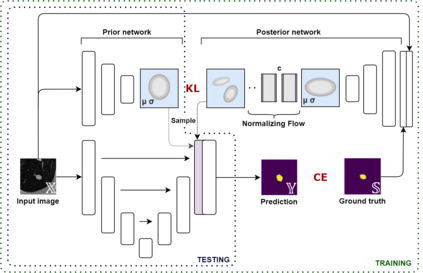
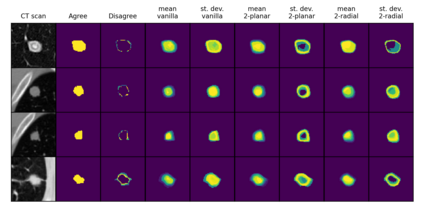
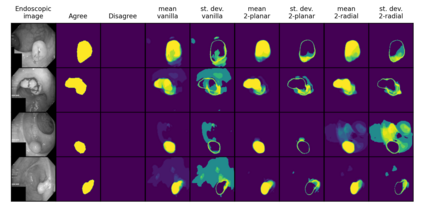
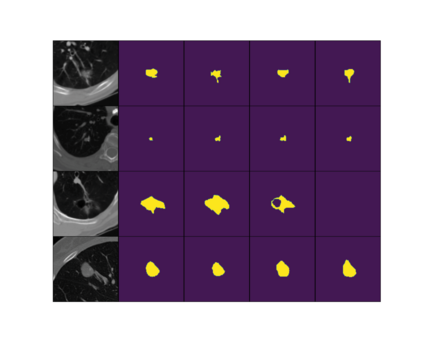
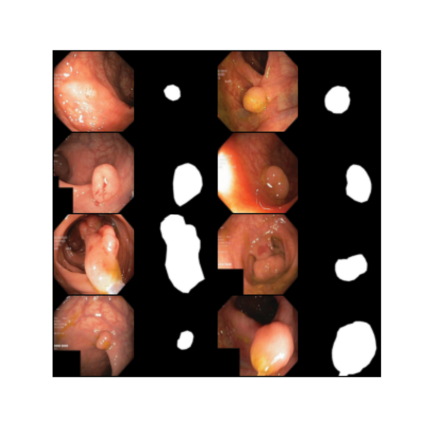
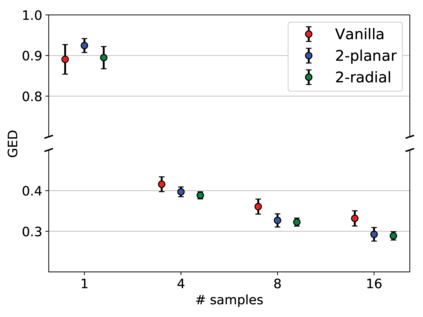
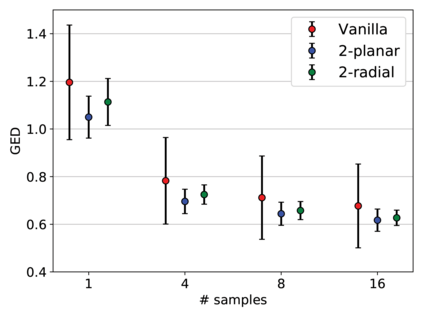
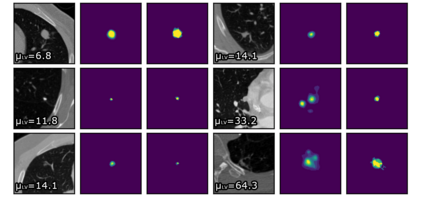
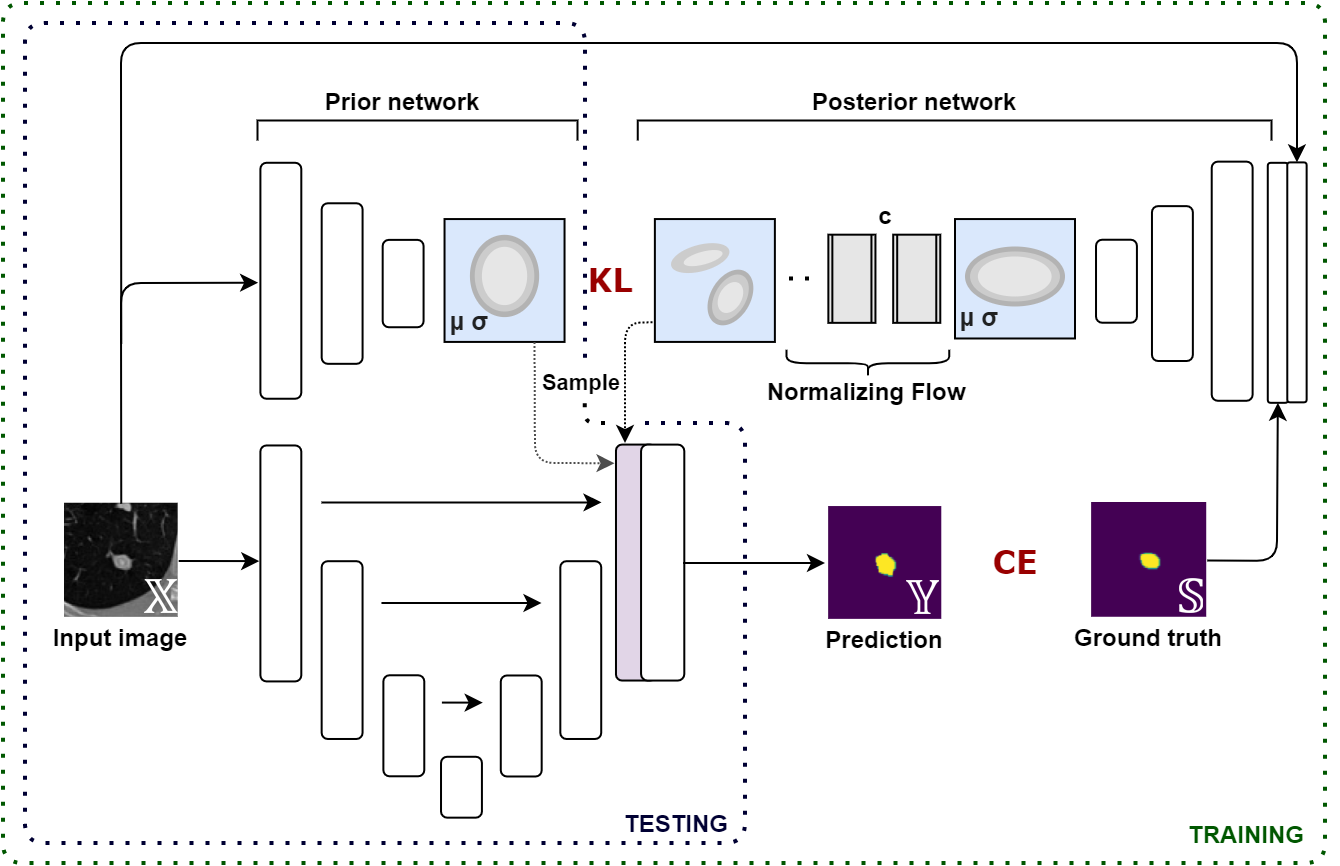
Quantifying uncertainty in medical image segmentation applications is essential, as it is often connected to vital decision-making. Compelling attempts have been made in quantifying the uncertainty in image segmentation architectures, e.g. to learn a density segmentation model conditioned on the input image. Typical work in this field restricts these learnt densities to be strictly Gaussian. In this paper, we propose to use a more flexible approach by introducing Normalizing Flows (NFs), which enables the learnt densities to be more complex and facilitate more accurate modeling for uncertainty. We prove this hypothesis by adopting the Probabilistic U-Net and augmenting the posterior density with an NF, allowing it to be more expressive. Our qualitative as well as quantitative (GED and IoU) evaluations on the multi-annotated and single-annotated LIDC-IDRI and Kvasir-SEG segmentation datasets, respectively, show a clear improvement. This is mostly apparent in the quantification of aleatoric uncertainty and the increased predictive performance of up to 14 percent. This result strongly indicates that a more flexible density model should be seriously considered in architectures that attempt to capture segmentation ambiguity through density modeling. The benefit of this improved modeling will increase human confidence in annotation and segmentation, and enable eager adoption of the technology in practice.
翻译:量化医学图像分解应用中的不确定性至关重要,因为这往往与重要的决策相关。在量化图像分解结构的不确定性方面已经做出了令人信服的尝试,例如学习以输入图像为条件的密度分解模型。该领域的典型工作限制这些所学的密度,严格限于高斯语。在本文件中,我们提议采用更灵活的方法,引入标准化流程(NFs),使所学的密度更加复杂,便于为不确定性建立更准确的模型。我们通过采用概率U-Net和以NF增加后方密度,从而能够更清晰地表达,从而证明了这一假设。我们在这一领域的典型工作限制了这些所学得来的密度,严格地将LIDC-IDRI和Kvasir-SEG)分别对多注和单注LIDC-IDRI和Kvasir-SEG分解数据集进行了定性和定量评估。我们建议采用更灵活的方法,使所学得的密度更加复杂,这在测测测测不确定性和预测性达到14%方面最为明显。这有力地表明,在采用这一模型的过程中,将尝试采用更灵活的密度分解方法将提高人类密度模型的难度。