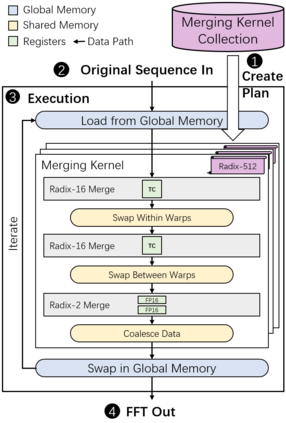
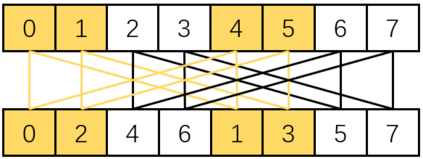
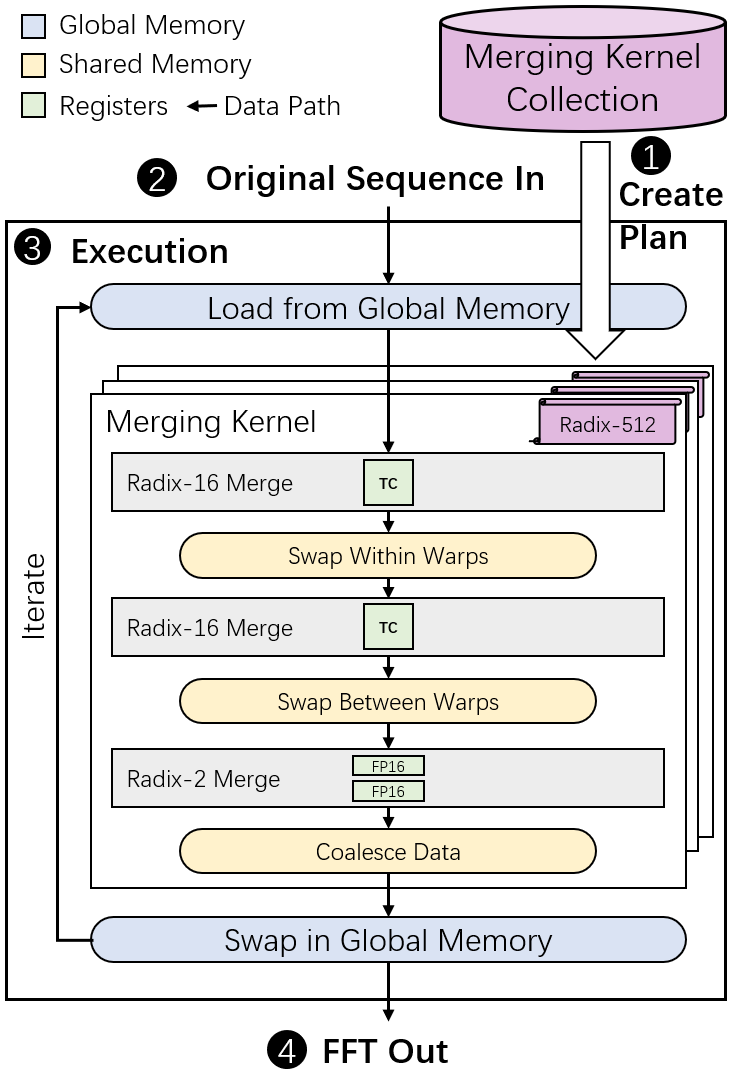
Fast Fourier Transform (FFT) is an essential tool in scientific and engineering computation. The increasing demand for mixed-precision FFT has made it possible to utilize half-precision floating-point (FP16) arithmetic for faster speed and energy saving. Specializing in lower precision, NVIDIA Tensor Cores can deliver extremely high computation performance. However, the fixed computation pattern makes it hard to utilize the computing power of Tensor Cores in FFT. Therefore, we developed tcFFT to accelerate FFT with Tensor Cores. Our tcFFT supports batched 1D and 2D FFT of various sizes and it exploits a set of optimizations to achieve high performance: 1) single-element manipulation on Tensor Core fragments to support special operations needed by FFT; 2) fine-grained data arrangement design to coordinate with the GPU memory access pattern. We evaluated our tcFFT and the NVIDIA cuFFT in various sizes and dimensions on NVIDIA V100 and A100 GPUs. The results show that our tcFFT can outperform cuFFT 1.29x-3.24x and 1.10x-3.03x on the two GPUs, respectively. Our tcFFT has a great potential for mixed-precision scientific applications.
翻译:快速傅里叶变换(FFT)是科学和工程计算中不可或缺的工具。 对混合精密化FFFT的日益增长的需求使得能够利用半精度浮点(FP16)算术加快速度和节能。 专门精度低精度的NVIDIA Tensor核心可以提供极高的计算性能。 然而,固定计算模式使得难以利用FFT中Tsor Core的计算能力。 因此,我们开发了 tcFFT, 以加速Tensor核心的FFFFT。 我们的TcFFT支持了不同大小的批量1D和2D FFT, 利用一套优化来达到高性能:1) 对Tensor核心碎片进行单元素操作,以支持FFT所需的特殊操作; 2) 微细微重数据安排设计,以协调GPU内存取模式。 我们用NVIDIA V100 和 A100 GPUS 上的不同大小和尺寸和尺寸的NVIDA 。 结果显示,我们的tcFFT 3-3 3x 2xx 2xxx 2fcex 的应用程序可以分别在1x 2.24和1x2FFFFT 3x2x2x。