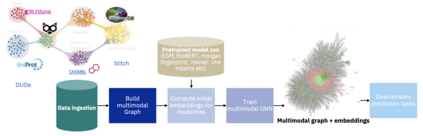
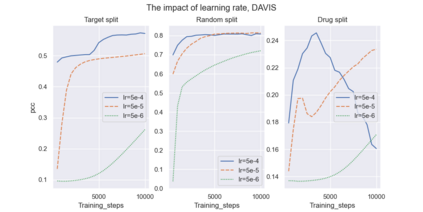
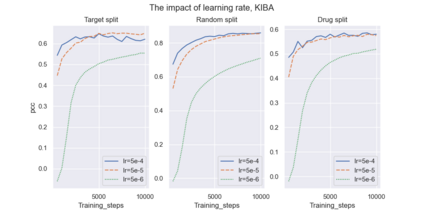
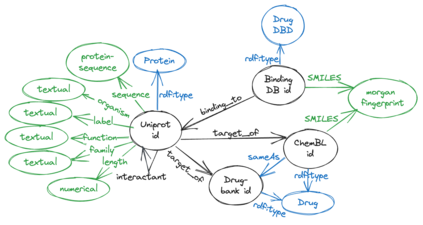
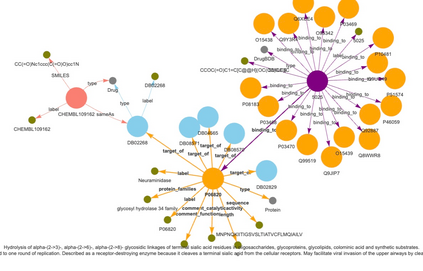
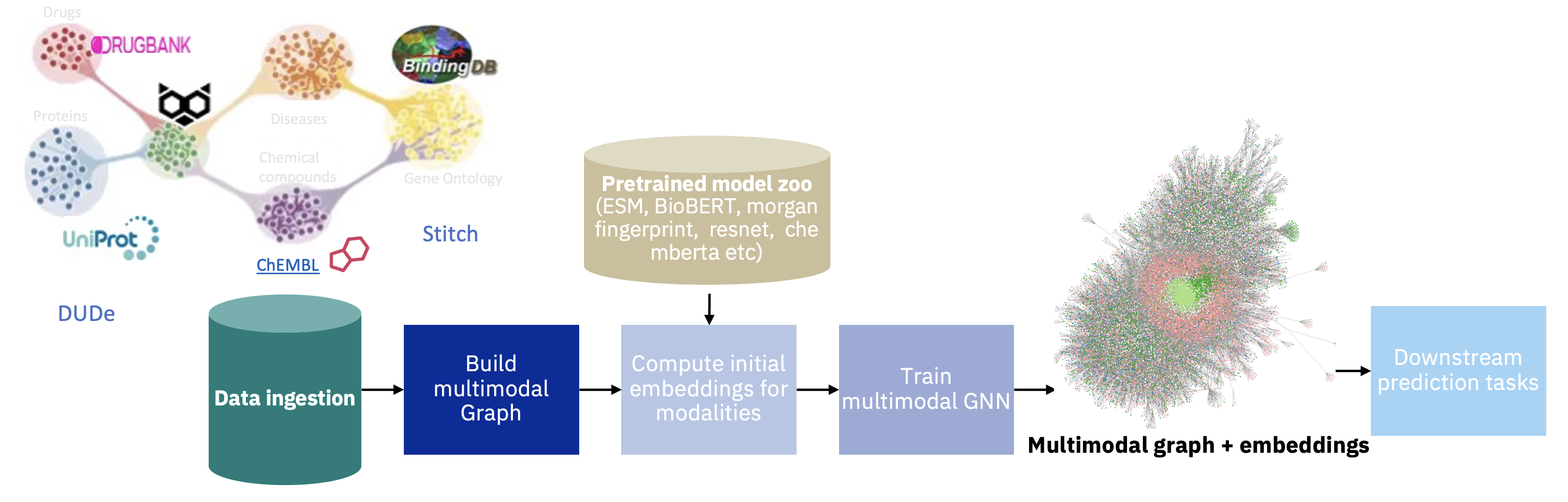
Recent research in representation learning utilizes large databases of proteins or molecules to acquire knowledge of drug and protein structures through unsupervised learning techniques. These pre-trained representations have proven to significantly enhance the accuracy of subsequent tasks, such as predicting the affinity between drugs and target proteins. In this study, we demonstrate that by incorporating knowledge graphs from diverse sources and modalities into the sequences or SMILES representation, we can further enrich the representation and achieve state-of-the-art results on established benchmark datasets. We provide preprocessed and integrated data obtained from 7 public sources, which encompass over 30M triples. Additionally, we make available the pre-trained models based on this data, along with the reported outcomes of their performance on three widely-used benchmark datasets for drug-target binding affinity prediction found in the Therapeutic Data Commons (TDC) benchmarks. Additionally, we make the source code for training models on benchmark datasets publicly available. Our objective in releasing these pre-trained models, accompanied by clean data for model pretraining and benchmark results, is to encourage research in knowledge-enhanced representation learning.
翻译:暂无翻译