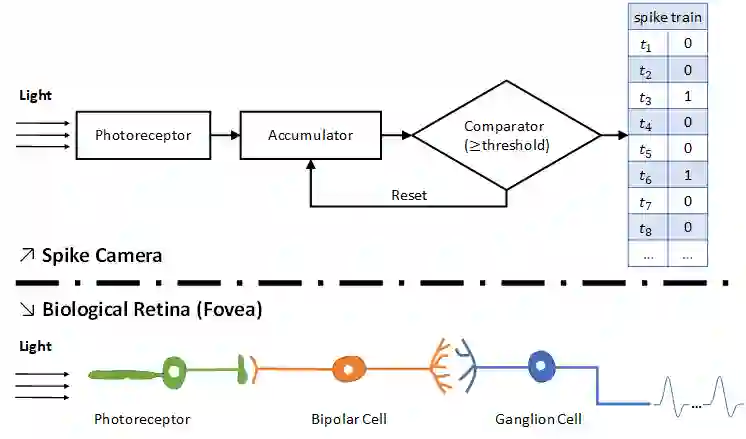
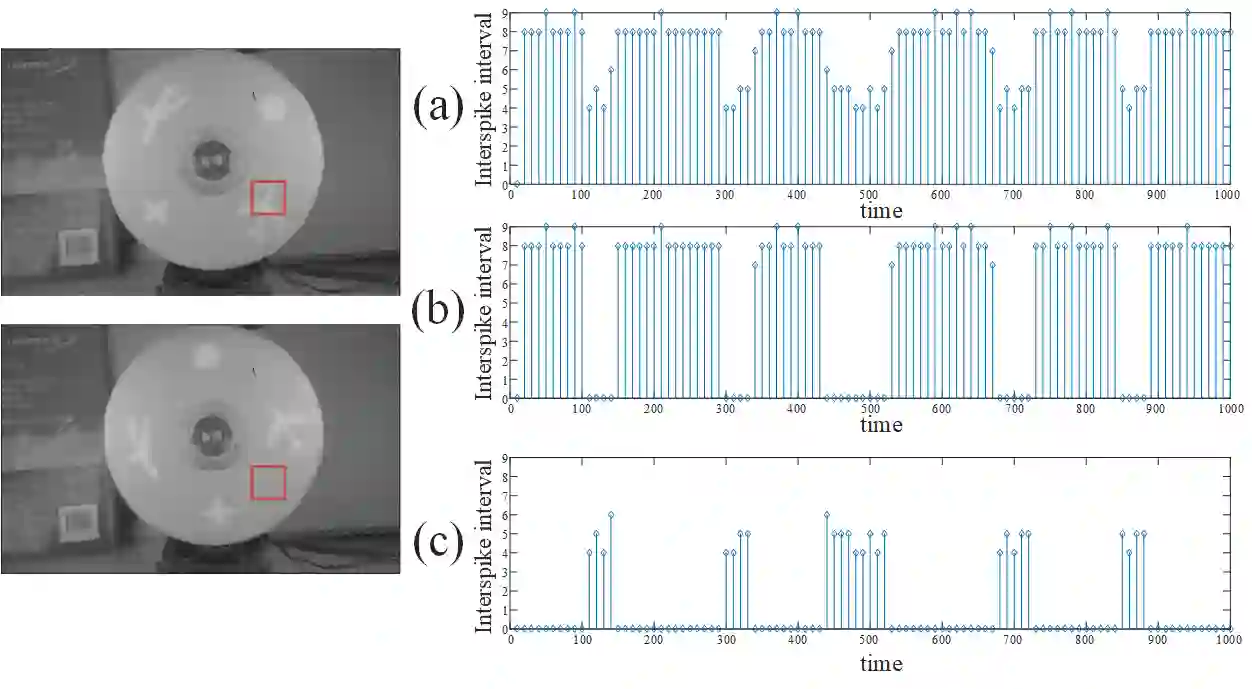
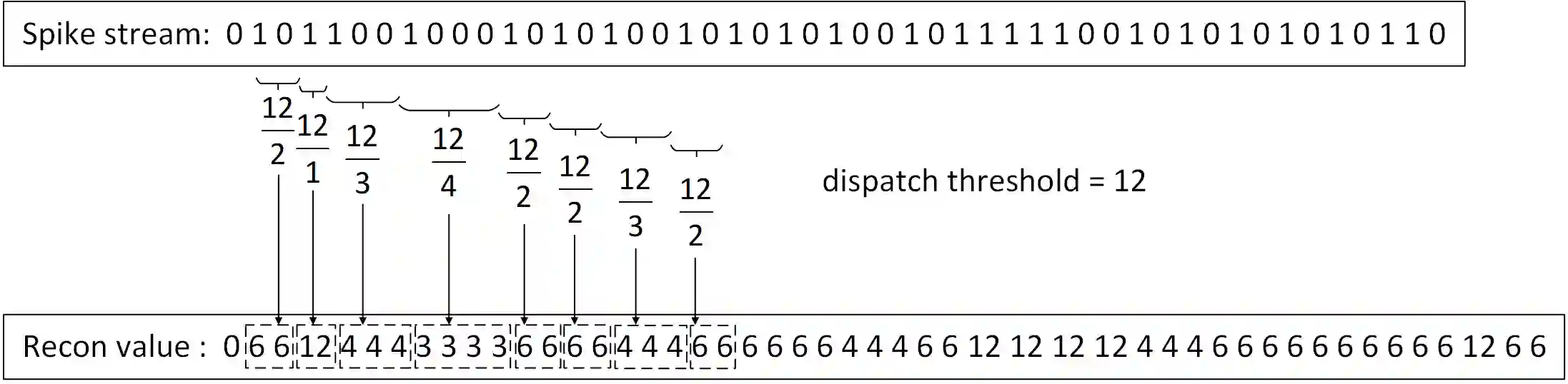
Conventional frame-based camera is not able to meet the demand of rapid reaction for real-time applications, while the emerging dynamic vision sensor (DVS) can realize high speed capturing for moving objects. However, to achieve visual texture reconstruction, DVS need extra information apart from the output spikes. This paper introduces a fovea-like sampling method inspired by the neuron signal processing in retina, which aims at visual texture reconstruction only taking advantage of the properties of spikes. In the proposed method, the pixels independently respond to the luminance changes with temporal asynchronous spikes. Analyzing the arrivals of spikes makes it possible to restore the luminance information, enabling reconstructing the natural scene for visualization. Three decoding methods of spike stream for texture reconstruction are proposed for high-speed motion and stationary scenes. Compared to conventional frame-based camera and DVS, our model can achieve better image quality and higher flexibility, which is capable of changing the way that demanding machine vision applications are built.
翻译:常规框架相机无法满足实时应用的快速反应需求,而新兴动态视觉传感器(DVS)可以实现移动物体的高速捕捉。然而,为了实现视觉质地重建,DVS需要除输出峰值外的额外信息。本文介绍了由视网膜神经信号处理所启发的类似微小的取样方法,该方法的目的只是利用钉子的特性进行视觉质地重建。在拟议方法中,像素独立地用时间性不同步的钉钉子对发光的变化作出反应。分析钉子的到来使恢复发光信息成为可能,从而能够重建自然场景以便视觉化。为高速运动和固定场景提出了三种用于纹质重建的钉状流解方法。与传统的基于框架的相机和DVS相比,我们的模型可以取得更好的图像质量和更高的灵活性,从而能够改变要求机器视觉应用的构建方式。