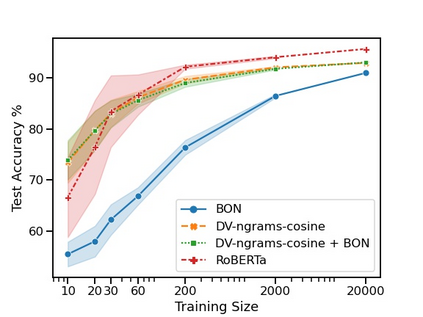
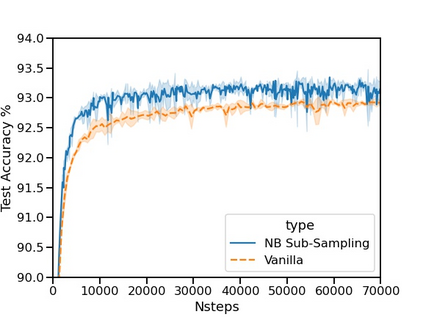
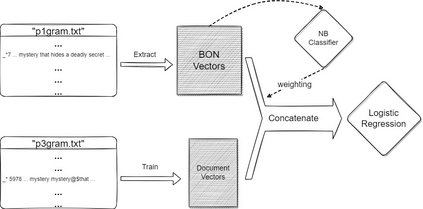
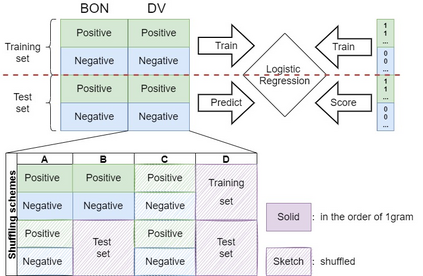
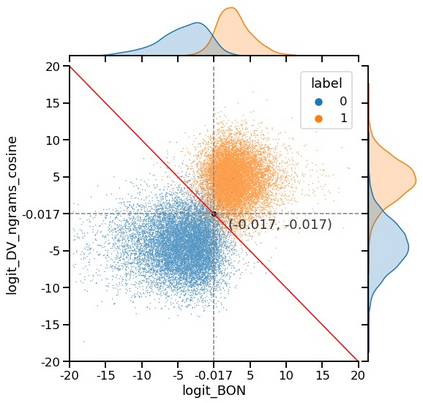
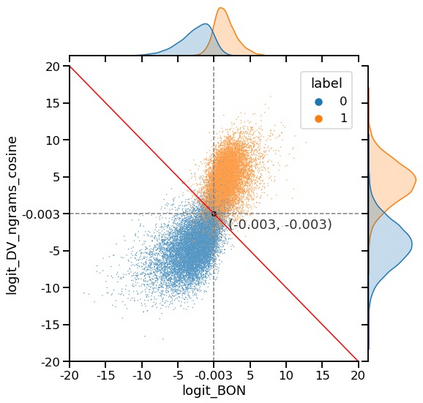
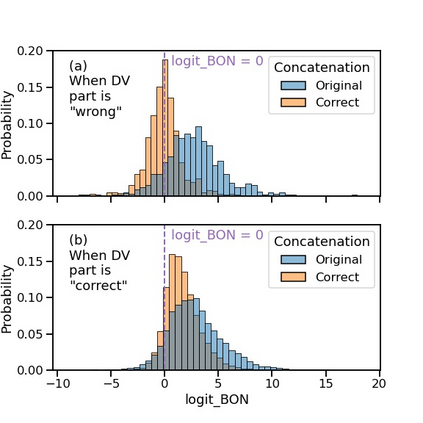
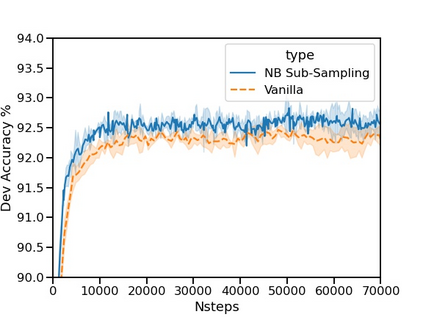
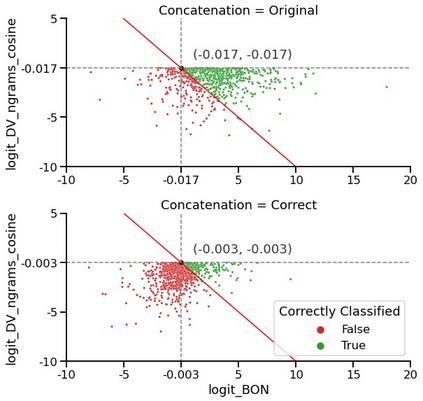
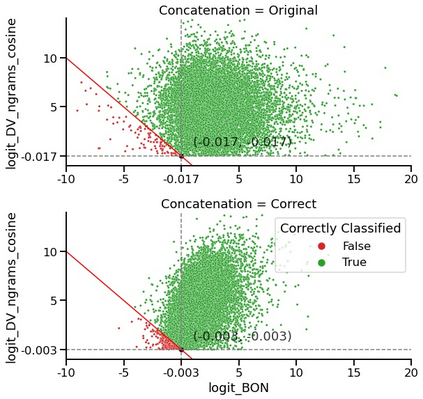
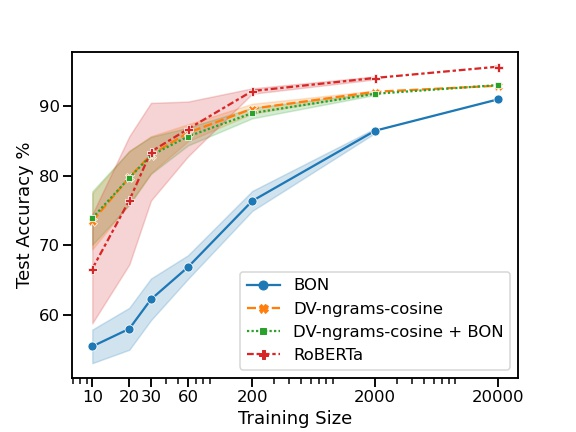
The current state-of-the-art test accuracy (97.42\%) on the IMDB movie reviews dataset was reported by \citet{thongtan-phienthrakul-2019-sentiment} and achieved by the logistic regression classifier trained on the Document Vectors using Cosine Similarity (DV-ngrams-cosine) proposed in their paper and the Bag-of-N-grams (BON) vectors scaled by Naive Bayesian weights. While large pre-trained Transformer-based models have shown SOTA results across many datasets and tasks, the aforementioned model has not been surpassed by them, despite being much simpler and pre-trained on the IMDB dataset only. In this paper, we describe an error in the evaluation procedure of this model, which was found when we were trying to analyze its excellent performance on the IMDB dataset. We further show that the previously reported test accuracy of 97.42\% is invalid and should be corrected to 93.68\%. We also analyze the model performance with different amounts of training data (subsets of the IMDB dataset) and compare it to the Transformer-based RoBERTa model. The results show that while RoBERTa has a clear advantage for larger training sets, the DV-ngrams-cosine performs better than RoBERTa when the labelled training set is very small (10 or 20 documents). Finally, we introduce a sub-sampling scheme based on Naive Bayesian weights for the training process of the DV-ngrams-cosine, which leads to faster training and better quality.
翻译:在IMDB电影审查数据集中,目前最先进的测试精确度(97.42 ⁇ )是由\ citet{thongtan-phimenthrakul-2019-smintiment} 报告的,并且是由在使用Cosine相似度(DV-ngrams-cosine)文档矢量(DV-ngramsine)的文档矢量(DV-ngramsine)上培训的后勤回归分析师在他们的论文中和由Naive Bayesian 重量缩放的Bag-Ngram(BON) 的矢量。虽然在经过培训的大型变压器模型中显示的是许多数据集和任务中SOTA的结果,但上述模型并没有被它们超过,尽管只是在IMDB数据集上经过简单化和预先训练。我们试图分析它在IMDBR-BA的测试模型中的出色性能时(ROBBBB的分数),我们还要分析模型的性能和RBAR的更佳的RBA-G-LA-LA-LAD的成绩。